 夜雨聆风
夜雨聆风





AI Agent 三国杀:Claude Code vs OpenClaw vs Hermes Agent 深度横评
2026 年,AI Agent 赛道进入「三国杀」阶段。
一边是 Anthropic 官方的编码利器 Claude Code,一边是 Peter Steinberger 搞出的多平台消息网关 OpenClaw(310K+ GitHub Stars),还有 Nous Research 推出的自学习闭环 Agent——Hermes Agent。
它们定位完全不同,但都在争夺同一个问题:AI 到底该怎么跟人协作?
本文从产品定位、记忆系统、Skill 生态、Token 消耗、执行循环五个维度,逐层拆解三者的设计哲学与技术差异。
一、产品定位:三把不同的刀
先看一张总览表:
|
|
|
|
|
| 开发者 |
|
|
|
| 本质 |
|
|
|
| 技术栈 |
|
|
|
| 开源 |
|
|
|
| 模型绑定 |
|
|
|
| 交互方式 |
|
|
|
| 设计哲学 |
|
|
|
| GitHub Stars |
|
|
|
一句话:Claude Code 写代码最强,OpenClaw 连接平台最多,Hermes Agent 是唯一能「越用越懂你」的。
二、记忆系统:从笔记卡到向量金字塔到自学习闭环
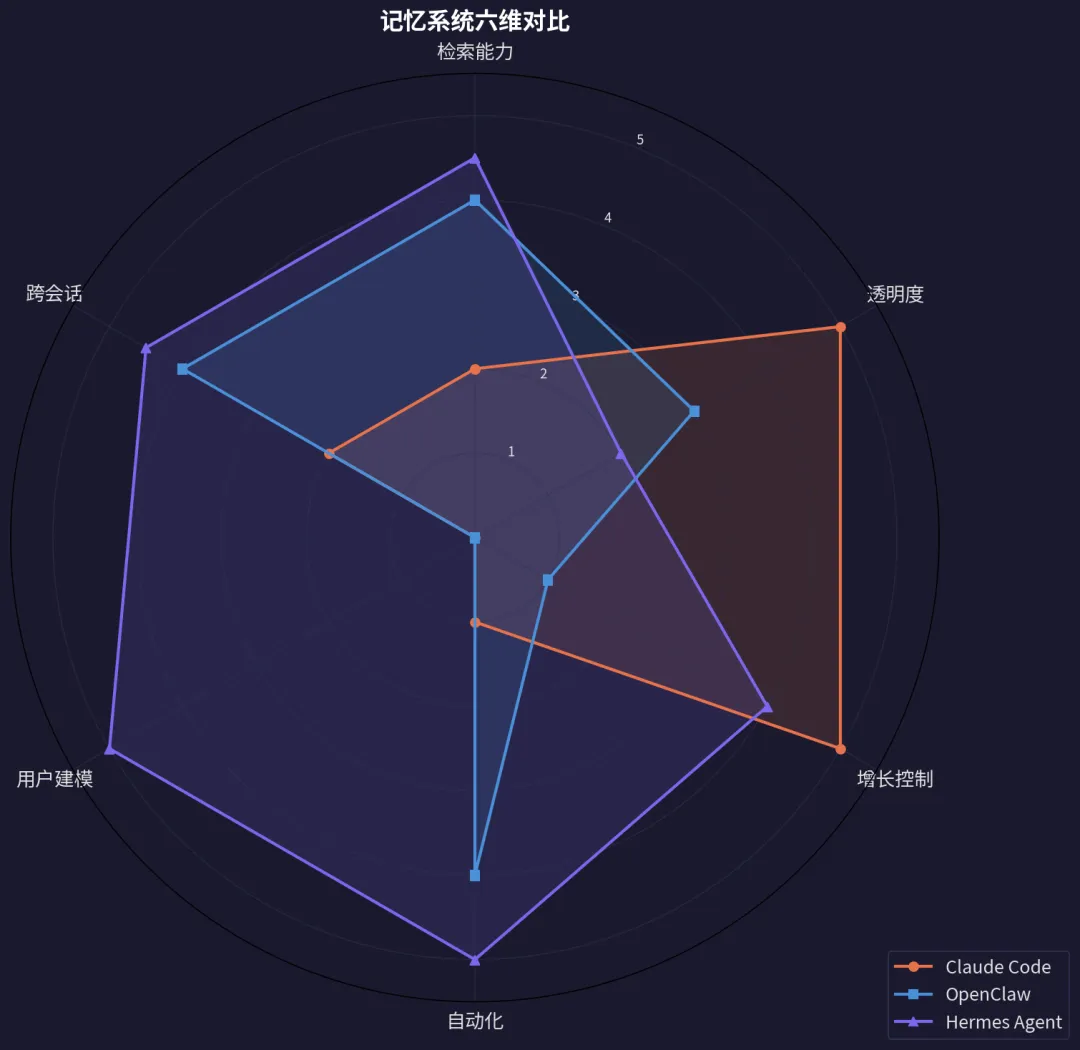
三者记忆架构差异巨大,构成一条清晰的进化线。
Claude Code — 结构化笔记卡
~/.claude/projects/<project>/memory/
├── MEMORY.md ← 索引(≤200行,始终加载)
├── user_role.md ← 单条记忆
├── feedback_xxx.md ← 单条记忆
└── project_xxx.md ← 单条记忆
工作流很简单:对话开始 → MEMORY.md[1] 加载到上下文 → 需要时 Read 单个文件 → 主动判断写入时机。
优点: 简单透明,200 行硬上限防止失控。
缺点: 无语义搜索,全靠标题浏览,Agent 自己决定什么时候记。
OpenClaw — 四层金字塔
~/.openclaw/workspace/
├── SOUL.md L1 ← 人格/语气(始终注入)
├── USER.md L2 ← 用户偏好(始终注入)
├── MEMORY.md L3 ← 长期记忆(持续膨胀!)
├── HEARTBEAT.md ← 心跳检查清单
└── AGENTS.md ← 工作区指令
~/.openclaw/memory/
└── .sqlite ← 向量索引
四层全部注入 system prompt,加上向量搜索召回历史记忆,还有心跳机制定期自检。
优点: 向量搜索能力强,心跳自检确保记忆不腐化。
缺点:MEMORY.md[2] 无自动压缩,持续膨胀带来安全和成本风险。
Hermes — 闭环自学习
~/.hermes/
├── MEMORY.md ← 继承 OpenClaw 格式
├── USER.md ← 用户偏好
├── SOUL.md ← 人格定义
└── sessions.db ← FTS5 全文索引
核心是「闭环学习」:任务完成 → 自动提炼 → 写入记忆 → FTS5 全文检索 → Honcho 用户建模 → 理解「你是谁」 → Periodic Nudge 自我提醒。
优点: 唯一有用户建模的,自动学习越用越懂你。
缺点: 黑盒度高,你不太清楚它到底学了什么、记了什么。
记忆系统核心对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三、Skill 系统:从提示词库到插件市场到自生长记忆
Claude Code — 专家提示词库
Skill = 结构化提示词(SKILL.md[3]),/skill-name 展开为完整 prompt。手动创建,无官方市场,调用时才注入,不用不花 token。
OpenClaw — 插件市场生态
三层优先级:Built-in > ClawHub > User。ClawHub 市场有 13,000+ 技能。但已安装技能始终注入 system prompt,也就是说装多了每次请求都要付固定 token 税。另外约 20% 已标记为恶意——生态大但安全风险也大。
Hermes — 自生长程序性记忆
这是三者中最独特的:解决问题后自动生成 Skill,Skill 在使用中自改进,兼容 agentskills.io[4] 开放标准,按需加载不预注入。
Skill 核心对比
|
|
|
|
|
|
|
|
|
自动 + 手动 |
|
|
|
|
是 |
|
|
|
始终注入 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
自生长程序性记忆 |

四、Token 消耗:谁最烧钱?
记忆和 Skill 对 token 消耗的影响是三者成本差异的根本原因。
每次 API 调用的 Token 构成
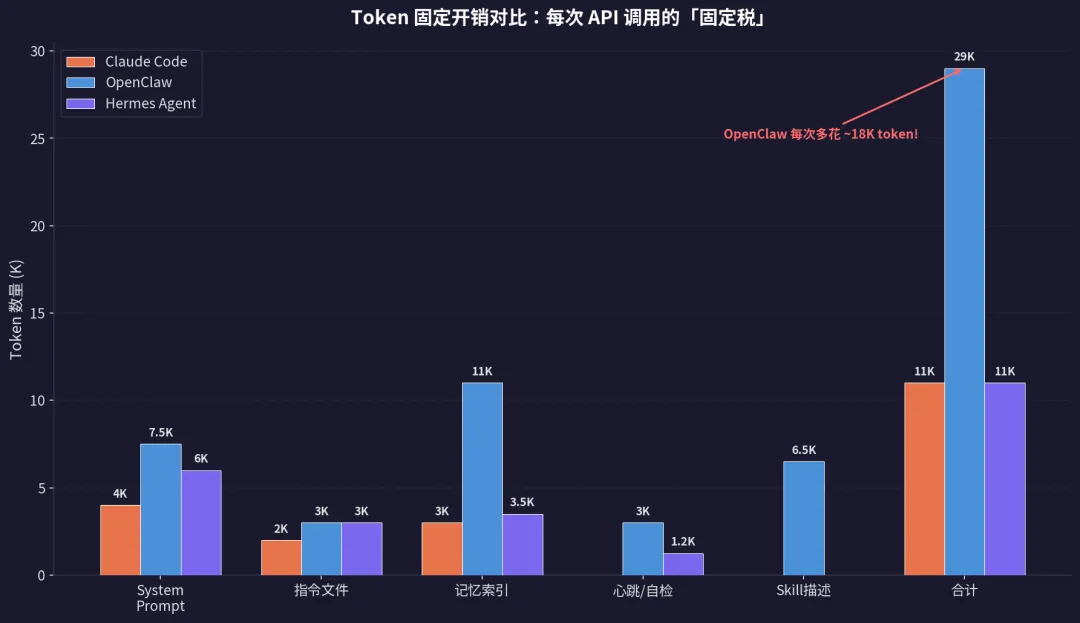
总 Token = System Prompt + 记忆注入 + Skill 注入 + 当前对话 + Tool 结果 + LLM 输出
三者的固定开销差异巨大:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2-20K |
|
|
|
|
|
|
|
|
|
3-10K+ |
|
| 始终注入合计 | ~11K (30%) | ~29K (40%) | ~11K (22%) |
核心结论:
-
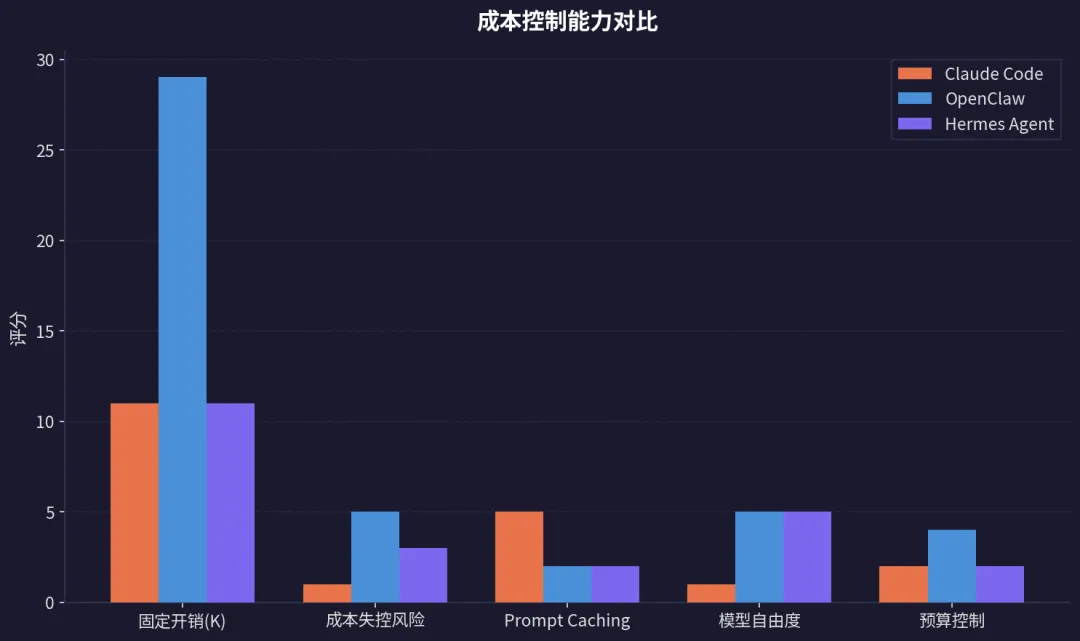
Claude Code 是「按需取用」——不用就不花 token,还有 Prompt Caching 90% 折扣
-
OpenClaw 是「全量预加载」——装了多少 Skill、记了多少事,每次请求都要付固定税,24/7 运行下成本极易失控
-
Hermes Agent 介于两者之间——按需加载 Skill + LLM 摘要压缩记忆,但自学习闭环会产生额外的「隐形 API 调用」
成本控制策略
|
|
|
|
|
|
|
|
maxCostPerDay
|
|
|
|
|
|
/model
|
|
|
原生 90% 折扣 |
|
|
|
|
|
memory index
|
|
|
|
低 | 高 |
|
五、Agent 执行循环
Claude Code:单线程编码利器
用户输入 → System Prompt → LLM 推理 → Tool 调用(Read/Write/Edit/Bash/Grep/Glob)→ 结果返回 → 继续推理 → 输出。
特点:单线程、单会话、无后台。自动压缩上下文 + Prompt Caching。
OpenClaw:多平台消息枢纽
消息平台(Telegram/Discord/微信…)→ Gateway 路由 → 四层记忆注入 → LLM 推理 → Skill/Tool 执行 → 响应回平台 → 记忆更新。
特点:多平台、多会话、心跳、子代理、DM 配对、群组沙箱、工具白名单。
Hermes:学习闭环引擎
消息平台/CLI → Gateway → FTS5 搜索 + Honcho 用户建模 → LLM 推理 → Skill/Tool 执行 → 经验提炼 → 自动写 Skill + 持久化 → Nudge 自检 → 响应。
特点:学习闭环、并行子代理、Atropos RL 训练、轨迹导出微调。

六、选型指南
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

总结
Claude Code 是最强编码刀,OpenClaw 是最广连接网,Hermes Agent 是唯一会自己长大的 Agent。
三者的记忆和 Skill 系统从简单到复杂恰好构成一条进化线:静态笔记 → 向量搜索 → 自学习闭环。
选哪个?取决于你最在意什么——编码质量、平台覆盖、还是 AI 能不能真正「记住你」。
本文基于 hyphentech.top/agent-comparison[5] 原始对比数据撰写。
参考资料
[1]MEMORY.md: http://memory.md/
[2]MEMORY.md: http://memory.md/
[3]SKILL.md: http://skill.md/
[4]agentskills.io: http://agentskills.io/
[5]hyphentech.top/agent-comparison: http://hyphentech.top/agent-comparison
黑粉科技
用大白话讲透 AI 硬核知识
━━━━
📱 公众号:黑粉科技
📺 B站:黑粉科技
🎬 快手 / 视频号:黑粉科技
🌐 官网:www.hyphentech.top
— 感谢阅读,欢迎关注 —