 夜雨聆风
夜雨聆风





AI人物识别软件
一、软件功能
- 人物识别
:基于参考照片,在指定文件夹中查找相似人物 - 支持多种文件格式
:支持JPG、JPEG、PNG、BMP、GIF等图片格式,以及MP4、AVI、MOV、WMV等视频格式 - 非ASCII路径支持
:支持包含中文等非ASCII字符的文件路径 - 可视化界面
:提供直观的图形用户界面,操作简单 - 进度显示
:实时显示处理进度和结果 - 结果排序
:按相似度排序并显示最相似的结果
二、安装方法
-
下载AI人物识别.exe文件 -
双击运行即可,无需安装

三、使用步骤
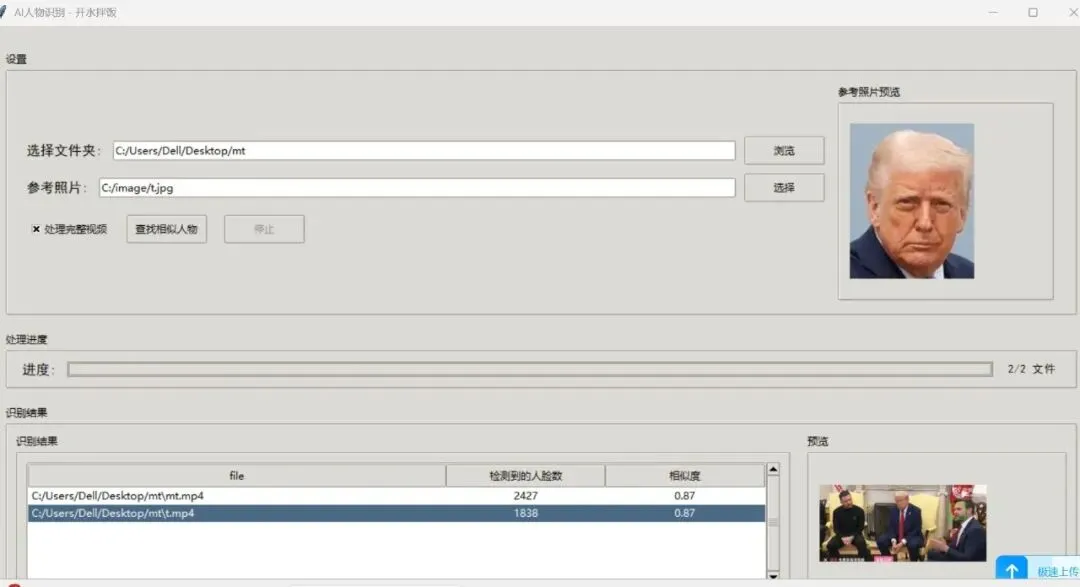
- 选择文件夹
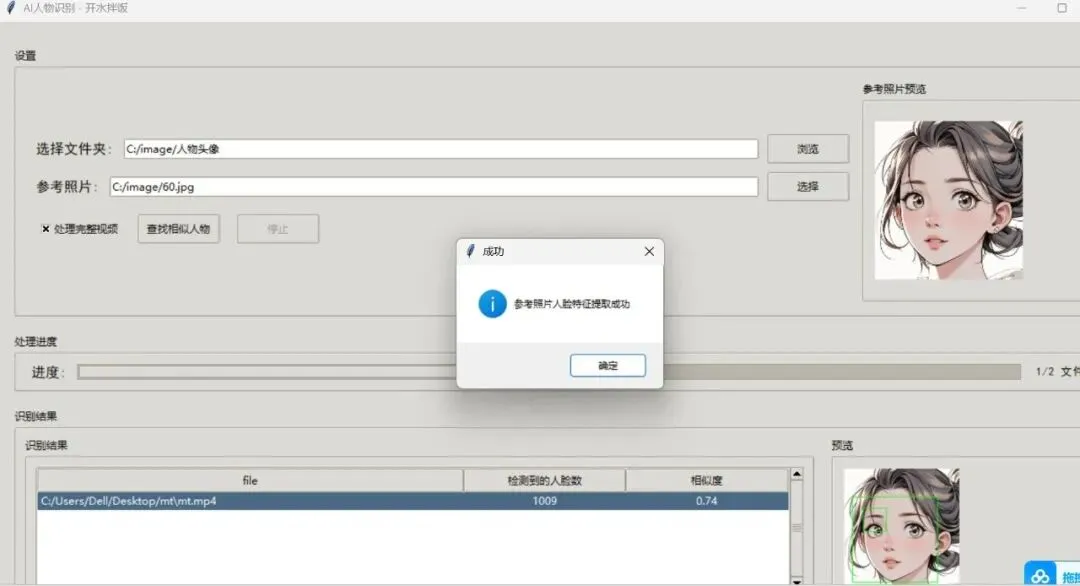
:点击“浏览“按钮,选择要搜索的文件夹 - 选择参考照片
:点击“选择“按钮,选择包含目标人物的参考照片 - 处理完整视频
(可选):如果需要处理视频文件的完整内容,勾选“处理完整视频“选项 - 查找相似人物
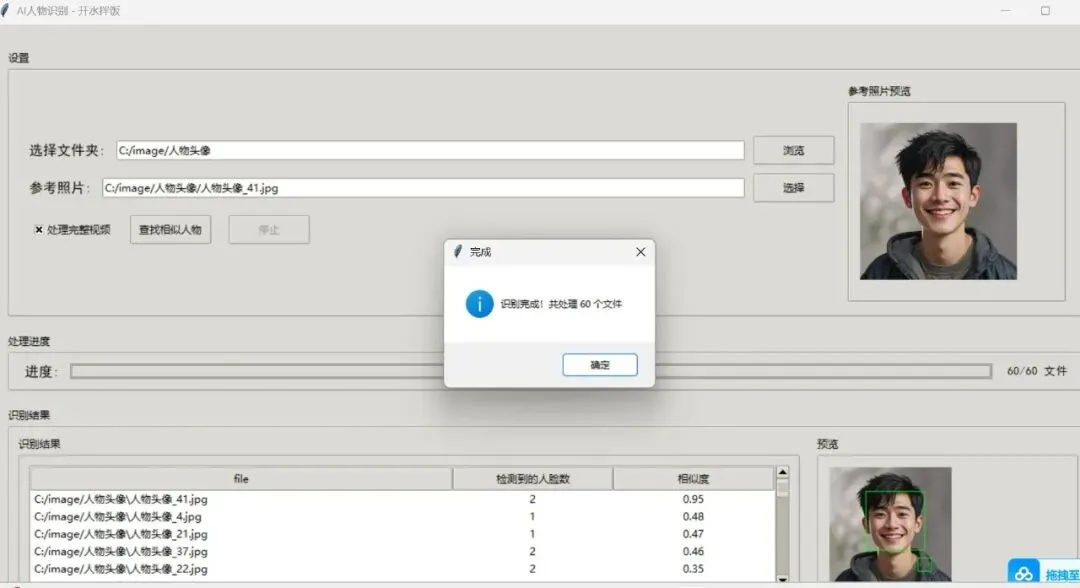
:点击“查找相似人物“按钮开始搜索 - 查看结果
:处理完成后,结果会显示在“识别结果“表格中,并按相似度排序 - 查看预览
:点击表格中的结果,可以在右侧预览窗口中查看图片或视频帧
四、注意事项
- 参考照片要求
: -
参考照片应清晰显示人物面部 -
面部应占据照片的大部分区域 -
光线应充足,避免过暗或过亮 -
面部应正面朝向摄像头 -
避免遮挡面部的物品,如帽子、墨镜等 - 性能注意事项
: -
处理大量文件或视频可能需要较长时间 -
处理完整视频会消耗更多系统资源和时间 -
建议在处理大量文件时关闭其他占用资源的程序 - 系统要求
: - Windows 10
或更高版本 -
至少4GB内存 -
足够的存储空间 -
支持OpenCV的硬件环境 - 故障排除
: -
如果无法读取参考照片,检查文件路径是否包含非ASCII字符 -
如果检测不到人脸,尝试调整参考照片或使用更清晰的照片 -
如果程序无响应,可能是正在处理大量文件,请耐心等待 -
如果出现错误,检查控制台输出以获取详细信息 - 其他注意事项
: -
本软件仅用于个人和非商业用途 -
处理视频文件时,会提取关键帧进行分析,可能会遗漏某些帧 -
相似度计算基于简单的直方图比较,可能不是最精确的方法 -
对于分辨率较低的图片,识别准确率可能会降低
五、常见问题
Q: 为什么参考照片中未检测到人脸?
A: 可能的原因包括:照片中人脸不清晰、光线过暗或过亮、人脸被遮挡、人脸角度过大等。建议使用清晰、正面、光线充足的照片。
Q: 为什么很多照片显示相似度为0?
A: 可能是因为这些照片中没有检测到人脸,或者检测到的人脸与参考照片差异较大。
Q: 处理视频文件时,为什么只显示部分帧?
A: 默认情况下,软件会提取视频的关键帧进行分析,以提高处理速度。如果需要处理所有帧,请勾选“处理完整视频“选项。
Q: 为什么软件运行速度较慢?
A: 处理大量文件或视频需要一定的时间,特别是在处理完整视频时。建议在处理大量文件时关闭其他占用资源的程序。
Q: 为什么软件无法读取某些图片?
A: 可能是因为图片格式不支持,或者文件路径包含非ASCII字符。本软件已经优化了对非ASCII路径的支持,但某些特殊情况可能仍然存在问题。
下载
链接: https://pan.baidu.com/s/1IHOJ43ZmMy9h67PtXqg_CQ
提取码: dqi6
操作
已关注
关注
重播 分享 赞
代码
import tkinter as tkfrom tkinter import filedialog, messagebox, ttkimport cv2import osimport threadingimport timefrom PIL import Image, ImageTkimport numpy as npclass AIRecognitionApp:def __init__(self, root):self.root = rootself.root.title("AI人物识别 - 开水拌饭")# 获取屏幕大小screen_width = root.winfo_screenwidth() screen_height = root.winfo_screenheight()# 设置窗口大小为屏幕大小self.root.geometry(f"{screen_width}x{screen_height}")self.root.state('zoomed') # 最大化窗口self.root.resizable(True, True)# 绑定窗口大小变化事件,确保界面元素能适应窗口大小变化self.root.bind('<Configure>', self.on_window_resize)# 设置主题self.style = ttk.Style()self.style.theme_use('clam')# 变量self.folder_path = tk.StringVar()self.reference_image_path = tk.StringVar()self.processing = Falseself.processed_files = 0self.total_files = 0self.results = []self.reference_face_features = None# 创建UIself.create_ui()# 加载预训练的人脸检测器self.face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')def create_ui(self):# 主框架main_frame = ttk.Frame(self.root, padding="20") main_frame.pack(fill=tk.BOTH, expand=True)# 移除标题,使用窗口标题即可# 文件夹和参考照片选择区域select_frame = ttk.LabelFrame(main_frame, text="设置", padding=15) select_frame.pack(fill=tk.X, pady=10)# 左侧选择区域left_frame = ttk.Frame(select_frame) left_frame.pack(side=tk.LEFT, fill=tk.X, expand=True)# 文件夹选择folder_frame = ttk.Frame(left_frame) folder_frame.pack(fill=tk.X, pady=5) ttk.Label(folder_frame, text="选择文件夹:", font=("SimHei", 12)).pack(side=tk.LEFT, padx=5, anchor=tk.W) ttk.Entry(folder_frame, textvariable=self.folder_path, width=30).pack(side=tk.LEFT, padx=5, fill=tk.X,expand=True) ttk.Button(folder_frame, text="浏览", command=self.browse_folder).pack(side=tk.LEFT, padx=5)# 参考照片选择ref_frame = ttk.Frame(left_frame) ref_frame.pack(fill=tk.X, pady=5) ttk.Label(ref_frame, text="参考照片:", font=("SimHei", 12)).pack(side=tk.LEFT, padx=5, anchor=tk.W) ttk.Entry(ref_frame, textvariable=self.reference_image_path, width=30).pack(side=tk.LEFT, padx=5, fill=tk.X,expand=True) ttk.Button(ref_frame, text="选择", command=self.select_reference_image).pack(side=tk.LEFT, padx=5)# 控制按钮 - 放在参考照片输入框下面,参考照片预览的左边button_frame = ttk.Frame(left_frame) button_frame.pack(fill=tk.X, pady=10)# 处理完整视频选项self.full_video_var = tk.BooleanVar(value=False) full_video_check = ttk.Checkbutton(button_frame, text="处理完整视频", variable=self.full_video_var) full_video_check.pack(side=tk.LEFT, padx=10)self.find_similar_button = ttk.Button(button_frame, text="查找相似人物", command=self.find_similar_faces, style="Accent.TButton")self.find_similar_button.pack(side=tk.LEFT, padx=10)self.stop_button = ttk.Button(button_frame, text="停止", command=self.stop_recognition, state=tk.DISABLED)self.stop_button.pack(side=tk.LEFT, padx=10)# 右侧参考照片预览right_frame = ttk.LabelFrame(select_frame, text="参考照片预览", padding=10, width=250, height=250) right_frame.pack(side=tk.RIGHT, padx=10, fill=tk.BOTH, expand=False) right_frame.pack_propagate(False) # 防止内容改变框架大小self.reference_preview_label = ttk.Label(right_frame)self.reference_preview_label.pack(fill=tk.BOTH, expand=True, ipadx=10, ipady=10)# 进度条self.progress_var = tk.DoubleVar() progress_frame = ttk.LabelFrame(main_frame, text="处理进度", padding=10) progress_frame.pack(fill=tk.X, pady=10) ttk.Label(progress_frame, text="进度:", font=("SimHei", 12)).pack(side=tk.LEFT, padx=5, anchor=tk.CENTER)self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)self.progress_bar.pack(side=tk.LEFT, padx=5, fill=tk.X, expand=True)self.progress_label = ttk.Label(progress_frame, text="0/0 文件", font=("SimHei", 10))self.progress_label.pack(side=tk.LEFT, padx=10, anchor=tk.CENTER)# 结果和预览区域 - 占窗口的4分之3result_preview_frame = ttk.LabelFrame(main_frame, text="识别结果", padding=10)# 使用权重参数确保它占据大部分空间result_preview_frame.pack(fill=tk.BOTH, expand=True, pady=10)# 设置权重,让设置和处理进度只占界面的4分之一,识别结果占4分之3main_frame.rowconfigure(0, weight=1) # 设置区域权重为1main_frame.rowconfigure(1, weight=1) # 处理进度区域权重为1main_frame.rowconfigure(2, weight=3) # 结果预览区域权重为3 # 这样设置和处理进度的总权重为2,结果预览区域权重为3,总权重为5 # 但实际上,Tkinter会根据可见的行来分配空间,所以我们需要确保只有这三行# 为了更精确,我们可以重新组织布局,将设置和处理进度放在一个框架中# 然后为这个框架设置权重1,结果预览区域设置权重3 # 结果列表result_frame = ttk.LabelFrame(result_preview_frame, text="识别结果", padding=10) result_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 10)) columns = ("file", "faces", "similarity")self.tree = ttk.Treeview(result_frame, columns=columns, show="headings")# 设置表头和排序功能for col in columns:self.tree.heading(col, text=col if col == "file" else ("检测到的人脸数" if col == "faces" else "相似度"), command=lambda _col=col: self.tree_sort_column(_col, False))self.tree.column("file", width=400)self.tree.column("faces", width=100, anchor=tk.CENTER)self.tree.column("similarity", width=100, anchor=tk.CENTER)# 绑定双击事件self.tree.bind("<Double-1>", self.on_double_click)# 绑定选择事件self.tree.bind("<<TreeviewSelect>>", self.on_tree_select) scrollbar = ttk.Scrollbar(result_frame, orient=tk.VERTICAL, command=self.tree.yview)self.tree.configure(yscroll=scrollbar.set) scrollbar.pack(side=tk.RIGHT, fill=tk.Y)self.tree.pack(fill=tk.BOTH, expand=True)# 预览区域(在列表右边)preview_frame = ttk.LabelFrame(result_preview_frame, text="预览", padding=10, width=300) preview_frame.pack(side=tk.RIGHT, fill=tk.BOTH, padx=(10, 0)) preview_frame.pack_propagate(False)self.preview_label = ttk.Label(preview_frame)self.preview_label.pack(fill=tk.BOTH, expand=True, ipadx=10, ipady=10)def browse_folder(self): folder = filedialog.askdirectory()if folder:self.folder_path.set(folder)def select_reference_image(self): file_types = [('Image files', '*.jpg *.jpeg *.png *.bmp *.gif'), ('All files', '*.*')] file_path = filedialog.askopenfilename(filetypes=file_types)if file_path:print(f"选择的参考照片路径: {file_path}")print(f"文件是否存在: {os.path.exists(file_path)}")self.reference_image_path.set(file_path)# 显示参考照片预览print("调用show_reference_preview")self.show_reference_preview(file_path)# 提取参考照片的人脸特征self.extract_reference_face_features()def extract_reference_face_features(self):"""提取参考照片的人脸特征"""image_path = self.reference_image_path.get()if not image_path:return try:# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(image_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if img is None: messagebox.showerror("错误", "无法读取参考照片")returngray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 调整人脸检测参数,使其更加宽松,提高检测率faces = self.face_cascade.detectMultiScale( gray, scaleFactor=1.03, # 更小的缩放因子,检测更精细minNeighbors=2, # 更少的邻居,减少漏检minSize=(15, 15), # 更小的最小人脸尺寸maxSize=(400, 400) # 更大的最大人脸尺寸)# 如果没有检测到人脸,尝试使用不同的参数组合if len(faces) == 0:print("尝试使用更宽松的参数") faces = self.face_cascade.detectMultiScale( gray, scaleFactor=1.02, # 非常小的缩放因子minNeighbors=1, # 最少的邻居minSize=(10, 10), # 非常小的最小人脸尺寸maxSize=(500, 500) # 更大的最大人脸尺寸)print(f"检测到的人脸数量: {len(faces)}")if len(faces) == 0: messagebox.showerror("错误", "参考照片中未检测到人脸")self.reference_face_features = None return# 只使用第一个检测到的人脸x, y, w, h = faces[0] face_roi = gray[y:y + h, x:x + w] face_roi = cv2.resize(face_roi, (100, 100)) # 调整为固定大小# 提取特征(使用简单的直方图作为特征)hist = cv2.calcHist([face_roi], [0], None, [256], [0, 256]) hist = cv2.normalize(hist, hist).flatten()self.reference_face_features = hist messagebox.showinfo("成功", "参考照片人脸特征提取成功")# 显示参考照片for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)self.update_preview(img)except Exception as e:print(f"提取参考人脸特征时出错: {e}") messagebox.showerror("错误", f"提取人脸特征时出错: {str(e)}")self.reference_face_features = None def load_image(self, image_path):"""读取图像,处理非ASCII路径"""try:# 使用PIL库读取图像,它对非ASCII路径支持更好from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(image_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)return imgexcept Exception as e:print(f"读取图像时出错: {e}")return None def read_image(self, image_path):"""读取图像,处理非ASCII路径"""return self.load_image(image_path)def show_reference_preview(self, image_path):"""显示参考照片预览"""try:print(f"显示参考照片: {image_path}")# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(image_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)print(f"读取图像返回: {img is not None}")if img is not None:# 调整图像大小以适应预览区域h, w = img.shape[:2]print(f"图像尺寸: {w}x{h}") max_size = 180if h > max_size or w > max_size:if h > w: scale = max_size / helse: scale = max_size / w img = cv2.resize(img, (int(w * scale), int(h * scale)))print(f"调整后尺寸: {int(w * scale)}x{int(h * scale)}")# 转换为RGB并显示img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = Image.fromarray(img) img = ImageTk.PhotoImage(img)print("创建PhotoImage成功")# 使用after确保在主线程中更新UIdef update_preview_label():print("更新preview_label")self.reference_preview_label.config(image=img)self.reference_preview_label.image = img # 保持引用print("更新完成")self.root.after(0, update_preview_label)print("调用after完成")else:print("无法读取图像")def show_error():self.reference_preview_label.config(text="无法加载图片", justify=tk.CENTER)self.root.after(0, show_error)except Exception as e:print(f"显示参考照片预览时出错: {e}")# 显示错误信息error_msg = f"无法加载图片: {str(e)}"def show_error():self.reference_preview_label.config(text=error_msg, justify=tk.CENTER)self.root.after(0, show_error)def calculate_similarity(self, face_features):"""计算两个人脸特征之间的相似度"""if self.reference_face_features is None:return 0.0# 使用余弦相似度similarity = cv2.compareHist(self.reference_face_features, face_features, cv2.HISTCMP_CORREL)return similaritydef find_similar_faces(self): folder = self.folder_path.get()if not folder: messagebox.showerror("错误", "请选择文件夹")return if not os.path.exists(folder): messagebox.showerror("错误", "文件夹不存在")return if not self.reference_image_path.get(): messagebox.showerror("错误", "请选择参考照片")return if self.reference_face_features is None: messagebox.showerror("错误", "无法从参考照片中提取人脸特征")return# 清空之前的结果for item in self.tree.get_children():self.tree.delete(item)self.results = []self.processed_files = 0self.total_files = 0self.progress_var.set(0)self.progress_label.config(text="0/0 文件")# 开始处理self.processing = Trueself.find_similar_button.config(state=tk.DISABLED)self.stop_button.config(state=tk.NORMAL)# 在新线程中处理文件thread = threading.Thread(target=self.process_folder, args=(folder,)) thread.daemon = Truethread.start()def stop_recognition(self):self.processing = Falseself.find_similar_button.config(state=tk.NORMAL)self.stop_button.config(state=tk.DISABLED)def process_folder(self, folder):# 获取所有图片和视频文件files = []for root, _, filenames in os.walk(folder):for filename in filenames: ext = os.path.splitext(filename)[1].lower()if ext in ['.jpg', '.jpeg', '.png', '.bmp', '.gif', '.mp4', '.avi', '.mov', '.wmv']: files.append(os.path.join(root, filename))self.total_files = len(files)self.root.after(0, lambda: self.progress_label.config(text=f"0/{self.total_files} 文件"))for i, file_path in enumerate(files):if not self.processing:break try: ext = os.path.splitext(file_path)[1].lower()if ext in ['.jpg', '.jpeg', '.png', '.bmp', '.gif']: faces, similarity = self.process_image_for_similarity(file_path)else: faces, similarity = self.process_video_for_similarity(file_path)self.results.append((file_path, faces, similarity))self.processed_files += 1# 更新UIprogress = (self.processed_files / self.total_files) * 100self.root.after(0, lambda p=progress, f=file_path, fc=faces, s=similarity: self.update_ui(p, f, fc, s))except Exception as e:print(f"处理文件 {file_path} 时出错: {e}")self.processed_files += 1progress = (self.processed_files / self.total_files) * 100self.root.after(0, lambda p=progress, f=file_path: self.update_ui(p, f, "错误", "-"))# 短暂休息,避免UI卡顿time.sleep(0.1)# 处理完成后按相似度排序并显示最相似的结果self.root.after(0, self.sort_and_show_best_result)def on_window_resize(self, event):"""处理窗口大小变化事件"""# 这里可以添加调整界面元素大小的代码# 例如:调整预览区域的大小,调整表格的大小等pass def process_image(self, image_path):# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(image_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if img is None:return 0gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 使用与参考图像相同的宽松人脸检测参数faces = self.face_cascade.detectMultiScale( gray,scaleFactor=1.03, # 更小的缩放因子,检测更精细minNeighbors=2, # 更少的邻居,减少漏检minSize=(15, 15), # 更小的最小人脸尺寸maxSize=(400, 400) # 更大的最大人脸尺寸)# 如果没有检测到人脸,尝试使用不同的参数组合if len(faces) == 0:print(f"文件 {image_path} 尝试使用更宽松的参数") faces = self.face_cascade.detectMultiScale( gray,scaleFactor=1.02, # 非常小的缩放因子minNeighbors=1, # 最少的邻居minSize=(10, 10), # 非常小的最小人脸尺寸maxSize=(500, 500) # 更大的最大人脸尺寸)# 绘制人脸框for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)# 更新预览self.update_preview(img)return len(faces)def process_image_for_similarity(self, image_path):# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(image_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if img is None:return 0, "-"gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) max_similarity = 0.0# 绘制人脸框并计算相似度for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)# 提取人脸特征face_roi = gray[y:y + h, x:x + w] face_roi = cv2.resize(face_roi, (100, 100)) hist = cv2.calcHist([face_roi], [0], None, [256], [0, 256]) hist = cv2.normalize(hist, hist).flatten()# 计算相似度similarity = self.calculate_similarity(hist) max_similarity = max(max_similarity, similarity)# 更新预览self.update_preview(img)return len(faces), f"{max_similarity:.2f}"def process_video(self, video_path): cap = cv2.VideoCapture(video_path) total_faces = 0frame_count = 0# 确定是否处理完整视频process_full_video = getattr(self, 'full_video_var', tk.BooleanVar(value=False)).get()while cap.isOpened() and (process_full_video or frame_count < 10): ret, frame = cap.read()if not ret:breakgray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) total_faces += len(faces)# 绘制人脸框并更新预览(仅第一帧)if frame_count == 0:for (x, y, w, h) in faces: cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)self.update_preview(frame) frame_count += 1# 检查是否需要停止处理if not getattr(self, 'processing', True):breakcap.release()return total_facesdef process_video_for_similarity(self, video_path): cap = cv2.VideoCapture(video_path) total_faces = 0max_similarity = 0.0frame_count = 0video_faces = [] # 存储视频中的人脸信息# 确定是否处理完整视频process_full_video = getattr(self, 'full_video_var', tk.BooleanVar(value=False)).get()# 创建视频预览窗口preview_window = None if process_full_video: preview_window = tk.Toplevel(self.root) preview_window.title(f"视频处理预览: {os.path.basename(video_path)}") preview_window.geometry("600x400")# 创建滚动框架main_frame = ttk.Frame(preview_window, padding=10) main_frame.pack(fill=tk.BOTH, expand=True) canvas = tk.Canvas(main_frame) scrollbar = ttk.Scrollbar(main_frame, orient=tk.VERTICAL, command=canvas.yview) scrollable_frame = ttk.Frame(canvas) scrollable_frame.bind("<Configure>",lambda e: canvas.configure(scrollregion=canvas.bbox("all") ) ) canvas.create_window((0, 0), window=scrollable_frame, anchor="nw") canvas.configure(yscrollcommand=scrollbar.set) canvas.pack(side=tk.LEFT, fill=tk.BOTH, expand=True) scrollbar.pack(side=tk.RIGHT, fill=tk.Y)# 添加标题ttk.Label(scrollable_frame, text="正在处理的视频截图", font=('SimHei', 12, 'bold')).pack(pady=5)# 处理视频帧while cap.isOpened() and (process_full_video or frame_count < 10): ret, frame = cap.read()if not ret:break# 获取当前帧的时间current_time = cap.get(cv2.CAP_PROP_POS_MSEC) / 1000.0 # 转换为秒gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) total_faces += len(faces)# 计算相似度for (x, y, w, h) in faces: face_roi = gray[y:y+h, x:x+w] face_roi = cv2.resize(face_roi, (100, 100)) hist = cv2.calcHist([face_roi], [0], None, [256], [0, 256]) hist = cv2.normalize(hist, hist).flatten() similarity = self.calculate_similarity(hist) max_similarity = max(max_similarity, similarity)# 保存人脸信息video_faces.append({'time': current_time,'coords': (x, y, w, h),'similarity': similarity,'frame': frame.copy() })# 绘制人脸框并更新预览for (x, y, w, h) in faces: cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)# 第一帧更新主预览if frame_count == 0:self.update_preview(frame)# 如果处理完整视频,更新预览窗口if process_full_video and preview_window and frame_count % 10 == 0: # 每10帧更新一次# 调整大小h_frame, w_frame = frame.shape[:2] max_size = 400if h_frame > max_size or w_frame > max_size:if h_frame > w_frame: scale = max_size / h_frameelse: scale = max_size / w_frame frame_resized = cv2.resize(frame, (int(w_frame*scale), int(h_frame*scale)))else: frame_resized = frame.copy()# 转换为RGB并显示frame_resized = cv2.cvtColor(frame_resized, cv2.COLOR_BGR2RGB) frame_resized = Image.fromarray(frame_resized) frame_resized = ImageTk.PhotoImage(frame_resized)# 创建帧信息frame_info = ttk.LabelFrame(scrollable_frame, text=f"帧 #{frame_count} - {current_time:.2f}秒", padding=5) frame_info.pack(fill=tk.X, pady=5) frame_label = ttk.Label(frame_info, image=frame_resized) frame_label.image = frame_resized # 保持引用frame_label.pack()# 自动滚动到底部canvas.yview_moveto(1.0) frame_count += 1# 检查是否需要停止处理if not getattr(self, 'processing', True):breakcap.release()# 关闭预览窗口if preview_window: preview_window.destroy()# 保存视频人脸信息到结果中if not hasattr(self, 'video_faces_info'):self.video_faces_info = {}self.video_faces_info[video_path] = video_facesreturn total_faces, f"{max_similarity:.2f}"def update_preview(self, img):# 转换为RGBimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 转换为PIL图像img = Image.fromarray(img)# 获取预览标签的实际大小def resize_and_display():# 获取预览标签的宽度和高度label_width = self.preview_label.winfo_width() label_height = self.preview_label.winfo_height()# 确保标签有足够的大小if label_width > 10 and label_height > 10:# 获取原始图像大小img_width, img_height = img.size# 计算缩放比例,保持原始比例scale = min(label_width / img_width, label_height / img_height, 1.0)# 计算新的图像大小new_width = int(img_width * scale) new_height = int(img_height * scale)# 调整图像大小resized_img = img.resize((new_width, new_height), Image.LANCZOS)# 转换为PhotoImagephoto_img = ImageTk.PhotoImage(resized_img)# 更新标签self.preview_label.config(image=photo_img)self.preview_label.image = photo_img # 保持引用# 使用after确保在主线程中更新UI,并且标签大小已经计算self.root.after(100, resize_and_display)def update_ui(self, progress, file_path, faces, similarity="-"):self.progress_var.set(progress)self.progress_label.config(text=f"{self.processed_files}/{self.total_files} 文件")# 添加到结果列表self.tree.insert("", tk.END, values=(file_path, faces, similarity))def sort_and_show_best_result(self):"""按相似度排序并显示最相似的结果"""# 按相似度排序结果def get_similarity_value(item):try:return float(item[2]) if item[2] != "-" and item[2] != "错误" else -1except ValueError:return -1self.results.sort(key=get_similarity_value, reverse=True)# 清空当前列表并重新插入排序后的结果for item in self.tree.get_children():self.tree.delete(item)for result in self.results:self.tree.insert("", tk.END, values=result)# 显示最相似的结果if self.results: best_result = self.results[0] best_file_path = best_result[0]# 显示最相似的图片或视频帧ext = os.path.splitext(best_file_path)[1].lower()if ext in ['.jpg', '.jpeg', '.png', '.bmp', '.gif']:# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(best_file_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if img is not None:# 检测人脸并绘制框gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)self.update_preview(img)else:# 处理视频,显示第一帧cap = cv2.VideoCapture(best_file_path) ret, frame = cap.read()if ret: gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))for (x, y, w, h) in faces: cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)self.update_preview(frame) cap.release()# 完成处理self.finish_processing()def finish_processing(self):self.processing = Falseself.find_similar_button.config(state=tk.NORMAL)self.stop_button.config(state=tk.DISABLED) messagebox.showinfo("完成", f"识别完成!共处理 {self.processed_files} 个文件")def tree_sort_column(self, col, reverse):"""排序树状列表"""# 获取所有项目items = [(self.tree.set(k, col), k) for k in self.tree.get_children('')]# 尝试将值转换为数字进行排序try: items.sort(key=lambda x: float(x[0]) if x[0] != "-" and x[0] != "错误" else -1, reverse=reverse)except ValueError:# 如果转换失败,按字符串排序items.sort(key=lambda x: x[0], reverse=reverse)# 重新排列项目for index, (val, k) in enumerate(items):self.tree.move(k, '', index)# 切换排序方向self.tree.heading(col, command=lambda _col=col: self.tree_sort_column(_col, not reverse))def on_double_click(self, event):"""双击打开文件"""item = self.tree.selection()[0] file_path = self.tree.item(item, "values")[0]if os.path.exists(file_path):try: os.startfile(file_path)except Exception as e: messagebox.showerror("错误", f"无法打开文件: {str(e)}")else: messagebox.showerror("错误", "文件不存在")def on_tree_select(self, event):"""当选中树状列表项时"""selected_items = self.tree.selection()if selected_items: item = selected_items[0] file_path = self.tree.item(item, "values")[0]# 检查是否是视频文件ext = os.path.splitext(file_path)[1].lower()if ext in ['.mp4', '.avi', '.mov', '.wmv']:# 显示视频人脸信息self.show_video_face_info(file_path)else:# 对于图片,显示图片预览# 使用PIL读取图像,处理非ASCII路径from PIL import Imageimport numpy as np# 打开图像pil_img = Image.open(file_path)# 转换为numpy数组img = np.array(pil_img)# 转换为BGR格式(OpenCV使用的格式)if len(img.shape) == 3: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if img is not None: gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = self.face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)self.update_preview(img)def show_video_face_info(self, video_path):"""显示视频人脸信息"""if hasattr(self, 'video_faces_info') and video_path in self.video_faces_info: video_faces = self.video_faces_info[video_path]if video_faces:# 创建视频人脸信息窗口face_info_window = tk.Toplevel(self.root) face_info_window.title(f"视频人脸信息: {os.path.basename(video_path)}") face_info_window.geometry("900x600")# 主框架main_frame = ttk.Frame(face_info_window, padding=10) main_frame.pack(fill=tk.BOTH, expand=True)# 表格框架table_frame = ttk.LabelFrame(main_frame, text="人脸信息列表", padding=10) table_frame.pack(fill=tk.BOTH, expand=True, pady=5)# 创建表格columns = ("index", "time", "similarity") tree = ttk.Treeview(table_frame, columns=columns, show="headings")# 设置表头tree.heading("index", text="序号") tree.heading("time", text="时间(秒)", command=lambda: self.sort_tree(tree, "time", False)) tree.heading("similarity", text="相似度", command=lambda: self.sort_tree(tree, "similarity", False))# 设置列宽tree.column("index", width=50, anchor=tk.CENTER) tree.column("time", width=100, anchor=tk.CENTER) tree.column("similarity", width=100, anchor=tk.CENTER)# 添加滚动条scrollbar = ttk.Scrollbar(table_frame, orient=tk.VERTICAL, command=tree.yview) tree.configure(yscroll=scrollbar.set) scrollbar.pack(side=tk.RIGHT, fill=tk.Y) tree.pack(fill=tk.BOTH, expand=True)# 预览框架preview_frame = ttk.LabelFrame(main_frame, text="视频截图", padding=10) preview_frame.pack(fill=tk.BOTH, expand=True, pady=5) preview_label = ttk.Label(preview_frame) preview_label.pack(fill=tk.BOTH, expand=True)# 填充表格数据for i, face_info in enumerate(video_faces): tree.insert("", tk.END, values=(i+1, f"{face_info['time']:.2f}", f"{face_info['similarity']:.2f}"), tags=(i,))# 定义更新预览的函数def update_preview_with_face(face_info):# 显示该时间段的视频截图frame = face_info['frame'] x, y, w, h = face_info['coords']# 绘制人脸框cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)# 保存原始帧以便调整大小face_info['original_frame'] = frame.copy()# 调整大小以适应当前窗口def resize_preview():if 'original_frame' not in face_info:returnframe = face_info['original_frame'].copy()# 检查帧是否有效if frame is None or frame.size == 0:return# 获取预览标签的大小width = preview_label.winfo_width() height = preview_label.winfo_height()if width > 10 and height > 10: # 确保窗口已经初始化h_frame, w_frame = frame.shape[:2]# 计算缩放比例scale = min(width / w_frame, height / h_frame, 1.0) # 不放大超过原始大小if scale < 1.0: frame = cv2.resize(frame, (int(w_frame*scale), int(h_frame*scale)))# 转换为RGB并显示frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) frame = Image.fromarray(frame) frame = ImageTk.PhotoImage(frame) preview_label.config(image=frame) preview_label.image = frame # 保持引用# 初始调整大小,使用after确保窗口已经完全初始化def delayed_resize(): resize_preview() face_info_window.after(100, delayed_resize)# 绑定窗口大小变化事件def on_configure(event): resize_preview() preview_frame.bind("<Configure>", on_configure)# 双击事件处理def on_tree_double_click(event): item = tree.selection()[0] index = int(tree.item(item, "tags")[0]) face_info = video_faces[index] update_preview_with_face(face_info) tree.bind("<Double-1>", on_tree_double_click)# 绑定选择事件,显示选中的人脸def on_tree_select(event):if tree.selection(): item = tree.selection()[0] index = int(tree.item(item, "tags")[0]) face_info = video_faces[index] update_preview_with_face(face_info) tree.bind("<<TreeviewSelect>>", on_tree_select)# 默认选中第一个项目并显示预览if tree.get_children(): tree.selection_set(tree.get_children()[0])# 手动触发选择事件,显示第一张人脸first_item = tree.get_children()[0] first_index = int(tree.item(first_item, "tags")[0]) first_face_info = video_faces[first_index] update_preview_with_face(first_face_info)else: messagebox.showinfo("信息", "该视频中未检测到人脸")else: messagebox.showinfo("信息", "未找到视频人脸信息")def sort_tree(self, tree, col, reverse):"""排序表格"""# 获取所有项目items = [(tree.set(k, col), k) for k in tree.get_children('')]# 尝试将值转换为数字进行排序try: items.sort(key=lambda x: float(x[0]), reverse=reverse)except ValueError:# 如果转换失败,按字符串排序items.sort(key=lambda x: x[0], reverse=reverse)# 重新排列项目for index, (val, k) in enumerate(items): tree.move(k, '', index)# 切换排序方向if col == "time": tree.heading(col, command=lambda: self.sort_tree(tree, col, not reverse))elif col == "similarity": tree.heading(col, command=lambda: self.sort_tree(tree, col, not reverse))if __name__ == "__main__": root = tk.Tk() app = AIRecognitionApp(root) root.mainloop()