 夜雨聆风
夜雨聆风





AI 会把软件变成快消品吗?我不这么看
前几天和朋友聊起一个问题:未来的软件,会不会真的越来越像一次性用品?
这个说法现在很流行。理由也不复杂:大模型越来越会写代码,搭个后台、做个页面、拼个工作流都越来越快。于是很多人自然会觉得,软件的时代是不是快结束了,接下来大家只需要“说一句话”,系统就会现场生成一个东西,用一次,扔掉,再生成下一个。
这个判断听起来很性感,但我一直觉得,它只看到了软件最表层的变化,没有看到软件真正稳定的那一层。

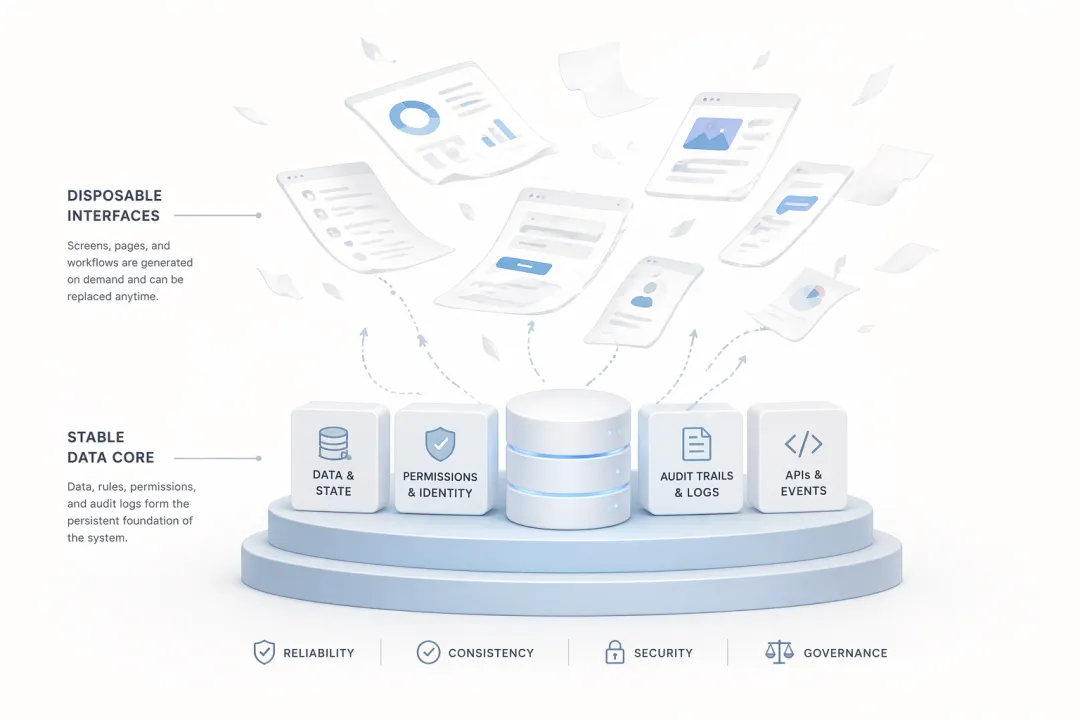
未来会越来越像一次性用品的,主要是软件的“外壳”;不会变的,是软件的“责任”。
什么叫责任?
说得直白一点,软件从来不是一堆代码而已。软件本质上是在替组织、业务和社会承担责任。
钱怎么算,权限怎么控,流程怎么走,合同怎么履约,风控怎么拦,审计怎么追,出了事故谁来背锅——这些事情,不会因为 LLM 很强就消失。相反,模型越强,系统能自动化承担的业务越多,这些责任边界只会变得更重要,不会变得更轻。最近主流 AI coding 产品的产品形态也体现了这个方向:它们都在强化“计划、验证、审查、可回滚”,而不只是“生成”。GitHub 最近把 Copilot cloud agent 的实现计划、分支工作流和自动验证工具放到了产品正中央;Anthropic 也反复强调 agent 要在多上下文窗口下持续推进任务,关键不只是模型会写,而是能否在正确的环境与验证链条中稳定前进。(The GitHub Blog)
所以我越来越倾向于用一个更准确的框架去看未来软件:
一次性的,是界面;稳定的,是状态。
很多人讨论 AI 软件时,注意力都放在“前端是不是会自动生成”“App 会不会没人做了”“一个页面还能值多少钱”。这些问题不能说不重要,但它们离系统的核心其实很远。真正不容易被一次性替代的,始终是下面这些东西:
数据模型状态一致性身份与权限业务规则审计与追责协议与接口测试与发布闸门
页面可以重做,交互可以替换,甚至 agent 可以临时拼出一个非常顺手的前台;但真正的系统状态,不可能是一次性的。谁拥有数据,谁定义 schema,谁决定事务边界,谁保留历史,谁能回滚,这些都不是 prompt 一下就能“用完即弃”的东西。
这也是为什么,未来的软件世界很可能不是“软件消失”,而是“软件分层”。上层会越来越轻,越来越临时,越来越可生成;下层会越来越稳定,越来越强约束,越来越像基础设施。这个趋势和 OpenAI、GitHub、Anthropic 近几个月把重心转向 repo、branch、sandbox、tests、diff、review 的方向是同向的。(OpenAI Platform)
这也是为什么,我并不认同“未来的软件都会被抛弃”,但我非常认同另一句话:
未来的软件,会越来越需要被 agent 操作。
这里就说到一个我非常赞同的方向:存量软件 CLI 化、API 化、Agent 化。
这条路为什么重要?
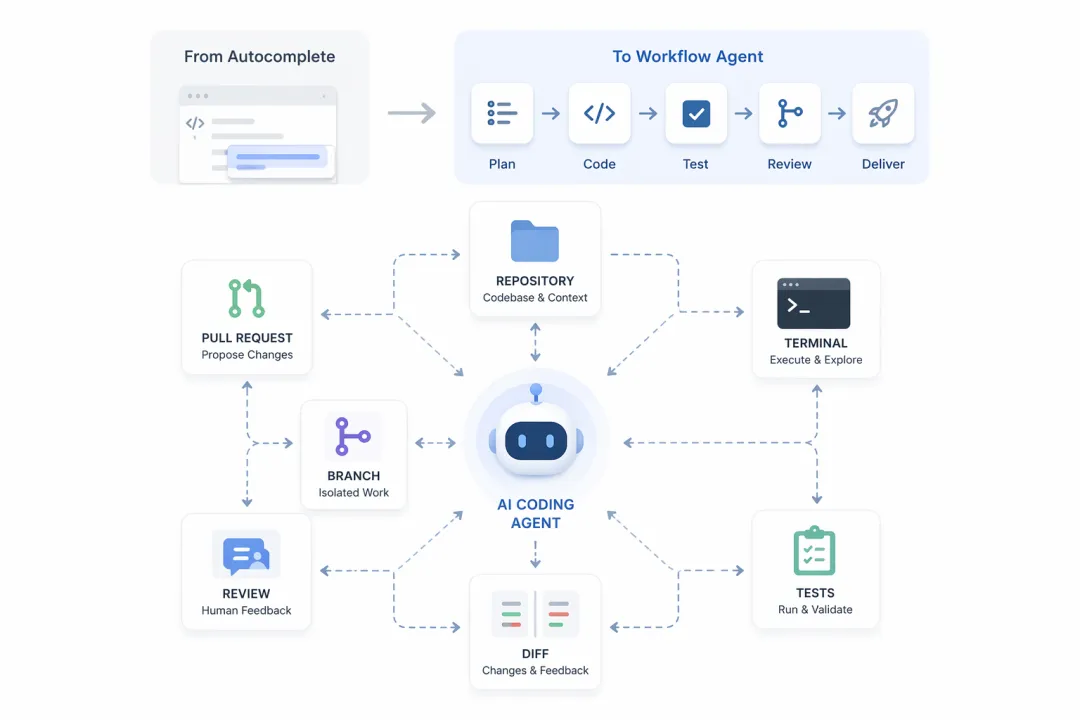
因为 agent 最擅长操作的,不是花哨复杂的 GUI,而是低熵、可组合、可追踪的操作面:终端、文件、日志、配置、API、diff、测试结果、PR。过去半年,这个趋势已经非常明显了。GitHub Copilot CLI 在 2026 年 2 月正式 GA,公开把自己定义成“terminal-native coding agent”,强调它能 plan、build、review、remember,还支持 MCP、plugins 和 skills;GitHub 的 cloud agent 则进一步支持先做 implementation plan、在 branch 上工作、看 diff、再决定要不要开 PR。Anthropic 的 Claude Code 也把自己的定位明确成能读代码库、跨文件修改、运行测试并交付提交代码的 agentic coding system。(The GitHub Blog)
这不是一个小变化。
它意味着,行业对于“AI Coding 到底是什么”的理解,已经从“编辑器里那个帮你补全代码的小助手”,转向“一个能在真实工程环境里推进工作的代理人”。
如果再往前推一步,你会发现这对未来软件形态的含义很大。
过去的软件,大多是给“人直接操作”的。未来的软件,会越来越多地同时服务三类对象:
人人的 agent系统的 agent
一旦如此,软件真正长寿的部分就更清楚了:不是漂亮页面,而是接口、协议、约束和可观测性。
所以我很愿意把未来软件的演化路径,概括成一句非常工程化的话:
GUI 软件会液化,能力层不会。
前端会越来越轻,越来越像一层临时视图。真正的竞争力,会下沉到:
API 是否稳定CLI 是否好用MCP / tools 是否可接schema 是否清晰权限边界是否严谨测试体系是否自动化审计链条是否完整
从这个角度看,“存量软件 CLI 化”并不是一个保守方向,反而可能是企业软件走向 AI 原生的现实路径。因为它不要求你推倒重来,而是让旧系统逐步长出新的操作界面。先 API 化,再 CLI 化,再接上 MCP、skills、plugins,最后让 agent 在受控边界里自动调用。对绝大多数企业来说,这条路径比“全部重写成 AI Native 产品”现实得多。OpenAI 的 Codex 也在往这个方向走:它一方面支持本地终端与 IDE,另一方面又支持云端并行任务、隔离沙箱、可审阅 diff、多 agent 协作和自动化任务,说明“本地工具面 + 云端代理面”的双栈形态已经越来越清楚。
说完“什么不会变”,再看:过去 6 个月,GenAI 赋能 coding 在理论和实践上,到底有什么大的变化?
我自己的判断是:真正的变化,不是模型更会写代码了,而是整个行业开始承认一件事——
Coding 不是写代码,Coding 是完成一段软件生产流程。
这 6 个月里最重要的转向,大概有五个。
第一,AI Coding 从“补全”转向“闭环”
以前大家说 AI coding,更多指的是代码补全、生成函数、解释错误、写单测。现在越来越多产品在做的是:
读 repo理解上下文做实施计划改多个文件运行测试看 diff做 review进入 PR 流程
GitHub 的 Copilot cloud agent 已经明确支持先生成 implementation plan,再决定是否写代码;也支持在 branch 上完成工作后,由人来决定是否创建 PR。这个产品形态本身就是一个信号:行业已经不再把 AI 当成“更强的 autocomplete”,而是在把它当成“软件生产流程里的执行者”。(The GitHub Blog)
第二,终端重新成为主战场
如果只看产品外观,你会以为 AI coding 的核心入口还是 IDE 聊天框。但过去半年真正高速进化的,其实是 terminal。
GitHub Copilot CLI 的 GA 非常具有代表性。它不是把 Copilot 搬到命令行,而是把命令行重新定义成了 agent 的工作台:可以规划复杂任务,执行多步流程,编辑文件,运行测试,跨会话记忆,并通过 MCP、plugins、skills 接入外部能力。Claude Code 和 Codex CLI 也都在强化“终端 + 仓库 + 测试 + diff”这一套操作面。(The GitHub Blog)
这背后的原因非常朴素:
终端是低熵的,可编排的,可审计的,可复现的。而这四点,恰好就是 agent 最需要的东西。
第三,提示工程正在让位于“上下文工程”和“harness 工程”
这是过去半年里,很多圈外人没看见、但圈内人感受很强烈的一件事。
以前大家总觉得,模型不够好,是 prompt 不够精妙。现在越来越多一线实践表明,真正决定 agent 表现上限的,往往不是那一句 prompt,而是:
给了它什么上下文给了它什么工具有没有 feature list有没有 progress file有没有 init 脚本有没有测试工具有没有 clean state 要求有没有明确的提交与回滚机制
Anthropic 在关于 long-running agents 的工程文章里讲得很清楚:长任务的核心问题,不是一次上下文窗口里写不写得出代码,而是 agent 跨多个 context window 时如何保持连续进展、如何不给下一轮留下烂摊子。他们给出的答案,不是“再多想一步”,而是 initializer agent、progress file、feature list、git commit、browser testing 这整套 harness。后续文章又进一步强调,到了 frontier agentic coding 的阶段,harness design 本身就是性能关键变量。(Anthropic)
这件事的理论意义非常大。它意味着:
AI coding 的瓶颈,正在从“模型本体是否聪明”,转向“系统工程是否做对”。
第四,工具协议在标准化,MCP 很重要
过去 agent 接工具,常常是一家一个方法,一套系统一个适配器。这会导致一个问题:接得越多,系统越碎;流程越复杂,维护越痛苦。
MCP 的价值,就在于它试图把“agent 怎么接工具和数据”这件事标准化。Anthropic 在官方工程文里直接把 MCP 说成连接 agents 与外部系统的开放标准,并提到其快速 adoption,社区已经构建了大量 MCP servers。更重要的是,他们展示了另一层变化:agent 不只是“调工具”,而是开始“写代码去调工具”,这样能显著减少上下文消耗。在他们的案例里,token 消耗从 150,000 降到了 2,000,节省 98.7%。(Anthropic)
这背后的行业趋势其实非常明确:
未来 AI coding 的竞争,不只是模型会不会写业务代码,而是它能不能自然地接入整个软件世界。
第五,评测也变了:从纯文本 patch,转向更真实的软件任务
这半年另一个值得注意的变化,是大家开始承认:以前很多 coding benchmark 太“纸面”了。
SWE-bench 体系这段时间持续扩展。SWE-bench Multilingual 覆盖 9 种编程语言;SWE-bench Multimodal 则开始纳入截图、设计稿、界面错误这类视觉信息。换句话说,AI coding 的评测不再只是“看懂 issue 文本,改出一个 patch”,而是在向真实的软件工程任务靠近。(swebench.com)
这说明行业已经意识到:真正的软件工程,不只发生在 Python 函数里;它发生在多语言、多文件、多工具、多模态、多轮验证的环境里。
为什么我说未来软件不会整体变成一次性用品?
因为过去 6 个月 AI coding 的演化方向,恰恰证明了:越往真实工程走,越需要稳定内核。
AI 确实会让很多软件的“表皮”变得廉价。一个页面、一个表单、一个内部工具、一个数据看板、一个小型自动化流程,都会比以前更容易生成,也更容易被替换。
但与此同时,AI 也在把软件工程重新拽回那些最难被抛弃的东西上:
状态责任接口验证审查追责安全评测
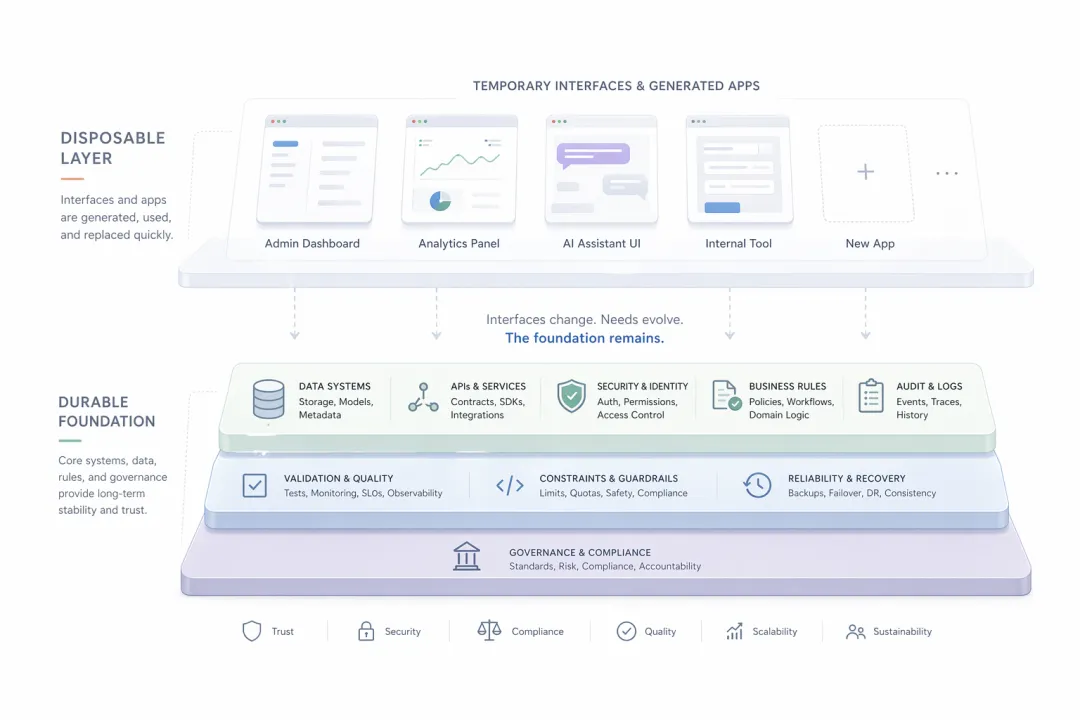
所以未来真正会发生的,不是“软件消失”,而是“软件分层”:
上层越来越像耗材,下层越来越像基础设施。
一次性的,是外壳。长期的,是内核。
从职业角度看,这对工程师也有很直接的启发。
未来工程师当然还是写代码,但更核心的价值会慢慢往这些能力上迁移:
定义问题分解任务设计上下文设计接口与协议设计测试与评测约束 agent 的工作边界负责最终判断与发布
换句话说,未来最稀缺的人,未必是“写得最快的人”,而是“能把 agent 放进正确系统里的人”。
这也是我对未来 3 年软件行业一个非常坚定的判断:
软件不会死,会死的是那些既不能被人高效使用,也不能被 agent 稳定操作的软件。
未来不会是“没有软件”的世界。未来会是一个软件外壳越来越轻、软件内核越来越重的世界。