 夜雨聆风
夜雨聆风





DeepSeek-V4实测:4000页文档一次喂饱,价格是GPT-4o的1/18
⏰ 全文约2000字,阅读需 4 分钟
不知道你在让大模型干活的时候,有遇到过这种情况吗?——
给AI投喂一份文档让它总结,结果它说”文档太长,我只看了前半部分”。
或者让AI帮你分析代码库,结果它只能看到几个你文件,理不清模块之间的关系。
憋屈不?
憋屈。
我就想问问:上下文窗口这玩意儿,到底要卷到什么时候才算个头?
好消息是——DeepSeek刚发布的V4预览版,直接把答案甩桌上了。DeepSeek-V4 预览版:迈入百万上下文普惠时代
01 百万上下文不是噱头,是真的塞得进去
先说个数字:100万tokens。
这是什么概念?
4000页书。约等于《哈利波特》全系列英文版。或者一整个30万行代码的仓库。
专家们管这叫”长上下文能力”,听起来云里雾里。
说人话就是:你这次能把整本书、整个代码库一口气扔给AI,不用分段,不用省着点用。
根据DeepSeek官方2026年4月24日发布的信息,V4预览版的百万级上下文是全系标配,不是某些高级版本才有的特权。
这一点挺实在的。
之前很多厂商的玩法是:基础版给你8K上下文,想用长的?加钱上高级版。
DeepSeek这次没玩这套。
02 价格一出来,友商沉默了
光说上下文长没用,价格才是杀手锏。
先说GPT-4o:输入$2.5/百万tokens(2026年4月刚降价),换算成人民币约¥18/百万tokens。
再看DeepSeek-V4——这次玩得更花,直接分了两个版本:
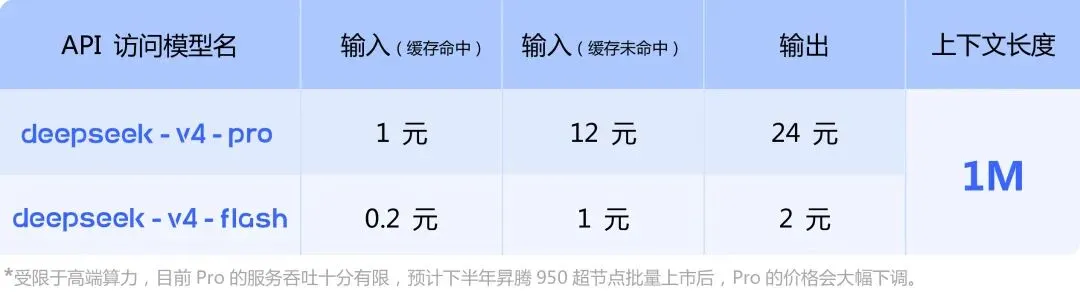
V4-Flash(轻量版) :输入¥1/百万tokens。极致性价比,适合高频调用。
V4-Pro(高级版) :输入¥12/百万tokens。性能拉满,适合复杂推理。
更狠的是——两个版本都有缓存机制。
V4-Flash缓存命中后输入只要¥0.2/百万tokens,V4-Pro缓存命中后输入¥1/百万tokens。
拿V4-Flash的常规价格和GPT-4o比,差了约18倍。如果算上缓存命中,差距拉大到90倍。
03 开发者终于能跟代码库”对话”了
说个真实场景。
假如你接手了一个30万行的代码库,前任工程师跑路了,文档也不完整。你想让AI帮你理清逻辑。
之前怎么做?
你得先问AI”这个模块是干嘛的”,它给你个回答;再问”那个模块怎么调用这个”,再给个回答。
问题在于,AI每次只能看到你扔给它的那段代码,看不到全局。
结果就是——它可能前后矛盾,或者把你的代码库当成另一个代码库来分析,驴唇不对马嘴。
现在呢?
直接把整个代码库扔进去。
让AI从入口文件开始,顺着调用链路给你讲清楚:这个函数被谁调用、那个模块依赖什么、数据流是怎么走的。
这不是我瞎想当然。
根据DeepSeek官方公布的Agentic Coding评测数据,V4预览版在开源模型中达到了最佳水平,交付质量接近Claude Opus 4.6的非思考模式。
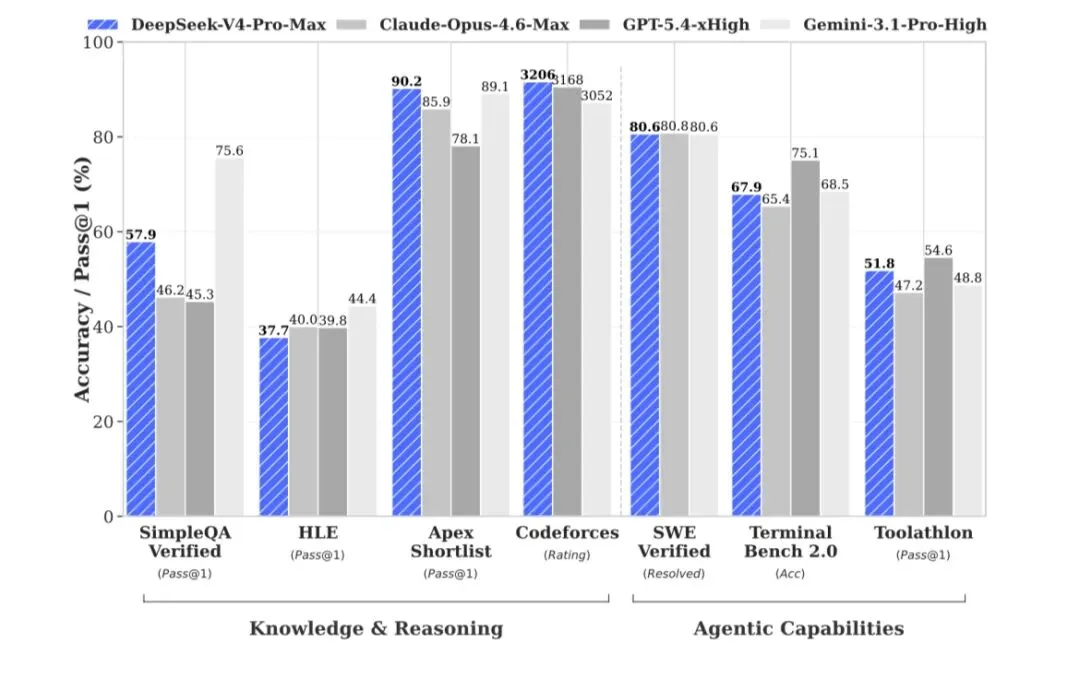
开源最佳,这个说法挺有分量。
04 企业场景:200页年报,8秒出答案
再举个接地气的例子。
做投资的人经常要分析上市公司年报。少则100页,多则300页PDF,里面全是数字和文字。
传统的做法是什么?先看摘要,再挑重点章节看,核心问题还得自己对比着找。
累不累?累。
用DeepSeek-V4呢?
直接把200页年报扔进去,问它:”这家公司的营收增长率是多少?跟同行比处于什么水平?”
官方给出的数据是:8秒内给出精准答案。
注意,是”精准”。
不是那种含糊其辞的”根据文档内容,营收增长率约为XX%”——而是直接定位到具体数字、具体段落。
不信?小白我去实测了一下。
拿宁德时代2025年年报(232页PDF:https://www.catl.com/uploads/1/file/public/202603/20260310105829_c5p2l3q9ll.pdf),直接扔进去问:”公司锂电池销量是多少?同比增长多少?“
结果——秒回,答案精准对应年报原文数据。

继续追问“深度解读下这份报告,简短回答”:



分析报告简练有条理。
这对于需要处理大量文档的岗位来说,简直是生产工具级别的提升。
法务审合同、咨询顾问看报告、分析师读财报——这些场景都能用上。
你说这东西有没有用?
我觉得不用我多说了。
05 技术上它是怎么做到的
有人可能会问:上下文长了这么多,计算量不得爆炸?显存不得爆炸?
好问题。
DeepSeek-V4用的是混合注意力机制(CSA + HCA)。
听起来很玄乎对不对?
我给你翻译一下:
传统的注意力机制,是把每个字跟其他所有字都算一遍关系。文档长了,计算量就是平方级增长。
V4的做法是——先压缩,再计算。
打个比方,你要在一本百万字的小说里找某个情节。
第一层:CSA压缩稀疏注意力——相当于”快速扫描目录”,只看可能相关的章节。
第二层:HCA高度压缩注意力——相当于”翻阅每章摘要”,确保不漏掉任何一条线索。
第三层:滑动窗口——相当于”精读当前页”,字字不漏。
这就是为什么它能在保持高质量的同时,把成本压到这么低。
技术细节我不展开,感兴趣可以去看技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf,但核心逻辑就是:聪明地偷懒,而不是傻干。
06 还有一个隐藏彩蛋:国产算力适配
很多人可能没注意到一个细节——DeepSeek-V4支持华为昇腾等国产芯片。
这意味着什么?
在美国芯片禁令的背景下,国内企业想跑大模型,要么用阉割版,要么等货。
DeepSeek直接告诉你:我适配好了,你拿来就能用。
这对政企客户来说,意义重大。
不是因为”国产”两个字就天然正确,而是因为能用、好用、不用担心供应链。
这个点容易被忽略,但我认为恰恰是影响最深远的。
07 旧模型要停用了,注意时间点
最后提醒一件事。
DeepSeek官方公告,2026年7月24日,旧模型名称(deepseek-chat、deepseek-reasoner)将正式停用。
取而代之的是新命名体系:deepseek-v4-pro和deepseek-v4-flash。
如果你之前在代码里写了旧的模型调用,记得提前改。
别等到那天系统报警了才想起来。
今天先聊到这里,下期不见不散~
😘 关注「AI小白话」,用最简单的话讲最硬的AI干货
