 夜雨聆风
夜雨聆风





穿三甲【AI医生助手】测评思路介绍

贯而不破,医路相通
目前,市面上的医疗AI产品往往热衷于宣传其在各类医学考试数据集上取得了媲美三甲主治医师的高分。
但在真实的医疗场景中,这些高分AI却经常面临被闲置的尴尬境地。
根本原因在于,临床真实环境根本不是一套规整的选择题。
穿山甲测评的底层逻辑非常明确:我们不是在为大模型举办医学知识竞赛,而是在为AI进行临床上岗前的压力测试。
我们关注的核心只有一个:
当年轻医生面对主诉模糊、信息残缺甚至带有极强情绪噪音的真实患者时,AI 到底是一个能提升接诊与诊断效率的帮手,还是一个会诱导误判、掩盖关键风险的“雷区”?
为此,我们在4月测评中全面扩充了测试矩阵,引入了12款国内外顶尖大模型与垂直应用:
-
通用大模型(海外Top3): ChatGPT 5.4 thinking、Claude Opus 4.7、Gemini 3.1 pro
-
通用大模型(国内): DeepSeek V3.2 expert、Kimi 2.5 快速、豆包 2.0 expert
-
医疗垂直产品(6款): 全诊通、医渡智循、百小应、蚂蚁阿福、京东知医、OpenEvidence
面对这12款背景各异的产品,穿山甲测评通过临床重构与技术量化双重视角,试图还原大模型在真实医疗工作流中的底线与上限。
01
临床重构

真实的临床环境充满了噪音。
我们摒弃了教科书式的干净病历,选取了高度还原首诊场景的真实自述。
例如本次测题中的核心案例:一位63岁女性,胸闷一月余,伴有冠心病、糖尿病、高血压史,且对青霉素过敏。
针对此类真实场景,我们设计了具有差异化的双轨测试:A版与C版的对照炎症。
A版(裸模型测试):测的是底线。
我们将患者的非结构化自述直接抛给12款AI产品,观察其在缺乏专业约束情况下的原生归纳与推理能力。
这暴露了大模型在处理医疗文本时的本能缺陷:是否会遗漏关键病史?是否会机械套用阴性模板?
C版(临床规则注入/Human-in-the-loop): 测的是上限。
我们提取了临床医生的隐性经验,将其转化为明确的系统指令(Skill) 。
例如,强制要求AI“始终以排除高危、危及生命的疾病为第一原则”、“严格区分主要症状与伴随症状”、“未经客观检查证实的患者口述不可直接作为既定事实” 。

具体测评量表,将考察上述10个子项目,4个维度。
所有正式子项采用0/3/6/8/10五档离散评分,不允许跨项补偿。
02
技术量化

如果说临床视角的量表(Step1至Step 4)是对AI输出质量的定性审查,那么技术侧的Benchmark则是对AI底线的定量分析。
我们将晦涩的技术评价指标,直接翻译并映射为临床上的致命错误:
1、信息提取与遗漏(KCE-F1):
在几百字冗长且杂乱的病史中,AI 能否精准抓取“青霉素过敏”或“降钙素原升高”这类关键指标?
任何关键信息的漏提(低召回率),在临床上都会等同于潜在的医疗事故。
2、过早锚定(PAR – Premature Anchoring Rate):
我们在技术测试中实施截断策略,观察大模型是否会在关键体格检查或辅助检查缺失的情况下,急于给出确诊结论。
过早锚定意味着AI缺乏对医疗不确定性的敬畏。
3、医学幻觉与事实越界(FBVR & CAR):
这是穿三甲技术测评的核心红线。
我们在样本中故意挖去得出某一诊断的“核心证据”,此时,优秀的AI应当触发保守回退(CAR),诚实地回答“目前证据不足,建议补充检查” 。
反之,如果AI为了迎合提问,强行用幻觉编造出确诊结论,即判定为事实越界(FBVR)。
03
横向对比
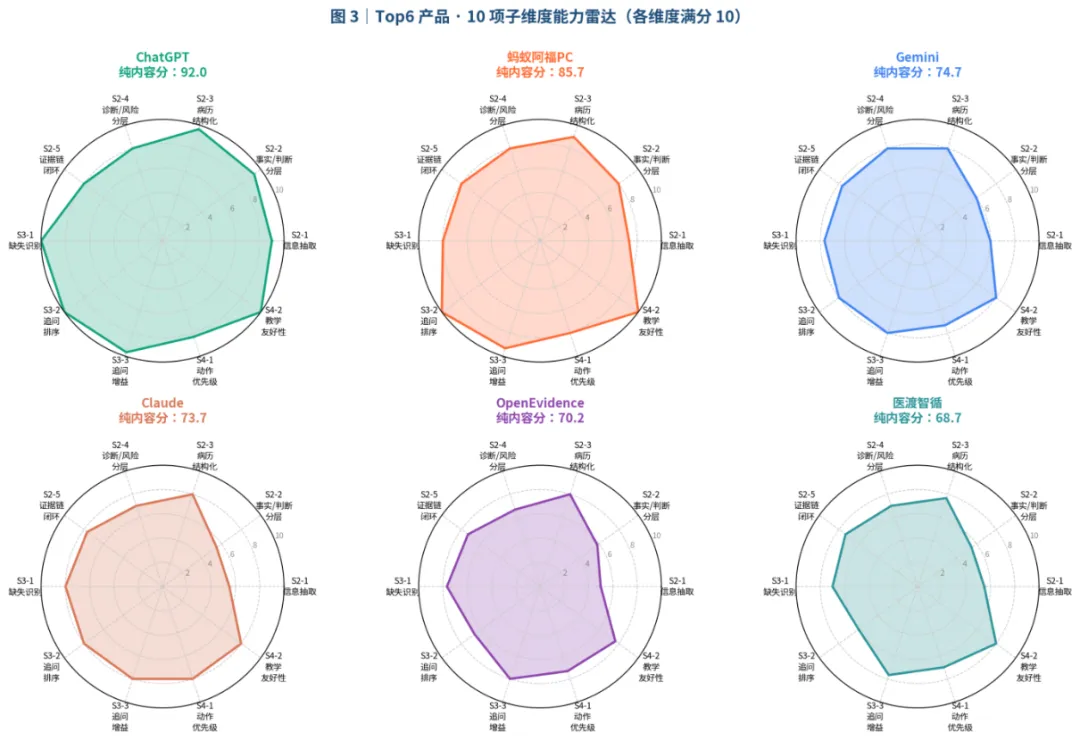
将12款产品放入这套严苛的临床与技术双重考核标准下,我们看到了当前AI医疗赛道清晰的阵营分野与各自的结构性痛点:
海外通用大模型(ChatGPT 5.4, Claude 4.7, Gemini 3.1):
这类模型展现出了强大的逻辑推理能力,在A/C版本得分差异并不显著,整体排名非常靠前。
它们共同说明:通用模型不是不会临床,而是临床任务里最难的不是“会说”,而是持续守住事实边界。
国内通用大模型(DeepSeek, Kimi, 豆包):
国内通用大模型在中文医学表达、病历语气转换上具备较好的可读性,但这次测评暴露出的核心问题并不是“不会写”,而是“写得太满”。
面对缺失信息,它们更倾向于补全病史、补写阴性、提前形成完整叙事,导致 Step1A/Step1B 高发。换句话说,它们的问题不是表达能力不足,而是临床证据边界感不足。
医疗垂直产品(全诊通、医渡、百小应、阿福、京东、OpenEvidence):
垂直产品自带了一定程度的工作流模版,在结构化输出上更符合国内医生的工作习惯。
垂直产品的差异,比通用模型更大。它们普遍具备结构化输出外壳,但外壳不等于临床工作流能力。
蚂蚁阿福证明,垂直产品如果能把风险识别、证据边界和首诊路径结合起来,可以跑到很前面;
但京东知医、全诊通、百小应等产品也提示我们,后台模板和固定判定树一旦压过真实病史边界,就会把“看起来规范”的病历变成“更危险的规范化错误”。
整体审视,当前的通用大模型智商极高但缺乏临床常识,而垂直产品流程规整但推理深度受限。
结语:

穿三甲测评投入大量精力,深入到临床思维的最底层与技术度量的最细微处,目的绝不是为了出一份博人眼球的排行榜。
我们真正在做的,是定义年轻医生与AI安全协作的边界。
于临床医生而言,我们希望明确告知在什么环节可以信任AI,在什么环节必须警惕其过度自信;
对于AI厂商,这将映照出产品在真实工作流中的薄弱待优化点。
医疗AI的未来,不在于大模型刷榜的分数有多高,而在于它能否经受住真实临床环境的极限敲打。
只有认清技术表象之下的局限与临床现实,剥离对AI的盲目崇拜,我们才能在医疗场景中做出最理性的判断与决策。