 夜雨聆风
夜雨聆风





What AI doesn’t Know Yet——企业知识管理与智能体落地的关系
我们有很大概率正处在新一轮工业革命的早期阶段(稍微保守一点),从生成式AI到代理式AI,智能体已经成为LLM(大语言模型)应用的主要形态。在企业端,智能体落地存在诸多的障碍,其中之一来自于“Context”(上下文)的缺失,美团的王兴在一次内部会议上有过很形象的比喻:
“就算爱因斯坦当秘书,让他订一个餐厅,他依然不知道那个餐厅有没有座位。这不是智力问题,而是信息问题(上下文缺失问题)。”
爱因斯坦的智力水平毋庸置疑,就像当前最先进的LLM具备强大的推理、理解能力,但如果没有足够的、精准的、实时的上下文信息支撑,它依然无法完成看似简单的企业日常任务。
于是,企业知识管理与新兴的人工智能技术有了甜蜜的交叉,这也是本文的出发点,一起聊聊企业知识管理与智能体落地的关系。
一、严格来说,我们真正需要的并非知识管理
把智能体当做知识管理的客户来看,传统的知识管理并不能完全满足智能体的需求。
从ChatGPT发布开始,一方面基础大模型的推理能力突飞猛进(GPT3.5 1750亿参数到Claude Opus 4.7约2.5-3万亿参数),另一方面在LLM之上构建智能体应用的工程方法与实践也在快速迭代。大家经常提起的Prompt工程、上下文工程、Harness工程,都是人类在驾驭LLM这匹野马的过程中,不断总结和发展的方法。
回到软件编程的基本范式IPO( Input输入-Process处理-Output输出)来理解智能体,LLM的泛化推理能力为Process处理环节提供了强大的大脑,但因为LLM本身的不确定性,所以需要我们更加严格地约束模型的输入(=Context),并通过持续评测结果(Evaluation)来实现闭环改善。
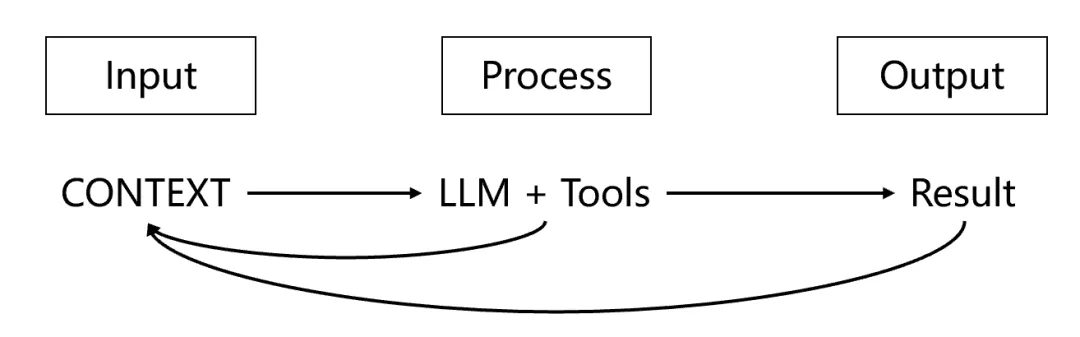
企业知识管理在这个范式中的主要使命,是为智能体提供企业私域完整、准确、及时的知识输入,这些都是在LLM预训练阶段或者通过公开数据无法获得的——What AI doesn’t Know(Yet)
那么,企业智能体落地都需要哪些Context上下文作为输入呢?
我们以一个简单的场景为例,某员工希望了解自己的季度任务达成情况,在智能体时代之前,TA可以选择咨询相应的运营或者管理人员获取,也可以通过企业自建的报表或者业绩管理系统点击查询,但在智能体时代,这个过程可能简化为与智能体的一个自然语言交互——“帮我看看这个季度的任务达成情况”
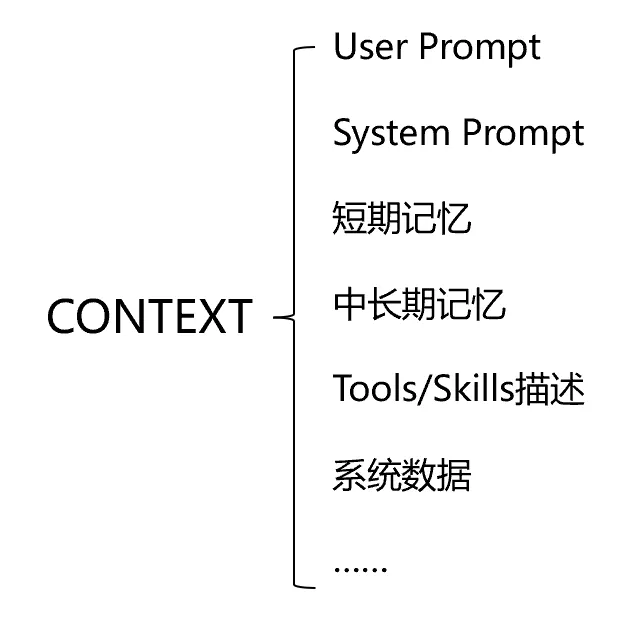
智能体在收到用户的Query后,要理解分析用户意图、规划任务执行、调用工具等等来实现,在这个例子中,智能体所需要的上下文至少包括:
-
User Prompt(用户输入指令):
即用户说的“帮我看看这个季度的任务达成情况”,但这句话可能存在歧义(比如“季度”是自然季度还是企业财季?“任务”是核心KPI还是全部任务?),因此智能体需要先对其进行意图解析,基于预设的意图理解规则进行重新改写,确保准确把握用户需求
-
System Prompt(系统预设指令):
这是工程团队在开发智能体阶段,对智能体做出的角色设定、处理方法和输出风格等约束,比如“作为企业员工专属智能助手,需简洁明了地反馈业绩数据,重点标注未达成目标的项目,不泄露其他员工的业绩信息”,这些约束会贯穿智能体处理任务的全过程
-
短期记忆(会话上下文):
在这一个Query之前,用户与智能体产生的交互信息,比如用户上一句问了“上季度的达成率是多少”,智能体需要记住这个上下文,避免用户重复说明,同时让反馈更具连贯性(比如在回答本季度情况时,可对比上季度数据)
-
中长期记忆(用户身份信息等):
用户的身份信息,比如该员工是销售岗还是职能岗?其岗位对应的任务指标是什么?;
-
Tools/Skills描述(工具调用指南):
这部分内容可能包含在System Prompt中,也可能通过动态加载等方式单独存储,核心是让智能体知道“可以调用哪些工具”“如何调用工具”“调用工具后如何分析数据”,比如智能体需要知道,业绩数据存储在企业的BI报表系统中,需要调用该系统的接口,筛选“用户ID+季度”两个维度,才能获取目标、达成、缺口等核心数据
-
系统数据(包括知识切片&查询返回数据):
如企业关于员工任务管理的相关规定切片(季度任务的计算标准、达成率的统计口径、未达成的处罚规则等),以及智能体调用工具后获取的实时数据,比如该员工本季度的核心KPI目标是100万,实际达成85万,达成率85%,其中某一项子任务未达成等,这些实时数据是最终输出反馈的核心依据
了解智能体所需的上下文之后,我们再回头看传统的企业知识管理:传统知识管理的主要工作,是通过任命知识官、构建专家网络、建设和维护知识库与知识社区,实现高价值知识资产的显性化与复用——比如将企业的规章制度、操作手册、案例经验等,整理成文档,存储在KMS系统中,供员工查询使用。
对比智能体所需的6类上下文,我们会发现:在刚才场景举例的所有Context中,直接相关的只有向量库的原始文档提供,对于User Prompt的意图解析规则、System Prompt的约束设定、短期记忆的管理、Tools/Skills的描述等几乎无法覆盖,这也就意味着,企业智能体落地真正需要的,是完整的上下文管理(Context Management),知识管理只是其中的一个环节,并非全部。
这是企业知识管理在智能体落地过程中的一个挑战,提供完整、准确、及时的知识文档已经足够挑战,但并没有办法解决智能体的全部输入需求,因此无法对最终的输出负责。
二、AI时代的企业知识管理:从For/By Human到For/By AI
虽然“企业知识管理≠智能体所需的上下文管理”,但这并不意味着企业知识管理失去了价值。在AI时代,我们需要对传统的企业知识管理进行真正意义上的升维:
By Human→By AI:一方面,从知识创造的维度,生成式AI的特性是天然适配的高产知识创作者,但也存在内容同质化、版权问题、原创能力流失、质量不可控等等问题,知识管理要解决AI创作的效率提升、质量管控和价值实现问题;
For Human→For AI:另一方面,更为重要的是从知识消费的维度理解,未来知识工作的主要主体是智能体完成(目前Google大约75%的新代码是AI生成),知识管理的主要服务对象将是AI,我们需要清洗、标注、结构化、向量化等方式,将组织已经沉淀的知识资产尽快转化为AI可用的知识,并最终迈向AI 自主创造新知识、同时 AI 之间互相消费、迭代、反思、优化的自演进之路。
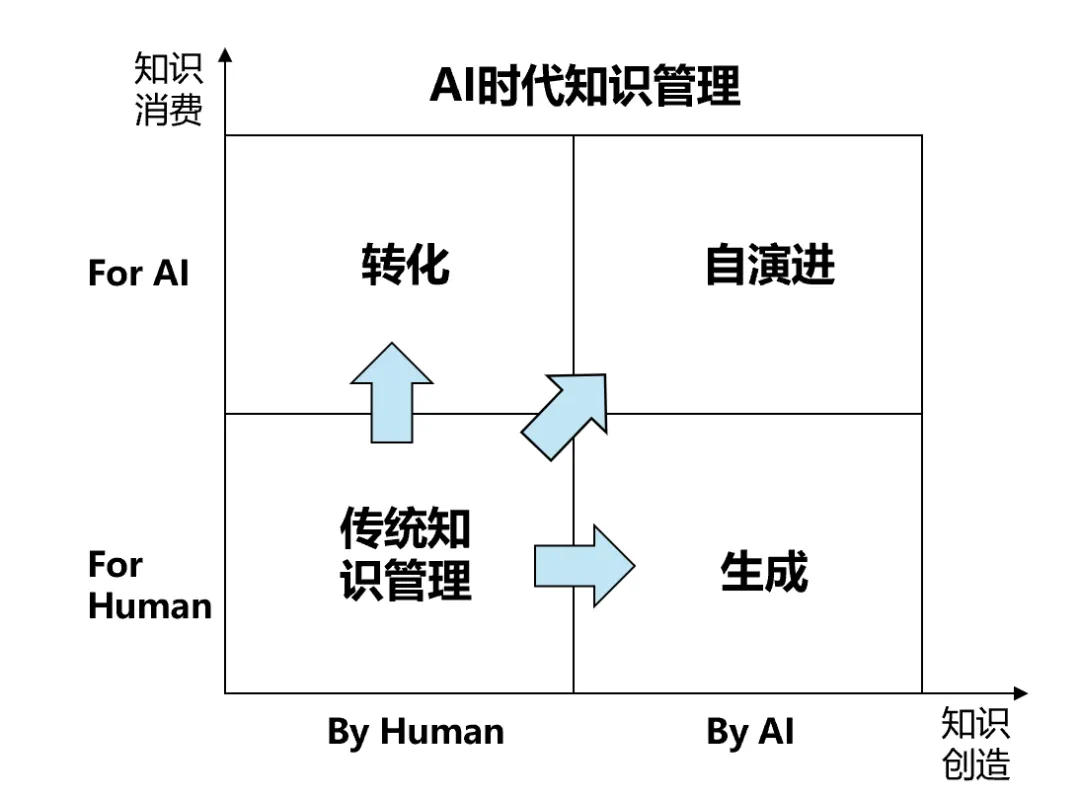
传统知识管理拓展为AI时代知识管理后,企业就可以充分利用现有的知识基建与知识资产、降低智能体落地成本,并且将新的知识创造螺旋纳入到知识管理范围,从而支撑智能体的长期迭代。
1、知识基建与资产的复用,降低智能体落地成本
在企业引入智能体项目之前,绝大多数企业已经存在不同程度的知识管理活动——无论是大型企业的标准化KMS系统、知识库,还是中小型企业的共享文档、钉钉/企业微信中的知识沉淀,本质上都属于企业的“知识基建”;而那些已经完成编码化的知识文档(如规章制度、操作手册、产品说明、案例库等),则是企业的核心“知识资产”。
企业在推进智能体项目时,可以思考如何“盘活存量”——最大化现有知识基建与资产的价值,将其适配为智能体可调用的上下文。比如,企业已有的员工手册、任务管理规定,无需重新撰写,只需通过RAG技术进行切片、向量化处理,存入向量库,即可成为智能体所需的“中长期记忆”。这种存量资产的复用,能大幅降低智能体落地的研发成本和时间成本,让智能体更快具备“理解企业私域知识”的能力。
2、新的知识创造螺旋构建,支撑智能体长期迭代
知识的价值,从来不是“存储”,而是“流动与创造”。日本学者野中郁次郎提出的SECI模型(S-社会化、E-外显化、C-组合化、I-内隐化),描述了知识的循环创造过程:隐性知识(如员工的经验、技巧)通过社会化分享,转化为显性知识(如文档、手册);显性知识通过组合、整理,形成新的知识体系;新的知识体系被员工吸收、内化为隐性知识,再通过实践产生新的隐性知识,形成一个持续循环的知识创造螺旋。
企业部署智能体后,一方面,智能体成为知识的“消费大户”——它需要持续获取知识,才能完成各类任务;另一方面,智能体也会成为知识的“创造者”——比如它可以基于员工的交互数据,总结出更高效的任务处理方法,生成新的Skills(技能),或者将零散的知识片段组合成新的知识文档。
而这个新的知识创造螺旋,依然需要企业知识管理的支撑:智能体生成的新技能、新知识,需要通过知识管理流程进行审核、整理、沉淀,避免错误知识的传播;员工与智能体交互过程中产生的新需求、新疑问,需要通过知识管理运营人员的梳理,转化为新的知识内容,补充到知识体系中……
简单来说,智能体让知识的创造和流动变得更快,但也更需要知识管理来“把关”和“沉淀”——没有知识管理的支撑,智能体生成的知识可能零散、错误,无法形成持续价值;而有了知识管理,才能构建起“人类创造知识→智能体复用知识→智能体生成新知识→人类/智能体共用知识”的新螺旋,支撑智能体长期迭代,让它越来越“懂”企业。
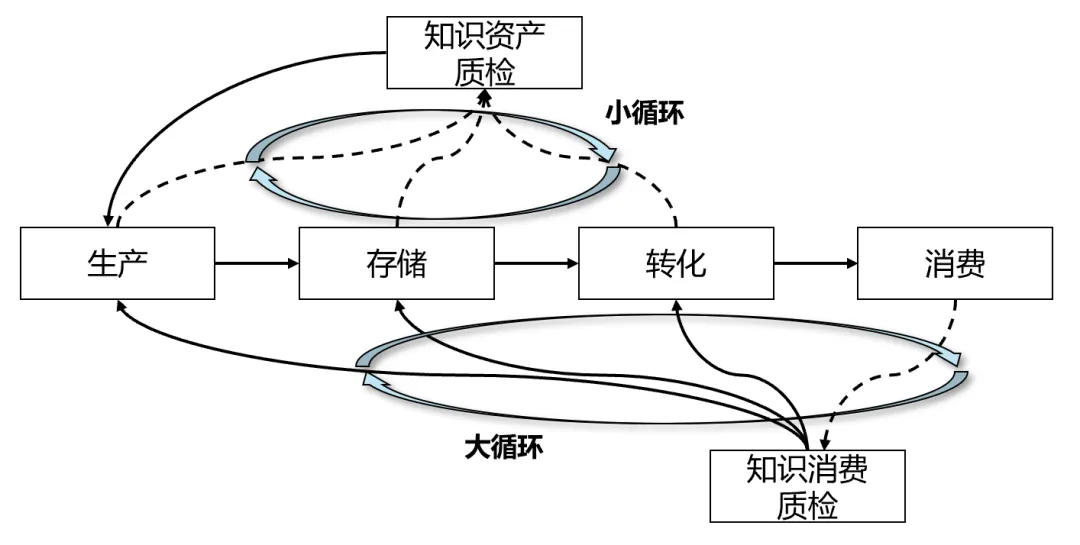
三、做好企业知识管理的大小循环
企业落地智能体的失败率依然很高,企业知识管理与智能体项目的合作存在诸多挑战。通过过去一段时间的知识管理实践,以及与许多智能体项目的合作,我发现做好企业知识管理、适配智能体落地,关键不在于“建设更庞大的知识库”,而在于在知识生产→存储→转化→消费的链路之上,构建两个相互联动、闭环运转的循环——我称之为知识管理的“大循环”与“小循环”。
小循环:从知识供给端,围绕业务需求,建立知识识别、内容质检、准入标准、定期更新、失效淘汰的全流程规则,从源头把控内容质量,杜绝无效、过期、错误信息输入,筑牢 AI 应用基础。
大循环:从知识消费端,实时监控智能体线上使用场景,收集Bad Case,反向追溯知识缺陷,针对性优化内容、调整调用规则,以实际业务使用效果倒逼知识体系持续优化,以终为始、以用为尺,闭环改善。
写在结尾
智能体时代,企业知识管理正在迎来范式升级:不再只服务于人,而是转向为 AI 服务,承担(部分)上下文治理、私域知识供给的核心作用。夯实企业知识底座,才能让智能体深度融入业务,实现人机协同,持续为企业创造价值。