 夜雨聆风
夜雨聆风





这个软件让你快速拥有任何人的声音
💡 Voicebox:一款开源、本地运行的 AI 语音工作室。它被视为 ElevenLabs 的终极开源替代方案,支持 23 种语言,集成了语音克隆、TTS(文本转语音)、STT(语音转文字)以及多轨音频编辑功能,且所有数据都在本地处理,确保极致隐私。

🎬 效果演示
以下是使用 Voicebox 克隆声音后的实际转换效果演示。你可以听到 AI 在保持原声音色的同时,自然地处理了语气的起伏。
演示视频:原声素材与 AI 克隆生成的对比
💡 为什么选择 Voicebox?
在 AI 语音领域,ElevenLabs 虽强但价格昂贵且依赖云端。Voicebox 的出现打破了这一现状:
·完全本地化:无需联网,保护你的声音隐私,不被云端训练利用。
·零样本克隆:只需上传一段 10-30 秒的清晰录音,即可像素级还原目标音色。
·全能集成:内置 7 种 TTS 引擎,支持混响、延迟、音高调节等 8 种后期特效。
·跨平台支持:支持 macOS (M系列芯片优化)、Windows (NVIDIA GPU 加速) 和 Linux。

🛠️ 安装与初始化
1. 下载当前最新版本
前往 Voicebox 官网 或 GitHub Releases 页面下载。 – Windows:下载 .msi 安装包。 – macOS:下载 .dmg 安装包(推荐 M1/M2/M3 用户)。
注:安装程序将引导你完成基础环境配置
2. 模型下载管理
首次启动后,进入 Model Management。为了获得最佳效果,建议优先下载: – Qwen3-TTS (1.7B):核心生成模型,质量最顶尖。 – Whisper Turbo:用于超快速的语音转文字。
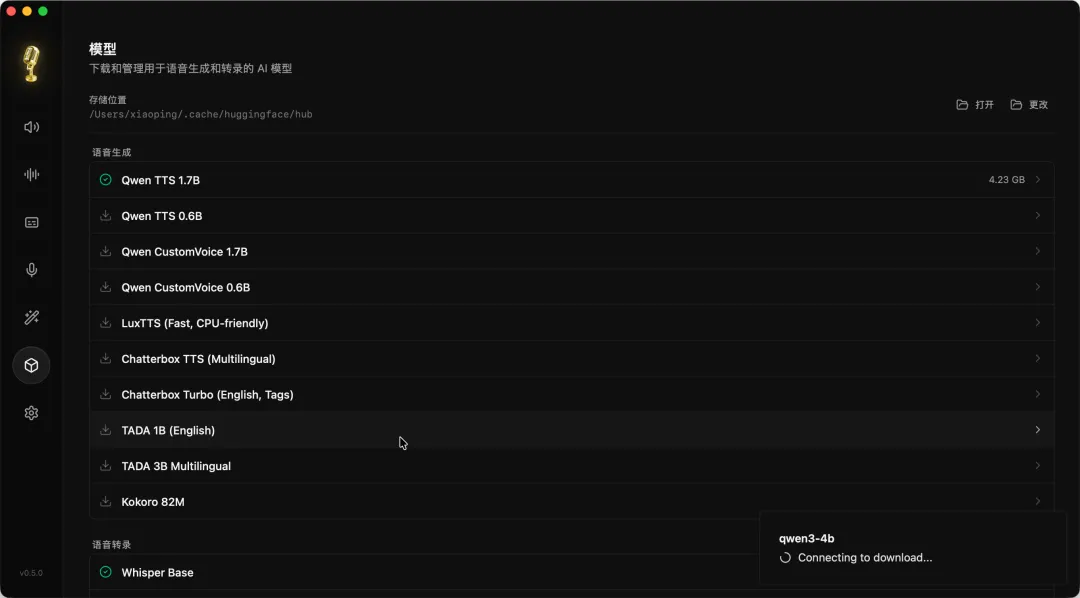
注:本地模型下载,一次下载,终身免联网使用
🎙️ 极致克隆:如何获得“本尊”音感?
创建“语音人格(Voice Profile)”时,样本的质量决定了最终的上限。
1. 多样化的录音方式
Voicebox 提供了极其灵活的样本采集方式: – Upload File:上传已有的高质量音频(如录音笔素材)。 – Record Mic:直接对着麦克风进行实时录音(建议环境安静)。 – System Audio:神器功能!可以直接抓取电脑系统发出的声音进行克隆(例如克隆视频里的旁白)。
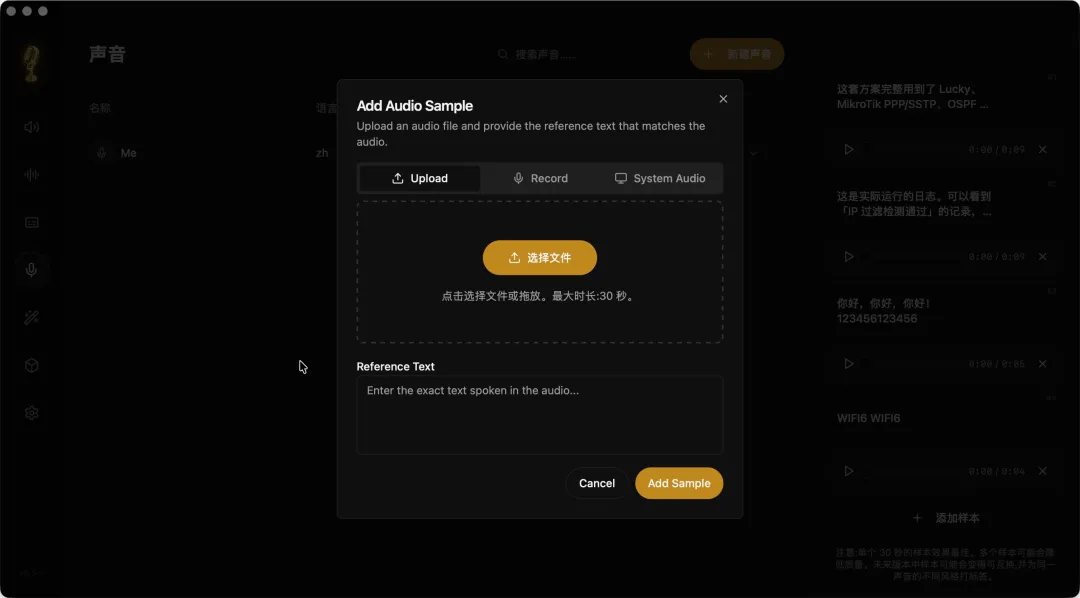
注:支持多种输入源,甚至可以直接克隆系统当前播放的声音
2. “语义驱动”调优技巧
Qwen3-TTS 具备语义理解能力,你不需要调节参数,而是直接用文字描述语气:
-
指令示例:输入 [Speak like a calm British narrator, slightly empathetic, with a slow pace.]。
-
情感标签:在文本中插入 [whisper](耳语)、[laugh](大笑)或 [sigh](叹气)。

💻 开发者进阶:MCP 智能体集成
通过 MCP 协议,你可以让 Claude 或 Cursor 直接用你的声音说话。
1. 快速接入
执行以下命令,将 Voicebox 添加为 MCP 节点:

2. 真人感设置
-
·personality: true:开启后,Voicebox 会先将 AI 的回复进行“口语化”改写。
-
·instruction:预设一段语音人格描述,如“始终保持热情且礼貌的语气”。

⚠️ 硬件建议与优化
-
显存要求:Qwen3-1.7B 建议 6GB 以上显存。若硬件较低(如 8GB 内存的旧款 Mac),建议选择 LuxTTS 或 Kokoro 引擎,生成速度会大幅提升。
-
自动加速:Voicebox 针对不同平台进行了深度适配。Mac 用户无需手动配置,软件会自动利用 MLX 框架调用 Apple Silicon 的统一内存进行加速;Windows 用户只需确保安装了最新的 NVIDIA 驱动,软件即可自动识别CUDA 环境。
-
性能监控:如果生成速度较慢,请检查是否同时开启了多个占用 VRAM 的大型应用(如剪映或 3A 游戏)。

🛠️ 项目地址:https://github.com/jamiepine/voicebox
如果这篇文章对你有帮助,欢迎点赞分享!
注:请在法律允许的范围内使用语音克隆技术,尊重他人版权与隐私。