 夜雨聆风
夜雨聆风





AI Agent – 不是魔法
Pi-Agent (龙虾用的 Agent)的作者在他最近的博客 https://mariozechner.at/posts/2026-04-08-ive-sold-out/ 中提到,去年的时候,他们有个朋友突然发现 AI Agent 很好用,然后他们几个人也都去申请了 Claude Code 的账号,用上了 AI Agent,然后……他们就不怎么睡觉了。
最近几个月我们团队也逐渐从 IDE + AI 为主的方式,切换到 Terminal + AI Agent 为主的模式。我晚上回家、周末也都有点停不下来。我们组的同事,包括产品经理也都表示,工作时间不自觉地就延长了。
AI Agent 如此有吸引力,这次就来聊一聊吧。
## AI Agent 不是魔法
从 Chatgpt-3.5 时代,我们就开始赞叹 AI 的知识、智能,各大公司也一直在探索如何有效地将 AI 的智能充分利用起来。刚开始的时候各种媒体的宣传方向是:大模型(本身)会变的无所不能。大模型的发展的确是朝着越来越厉害的方向发展,但 AI 显然并不是无所不能,比如他的算数能力就不太行,到现在为止也只能进行简单的计算。因此现在依然会有许多人,通过吐槽 AI 的缺点以博眼球。但我们作为实用主义者,就得从实用的角度考虑:给 AI 一个计算器,不就好了?
所谓 AI Agent,就是给 AI 提供了一些工具,让 AI 可以通过这些工具,能完成更多的事情。
那这个过程具体是如何发生的呢?我们来仔细地看看。
首先,大模型发展了这么些年,核心的工作机制并没有变化,那就是根据已有内容预测下一个词(更准确的说是下一个 token)。我们稍微把这个能力抽象一下,那就是大模型能够“讲话”。它能够讲各种语言,包括自然语言,以及软件用到的编程语言,尤其是 结构化的数据语言 (JSON)。
太好了,既然它能输出结构化的数据,那就可以和常规的软件打交道了。比如它需要计算 1234567 x7654321,他自己的算数能力肯定搞不定,我们就告诉它:你可以用计算器。这下就好了,它就只需要说(使用结构化的数据):计算乘法 1234567 x 7654321。然后执行一下计算代码,结果就出来了:9449772114007。这样大模型就能准确的回答你的问题了。这中间涉及到多次大模型 API 的调用,过程是这样:
-
你在 Agent 软件中向大模型提问(LLM 调用),大模型输出结构化的内容
-
Agent 软件捕捉到大模型的结构化输出,计算出结果
-
Agent 软件将聊天记录+计算结果提供给大模型(LLM),大模型输出最终结果
太棒了, Agent 原来这么简单!
我用 AI 画了张原理图,可以看看:
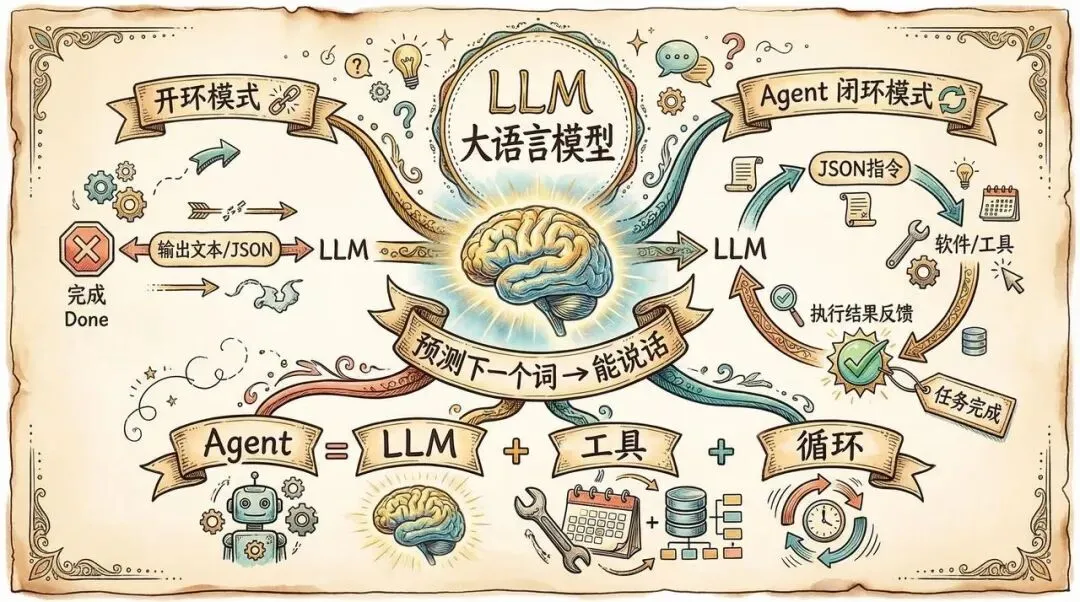
原理就是这么个原理,但要做好肯定是相当不容易。在模型侧,大模型公司得训练模型,让它能够更懂得使用外部工具的模式;在 Agent 工具侧,得配合模型,做出相关的解析工作,并且得处理不规范的情况(LLM 的输出不如常规软件可靠),以及上下文管理等等,总之有很多东西。
## 如何用上靠谱的 AI Agent 的
不太想写这一段,时效性太强,过两个月回头一看可能就已经变的了。
简单点来说:AI 三巨头(OpenAI,Anthropic,Google)的 Agent 工具搭配自家模型都不错, Claude Code 处于明显领先的地位。
模型最重要:我目前的主力模型是 Claude Sonnet,性价比最好,需要处理困难问题的时候就上 Claude Opus。
Agent 工具次之:Claude Code,Codex,Antigravity 其实都还不错的。不过我选用的是 pi-agent,简单、透明,能力也不弱,支持的模型供应商也很广泛,还可以自己扩展。另外我非常同意 pi-agent 作者的观点,agent 工具就不应该做的太复杂,毕竟模型能力才是关键。
买用哪家的账号呢?OpenAI,Claude Code 这两家封号特别严厉,不太建议搞官方账号,工作中无法接受做到一半卡住。Google 封号不严格,但我多年的老账号,承受不起封号的风险。因此,我买的是 github copilot,微软背书,提供了所有前沿的模型,量大可靠不封号,而且各种工具对 github copilot 的支持都非常到位。
呼应一下这一段的开头,文章还没写完发布,情况已经变了。龙虾没那么火了。最近 cladue 明显降智,官方都承认了,我最近用 gpt-5.4 比较多。github copilot 新订阅停止了,已有的订阅还能用。另外 deepseek v4 也已经发布了,聊天体验下来效果不错,能到 T0 级别,但还没试过写代码。
## 用 AI Agent 可以干嘛
AI Agent 和普通的 AI 提问相比,最重要的就是可以使用外部工具 – 尤其是软件工具。因此我们用 AI Agent 的时候,显然是希望它做点什么。
(PS:再提醒一下,从现象来看,是 AI 使用外部工具,但实际上是常规软件解析 AI 的结构化输出,然后进行工具的执行。理解了这一点,你就比大部分人更懂 AI Agent。)
在可预见的未来,处理工作相关的内容,尤其是编程的相关场景,会是 AI Agent 的主要方向。道理很简单,这是 最大的付费场景,有人给钱,厂商才有真正的动力去投入开发。不要小看编程的场景,信息社会是建立在代码的基础上的,也就是说,AI Agent 通过写代码,可以完成的事情可能会超出你的想象。
我直接让 DeepSeek V4 帮我列了一些,多点例子,更容易帮你理解:
等级 1:仅写代码(纯生成,无外部输入)Agent 只靠自己的模型知识写代码。离线、自给自足。* 写一个完整的游戏(贪吃蛇、扫雷、2D RPG)* 生成一个个人网站/博客(静态页面,单文件部署)* 写一个正则表达式测试工具(HTML 单文件)* 生成 LeetCode 刷题笔记 + 每题的多种解法* 写一个加密/解密工具(AES、RSA 的纯实现)* 写一个文件格式转换器(JSON ↔ YAML ↔ TOML)* 手写一个极简数据库(B-tree, LSM 都行)* 写一个 Markdown 预览编辑器(单文件)* 生成算法可视化(排序、寻路、图遍历的动画)* 写一个 Brainfuck 解释器* 用代码生成 SVG 艺术 / 分形图案* 写一个编译器(把自创的迷你语言编译到 JS/Python)* 给一个开源项目写完整的单元测试* 写一个代码混淆器 / 反混淆器* 用 Canvas 写一个粒子物理模拟⠀等级 2:搜索 + 写代码(线上信息采集与加工)Agent 有了眼睛。能搜资料,然后基于结果写代码。* 爬取某类商品全平台价格,生成比价报告* 抓取某个 GitHub topic 下所有仓库,按活跃度/质量排序* 监控某个法规/政策页面,变动时自动生成 diff 摘要* 搜索"某个技术最新的最佳实践",汇总并写成一个 demo 项目* 跟踪某个竞品的所有招聘岗位,反推他们的技术栈和战略方向* 收集某领域近 5 年的论文标题 + 摘要,做趋势聚类和热点迁移图* 实时抓取多个新闻源,对同一事件做叙事对比(谁报了什么、谁没报)* 搜索某个人的所有公开信息,生成一份结构化的"数字足迹报告"* 监控学术期刊的 retraction 通知,建一个"被撤回论文"数据库* 抓取某城市所有在售房源,交叉分析学区、交通、价格异常* 搜索所有公开的 bug bounty 报告,分析某类漏洞的常见模式* 抓取社交媒体上关于某个话题的所有帖子,做情绪时间序列* 建立"某行业所有公司的融资/倒闭"时间线⠀等级 3:调用公共 API(利用现有平台工具)Agent 能接上已有生态。不只读,还能做事。* GitHub API:自动给项目发 PR(修 typo、修 bug、改进文档)* Stripe API:搭一个完整的付费订阅系统* Twilio API:写一个电话通知系统(服务器挂了打电话)* SendGrid/Resend:搭建完整的邮件营销自动化流程* Notion API:把散落信息自动整理成结构化知识库* Slack/Discord API:做一个能回答团队内部问题的 bot* Google Maps API:优化配送路线 / 找某个区域所有同类店铺* OpenAI/Claude API:写一个"批量 AI 处理流水线"(如 1000 篇文章摘要)* Shopify API:自动管理商品、库存、订单* Airtable API:把任何非结构化数据变成可查询的数据库* Twitter/X API:自动发推、自动回复、分析传播路径* Cloudflare API:自动配置 DNS、防护规则、边缘函数* Vercel/Railway API:代码写好直接部署上线,形成闭环* 日历 API:自动协调多人会议时间,不用来回发邮件* 微信支付/支付宝 API:给个人项目加上收款能力等级 4:Agent 原生 API(厂商为 Agent 定制的能力) 这是未完全到来但正在出现的一层。API 的设计理念变了——不是给人用的 SDK,是给 Agent 用的、语义化的、可组合的接口。* 浏览器 Agent API — 不是 Selenium/Puppeteer 那种选 DOM,而是"帮我在这个网站完成退货流程",浏览器厂商直接暴露语义操作* 认证代理 API — “用我的身份登录这个服务”——不再传 cookie 或 token,Agent 通过一个统一认证网关操作所有服务* 支付代理 API — “支付这笔钱,在以下条件满足时”,Agent 不需要知道信用卡号,只是发起意图* 银行 Agent 端点 — 不只是"查询余额",而是"分析我过去一年的订阅支出,找出哪些该取消,帮我取消并生成报告"* 政府 Agent 接口 — “帮我注册一家公司”——一个 API 调用背后是工商、税务、社保的联动,而不是你手动填 20 个表* 医疗 Agent 网关 — Agent 拿着你的症状描述和病历,跨医院预约、调报告、对比医生排期* 物流 Agent API — “寄这个东西到那里,选最便宜的/最快的”——多家快递统一抽象* 法律 Agent 接口 — “帮我审查这份合同的风险条款"返回的不是文档,是结构化的风险树* 教育平台 Agent 端口 — 不只是看课程列表,而是"根据我的知识盲区生成一条学习路径并自动注册”* IoT Agent 层 — “如果摄像头检测到有人,开灯并发通知”——不需要写 if-this-then-that,直接描述意图* 数据市场 Agent 接口 — “我需要这些数据,按此粒度、此频率、此格式”——自动对接多个数据供应商报价* 企业内部的 Agent 总线 — HR、财务、法务、IT 各系统不再各自暴露 UI,而是暴露 Agent 可调用的语义接口* 城市基础设施 Agent API — 查交通流量、空气质量、公共设施使用率,不是给 App 用的,是给 Agent 做决策用的* “权限委托 API” — 用户可以设置"允许 Agent 做这些事,但每次超过 X 元需要我确认"——本质是能力银行* 社交平台的 Agent 层 — 不只是发帖 API,而是"代表我与某某类型的人建立真实联系"
## 上下文缓存 – 必省的成本
前面的环节中,提到了 AI Agent 会涉及到多次 AI 调用,并且每次调用,其实都会把前后的所有内容都发送给大模型。那么问题来了,AI Agent 如果中间调用 5 次工具,那前面的所有内容会被反复发送 5 次,那这 token 消耗不得起飞?厂商们当然想到了这个问题,解法就是上下文缓存技术。
我们来做这么一个思想实验:我们人解决一个问题,一步一步来,中间需要的时候就去查相关的信息,然后接着做。AI Agent 的工作方式其实也一样,一步一步来,中间需要的时候我们把信息塞给它。但 AI Agent 的工作方式决定了,在等待外部软件运行的时候,服务器不会真卡在那里等着你输入信息,算力马上就被分配到别的任务上了。那怎么办?把刚才已经处理过的内容缓存下来。
大模型也就是个 API 调用,有输入,有输出。每次输入的内容,都需要进行一次复杂的运算,然后再计算输出内容。如果我们知道这些内容后面还会再用到,我们就可以把处理过后的输入内容,直接缓存起来,下次直接加载这个缓存内容,就不用重新计算一遍,这样可以节省很多算力。
所以如果你对大模型的 API 价格有了解,肯定会注意到三种 token 价格:输入(无缓存),输入(缓存命中),输出。输入缓存命中时,token 价格可以达到未缓存的十分之一,甚至更低。
这样 AI Agent 的多轮工具调用,成本就可以降低非常多。
这次 DeepSeekV4 的发布,我认为一大亮点就是缓存做的非常好,默认全量缓存,价格便宜,缓存时间几个小时到几天,吊打市面上的所有厂商。
偏技术的部分讲完,就来说说实用的。比如我们要选 Coding AI Agent,都按 token 计费,除了考虑 AI 能力,重点也要考虑缓存做的好不好,缓存做的不好,那你经常会白白浪费掉许多 token。比如 Anthropic 的 Claude Code,默认会启用强缓存,但也才 1 个小时。如果你的一次会话中间间隔了一个小时,那不好意思,得多收一次钱。
另外缓存技术的强诉求,会给聚合 AI API 供应商提出较大的挑战。一般这种供应商背后都是有个账号池,按需灵活分配。问题在于,一旦背后的账号发生了切换,缓存就失效了,非常不划算。
## 就到这里吧
原本计划了更多的内容,但考虑到本篇的内容已经够硬核,剩下的内容下次再写。其实下次的内容,才是我想写的重点内容,那就是:问题-思维模式-工具。
下次见。