 夜雨聆风
夜雨聆风





国产AI大模型GLM-5.1登顶获得多项佳绩
国产AI大模型GLM-5.1登顶获得多项佳绩

根据截至2026年4月27日的公开资料显示,智谱的GLM-5.1 在多个权威AI评测榜单中表现突出,尤其在编程能力和开源模型领域位居前列。以下是其主要排名情况:
1、编程与工程能力排名:
1)SWE-Bench Pro(真实软件开发Bug修复能力):
全球第1名(开源模型中第一),得分 58.4,超越了 GPT-5.4(57.7)和 Claude Opus 4.6(57.3)。
2)Code Arena(LMArena百万用户盲测编程专项):
全球第3名,开源模型第1名。
3)Terminal-Bench2.0 + NL2Repo(命令行操作与从零构建代码仓库):
全球第3名,国产第1名,开源第1名。
4)Design Arena(模型设计能力):
全球第4名,开源第1名。
2、文本与通用能力排名:Text Arena(文本理解与生成):
开源模型第1名。
1)数学能力(AIME 2026):
得分 95.3,与前代 GLM-5 基本持平,但低于 GPT-5.4(98.7)。
2)NL2Repo(仓库生成):
得分 42.7,显著低于 Claude Opus 4.6(49.8)。
3、结论
GLM-5.1 是当前全球最强的开源大模型之一,尤其在编程、长程任务、工程自动化方面表现卓越,在综合能力榜单中,其全球排名约为第3位,仅次于 GPT-5.4 和 Claude Opus 4.6 。数学、法律、医疗等非编程领域有所弱化,属于“偏科型”模型,优势集中于代码与Agent任务。
全球权威AI评测平台LMArena(百万用户参与盲测)更新Code Arena专项榜单,GLM-5.1登顶全球开源模型第一,位列全球模型第三。
除了榜单表现优秀,根据智谱的说法,GLM-5.1不仅继承了上一代模型的开源SOTA编码能力,还在长程任务(Long-Horizon Task)上取得突破,实现了:
·8小时从零构建Linux桌面
·655次迭代打破向量数据库优化瓶颈
·1000轮工具调用优化真实机器学习模型负载
在METR榜单的同等评估标准下:
GLM-5.1是唯一达到8小时级持续工作的开源模型,也是全球范围内除Claude Opus 4.6外少数具备这一能力的模型。
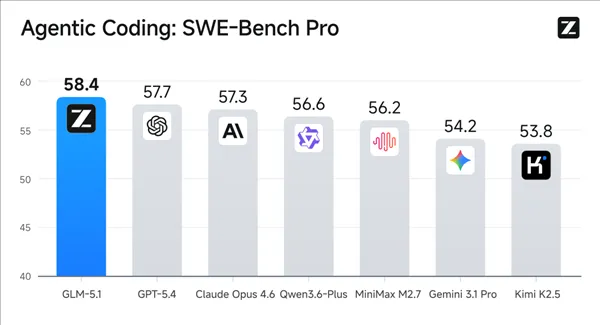
GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。
在最接近真实软件开发的SWE-bench Pro基准测试中,GLM-5.1刷新全球最佳成绩,超过GPT-5.4、Claude Opus 4.6。SWE-Bench Pro要求模型在真实GitHub仓库中定位并修复高难度工程Bug,是衡量模型能否胜任专业软件开发的最硬指标。
