 夜雨聆风
夜雨聆风





修改一条配置,我缓解了 OpenClaw 的偶发性痴呆
最近我在用 OpenClaw 跑一个多 Agent 的内容生产流程。这个流程本身不复杂:`director` 负责总调度,`scout` 负责信息采集,`analyst` 负责选题筛选,`editor` 负责内容协作。
但在真实使用过程中,我遇到了一个很难受的问题:
Agent 会偶发“发呆”。
这里的“发呆”不是某一个渠道特有的问题。它在 Telegram、飞书、企业微信等多个渠道里都能复现,但是是偶现。最典型的表现是:
– 某个阶段明明已经完成
– 用户也已经给出了下一步指令,比如“定稿”或“继续”
– 主调度 Agent 却停在原地,像没收到一样
– 过几分钟后,或者你再补一句“继续”,它又恢复了
这类问题非常容易被误判成渠道问题、网络问题,或者模型响应慢。但如果只停留在表象,就很难真正解决。于是我开始系统排查这件事。
一、问题发现:不是“没执行”,而是“执行链被打断了”
最开始我的直觉是模型限速,或者某个渠道对长消息、群消息的处理不稳定。
但对照日志之后,我很快发现,问题不是这么简单。
首先,消息本身是正常进入系统的。
其次,子 Agent 也确实在工作,`scout`、`analyst`、`editor` 都能在对应日志里看到实际执行记录。
真正异常的地方在于:
主调度 Agent `director` 在一些关键交接点上,被内部消息打断了。
比如一个典型场景是:
– `editor` 已经完成了 Step3 草稿撰写的操作
– 系统也已经把“草稿完成,请确认”发给了用户
– 用户回复了“定稿”
– 按理说,流程应该直接进入 Stage 4
但日志显示,在这个时间点附近,`director` 并不只收到了用户的“定稿”,它同时还收到了来自内部 Agent 的完成通知,以及一些像 `NO_REPLY`、`ANNOUNCE_SKIP` 这样的控制信号。结果就是:用户的真实指令和系统内部的控制消息混在了同一条会话里,主流程节奏被扰乱了。
所以问题不是“模型没干活”,而是“系统在错误的时机,把错误类型的消息送进了主会话”。
二、问题分析:多 Agent 协作并不只有一条简单调用链
把日志和源码对起来看之后,我意识到,OpenClaw 的多 Agent 协作远比“一个 Agent 调另一个 Agent,拿结果返回”复杂。
至少在这个问题里,系统内部同时存在两条消息链:
1. `sessions_send` 触发的 **Agent-to-Agent 通信流**
2. 子任务完成后的 **subagent completion announce 流**
第一条链路的特点是:
`director` 把任务派给子 Agent 之后,系统并不是只等一个结果回来,而是会在拿到 `reply` 后,再跑一轮 Agent-to-Agent 通信流,用于内部补充、确认和最终 announce。
第二条链路的特点是:
子 Agent 完成任务后,系统会把这次完成包装成 `task_completion` 事件,再决定是直接投递,还是先进队列,稍后再送回主会话。
单独看,每一条设计都有合理性。
但当主会话仍然处于活跃状态,而用户又恰好在这个时间点发来新消息时,问题就出现了:
– 用户消息正在进入 `director`
– 子 Agent 完成通知也正在进入 `director`
– Agent-to-Agent 通信流里的内部控制消息也可能进入 `director`
这样一来,主调度会话看到的上下文就会被污染。
下面这个时序图,比纯文字更容易说明问题:
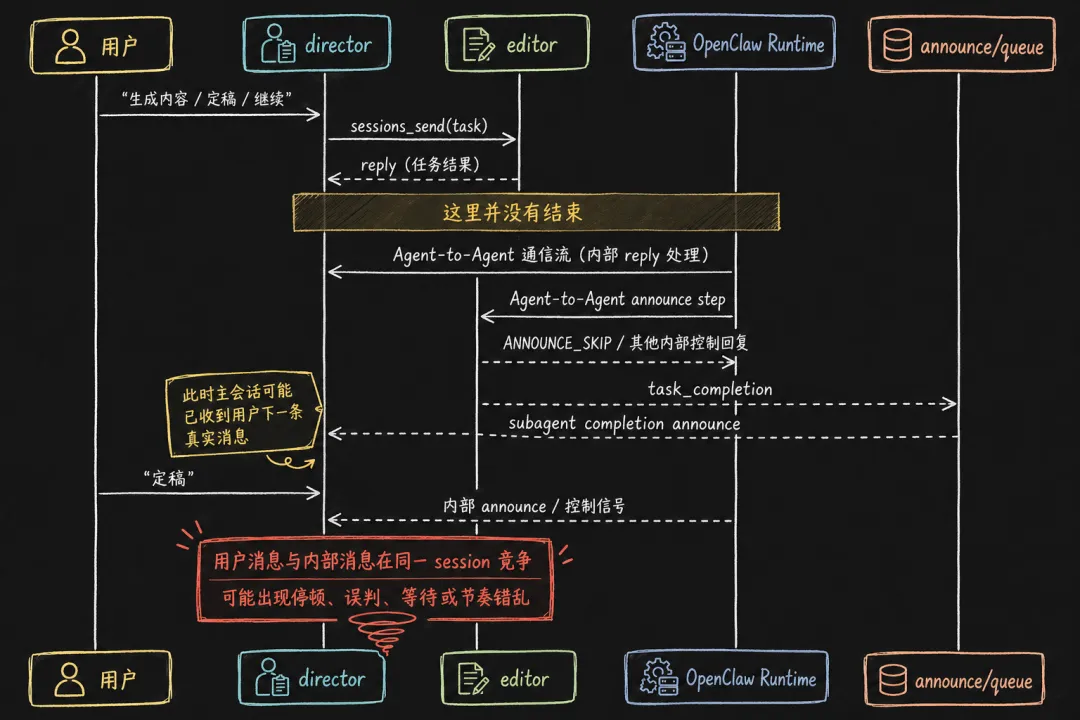
这也解释了为什么问题会在多个渠道出现,而且不是必现。
根因不在某一个渠道,而在系统内部消息编排本身:只要用户输入和内部完成通知在时间上重叠,就有机会触发这种串扰。
三、根因定位:问题不在模型,而在消息编排和完成通知叠加
继续深入之后,问题开始变得清晰。
我确认到一个关键事实:
`sessions_send` 在拿到子 Agent 的 `reply` 之后,不会立刻把事情结束掉,而是还会继续启动一条 Agent-to-Agent 通信流。
这条链路里,系统会显式构造类似 `”Agent-to-agent announce step.”` 的内部消息,再把它作为 `inter_session` 消息重新送回 Agent 会话。
与此同时,subagent completion announce 流也在工作。
它并不是简单“来一个就发一个”,而是带有队列模式、debounce、direct/queue 分流和失败重试逻辑。
于是,在某些时间点上,`director` 会同时面对三类输入:
– 用户真实输入
– 子 Agent 任务完成后的 `reply`
– 系统内部的 announce / 控制信号
这三类输入如果在同一条 session 中交错,就很容易造成“看起来像发呆,实际上是在处理内部消息”的现象。
更关键的是,我在日志里还看到了长期反复出现的一类告警:
subagent announce 在 `120000ms` 后超时,然后再按 5 秒、10 秒、20 秒的节奏继续重试。
这说明用户感知到的“停住几分钟”,有一部分并不是模型在思考,而是完成通知这条内部链路自己在超时和重试。
所以最后定位出来的根因不是某个渠道、某个模型,甚至也不是单个 skill 的提示词,而是下面几个因素叠加:
– `sessions_send` 会触发 Agent-to-Agent 通信流
– subagent completion 也会回告主会话
– announce 链路存在较长超时和重试
– 用户真实消息和内部完成通知可能撞在同一时间窗口里
这是典型的运行时消息编排问题。
四、我去 GITHUB上做了一下病友交流
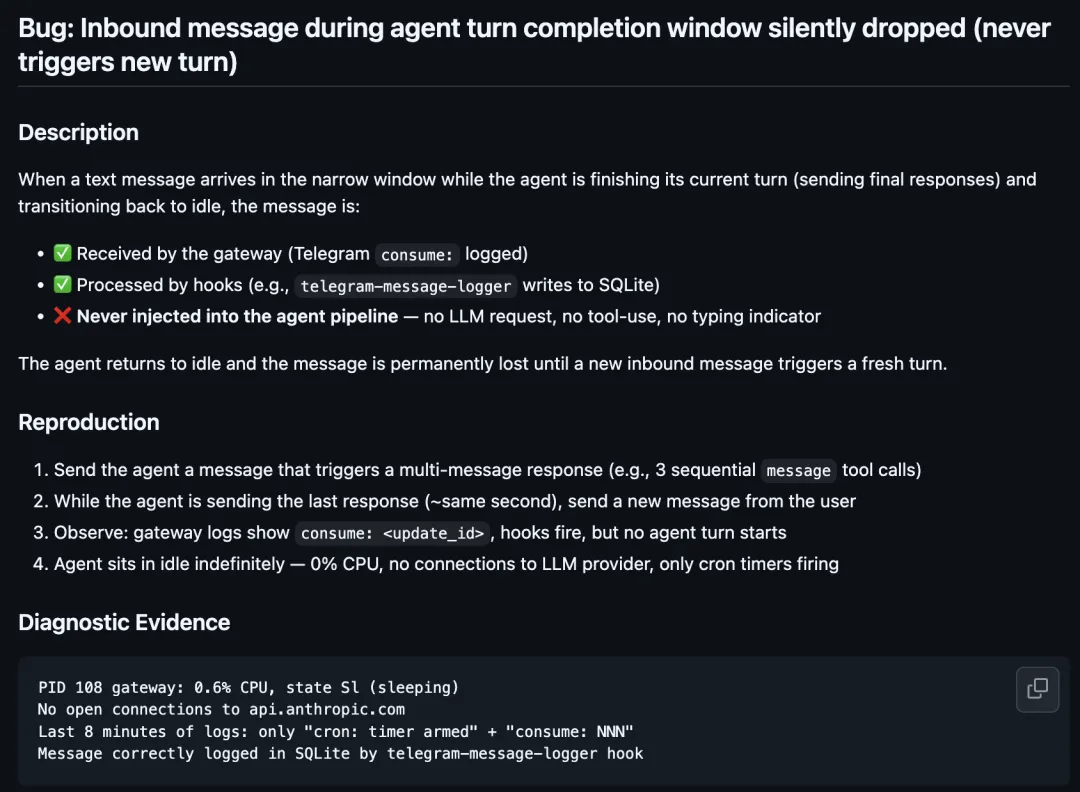
https://github.com/openclaw/openclaw/issues/68414 讨论的是“新消息在 agent 完成当前 turn 的窗口进入后被静默丢弃”
https://github.com/openclaw/openclaw/issues/38300 讨论的是“subagent completion announce 降级为只发频道、不回注 parent session,导致父 Agent 不继续执行”

这些问题虽然表面症状不同,但底层都指向同一类系统性风险:用户真实消息、内部完成通知、会话注入与 announce 流之间存在竞态条件。换句话说,这不是某一个 prompt 写得不够好,而是运行时消息编排本身需要更严格的边界控制。
但是很遗憾,到目前为止,我在github上还没看到官方的回应
五、改动前的风险评估:先看清配置职责,再决定动哪一个
没办法,目前只能自己改,于是我先去研究了openclaw.json里最相关的两个配置项:
1. `agents.defaults.subagents.announceTimeoutMs`
这个配置控制的是 子 Agent 完成后,内部 announce / completion delivery / wake 这条链路允许等待多久。
如果这个值过大,系统在 announce 卡住时就会拖很久;
如果这个值过小,又可能导致完成通知还没来得及送达,就被提前判定失败。
我当前这套环境里,这个值没有显式覆盖,等于使用默认值 `120000ms`。从日志看,很多 announce 卡顿链条正好就是在这个时间点上超时。
2. `session.agentToAgent.maxPingPongTurns`
这个配置控制的是 Agent-to-Agent 通信流里,请求方和目标 Agent 最多允许来回几轮内部 reply。
注意,它影响的是内部通信流,不影响子 Agent 真正执行任务本身,也不影响第一轮 `reply` 的生成。
我当前配置里,这个值是:
`session.agentToAgent.maxPingPongTurns = 3`
从行为上理解,就是:
一次 `sessions_send` 完成后,系统最多还允许 requester 和 target 再来回三轮内部通信。
3. 这两个配置的职责差异
研究完之后,我的判断是:
– `announceTimeoutMs` 影响面更大
它管的是整个 subagent completion / wake 链
– `maxPingPongTurns` 影响面更聚焦
它主要决定 Agent-to-Agent 通信流会不会过度来回
也就是说,如果改错了 `announceTimeoutMs`,后果可能是“完成通知丢失”这种隐蔽问题;
而如果改 `maxPingPongTurns`,更像是在减少内部 chatter,风险相对可控。
所以从工程角度看,第一刀不应该先去碰 `announceTimeoutMs`,而应该先从 `maxPingPongTurns` 这种更聚焦的参数下手。
五、最后改动:先做最保守的一刀
最终我没有同时改多个参数,而是只做了一个最保守的调整:
把`session.agentToAgent.maxPingPongTurns`从 `3` 调整为 `1`。
为什么不是直接改成 `0`?
因为改成 `0` 相当于彻底禁用 Agent-to-Agent 通信流里的多轮内部往返,动作有点太激进。
而改成 `1`,仍然保留最小限度的内部确认能力,但不会让系统在主会话背后继续跑太多轮内部交互。
这个改动的目标很明确:
– 减少内部通信轮次
– 降低控制信号回灌主会话的概率
– 降低用户消息和内部 announce 撞车的可能性
同时,我暂时没有动 `agents.defaults.subagents.announceTimeoutMs`。
因为这项配置的影响面更广,需要在观察一轮实际效果之后,再决定是否要继续收紧。
配置的改动是上周五,4 月24 号, 周末两天我运行了大概十几次各类复杂skill, 中间复现了 4 次,相比之前几乎每次运行都会发生, 可以说症状已经大为缓解. 我也会持续关注github上几个issue的进展.
六、这次排查给我的启发
这次排查最有价值的地方,不是“找到一个参数改掉了”,而是让我重新理解了多 Agent 协作的复杂之处,它在于:
– 它们的完成通知怎么回流
– 内部控制消息怎么隔离
– 用户真实输入在什么时刻拥有更高优先级
– 队列、重试、announce、会话记忆会不会互相放大
如果这些基础设施没有处理好,那么业务上再漂亮的 Agent 分工,也可能在运行时被内部消息串扰拖垮。
所以,多 Agent 系统的稳定性,最后拼的往往不是提示词有多强,而是消息编排和运行时边界是否足够清晰。

