 夜雨聆风
夜雨聆风





AI 也躲不过应试教育,但对人类来说是个好消息
AI 的考试成绩越来越高,但很多人的使用体感却没有同步跃迁。本文从 AI 最初带来的认知冲击开始,讨论今天的大模型为什么越来越像一个被应试教育训练出来的优等生:跑分持续上涨,泛化理解却未必同步提升。黑色幽默的是,我们原本想创造一个真正理解世界的智能,最后却先在 AI 身上看见了人类教育系统最熟悉的影子。但这并不悲观。它反而提醒我们,人类提出新问题、定义新游戏的能力仍然稀缺;也意味着企业可以在一个相对稳定的阶段,真正开始把 AI 放进业务流程里。
过去几年,AI 的考试成绩越来越高。数学、代码、推理、通识测试,几乎每一项都在进步。
但包括我在内的一部分真实感受却是:好像 AI 在过去一年多并没有变聪明很多。
这种撕裂感来自于哪里呢?
如果模型真的越来越强,为什么我们没有重新体验到 2023 年第一次用 AI 时的那种冲击?
那是一个难忘的时刻。
逻辑上,我当然知道屏幕对面只是一个语言模型。它不是人,没有意识,也没有真正坐在那里理解我。
可直觉上,你会觉得自己在和另一个“像人一样的东西”对话。
这种冲击非常直白。
任何赞美的语言,漂亮的跑分,在对比下都显得有些苍白。
因为它和过去的搜索引擎、推荐算法、关键词检索、脚本工具,都完全不是一回事。
后来 GPT-4 出现,大家对未来充满想象。再后来,DeepSeek 时刻引领了全民 AI 时代。
于是每一次新模型发布,我们都会下意识期待下一次类似的震撼。
可奇怪的是,这种感觉越来越少了。
我们一路看着 benchmark 分数往上走。看着模型拿到越来越漂亮的成绩。也看着整个行业继续往里面投入更多的钱、更多的卡、更多的算力、更多的人。
但故事走到了一个微妙的拐点。
GPT-5 发布后,跑分确实提高了。可与此同时,它也遭遇了大量用户的失望和吐槽。
在层出不穷的国产大模型发布信息下,也不时能看到对冲击高分的保留态度。
这不是说这些新模型不够强,而是强力的数据表现却没有带来期待中的代际震撼。
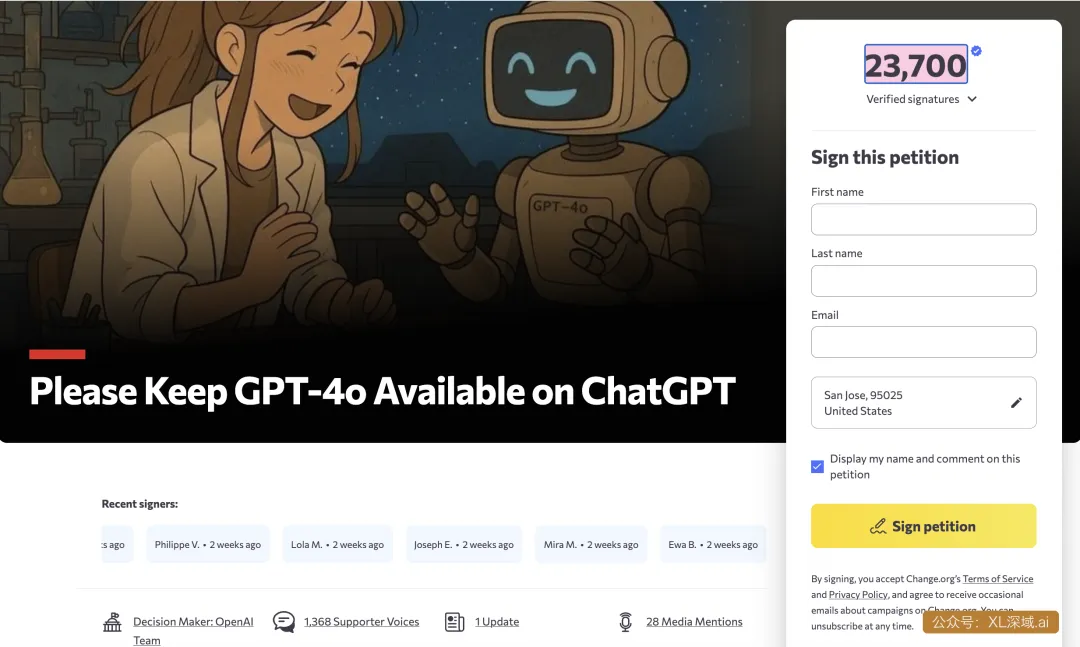
还有用户担心熟悉的旧模型被替换。围绕 GPT-4o 的保留问题,已经有超过两万人参与相关请愿。这个现象本身很有意思:用户不只是在比较模型分数,也是在比较一种交互体验。
问题不是 AI 有没有进步,而是它的进步到底发生在开放的真实世界,还是发生在封闭的考场里。
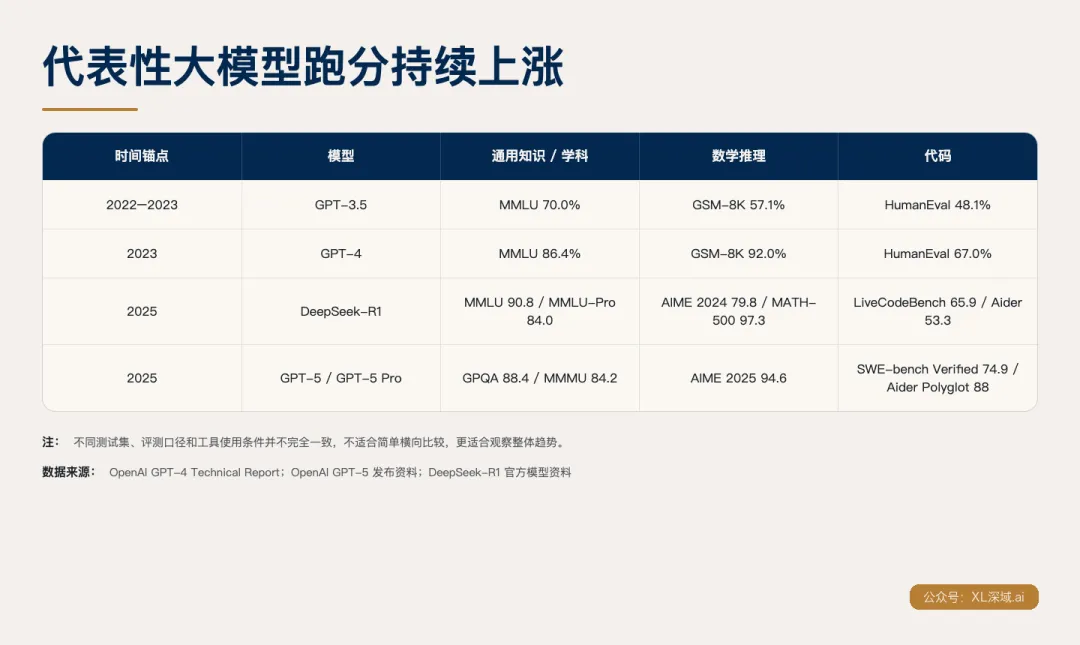
这张表看起来很漂亮。是大模型在持续进步的直观证据。
但它也引出了我的思考:AI 的跑分上涨,不等于 AI 的理解加深。
一个学生考试越来越好,可能是因为他更聪明了。也可能是因为他越来越会考试了。
大模型现在的问题,就有点像后者。
学生 A 赢了考试,学生 B 更像天才
2025 年 11 月,Dwarkesh Patel 采访 Ilya Sutskever。Ilya 在里面讲了一个非常好的比喻。
假设有两个学生。
学生 A 立志成为竞技编程高手。为了这个目标,他投入了 10,000 个小时。他把能找到的题目都刷了一遍,熟悉各种证明技巧,也见过大量变体。
学生 B 也喜欢编程。但他只练了 100 个小时。
最后,两个人在考试里表现得同样出色。
如果你是考官,你会觉得谁更有潜力?
大多数人会选学生 B。
因为他用少得多的练习时间,达到了同样的水平。这说明他身上可能有某种更底层的能力。一种更强的迁移能力。一种不完全依赖题海的理解能力。
Ilya 把这种东西叫作 “it factor”。
它很难被精确量化,但你知道它存在。
就像那个没怎么学过声乐,一开口就很好听的同学。就像那个和大家一起上课,却总能比别人更快理解数学的人。也像那个第一次玩游戏,就把老玩家打得很难受的小学生。
可今天的大模型不像改变世界的天才,更像刷题刷到极致的学生 A。
这不是说它不强。
学生 A 很强。
强到在不少领域已经超越了人。
问题是,它的强,很大一部分来自海量训练、海量曝光、海量题库和海量优化。
为了让 AI 更擅长写代码,我们会拿大量代码题训练它。为了让它更会推理,我们会用更多可验证答案的题目强化它。为了让它在评测里表现更好,行业会不断围绕评测体系优化模型。
这种做法当然有效。
模型会越来越会答题。
它会越来越熟悉题型,越来越懂评分标准,越来越擅长在规则清晰、样本充足、答案可验证的任务里拿高分。
说白了,力大砖飞。
AI 的很多进步,看起来像智能跃迁,背后却可能是题海战术的胜利。
用户用上了 benchmark 认证的高科技产品。
厂商再创辉煌,勇攀高分。
投资人看见曲线向上,也觉得这钱花得值。
看上去,这件事里没有输家。
只是所有人短暂忘却了一个更根本的问题:我们原本期待的是一个什么样的 AI?
拜人类所赐,AI 也在吃应试教育的苦
一个模型能在具体任务上拿高分,不代表它真的理解了世界。
规则越清楚,样本越充足,答案越容易验证,它越容易表现优秀。
可真实世界的问题,往往没有这么干净。
真实世界没有标准答案。
真实组织里没有完美题干。
真实决策也不会告诉你“本题考查知识点:多步推理与跨部门协作”。
这就是 benchmark 和现实之间的距离。
在考试里越来越强,是一回事。
在真实世界里更有判断力、更有适应性、更有创造力,是另一回事。
这两件事之间,隔着很长一段距离。
所以我们会看到一个很有意思的现象:
大模型确实越来越厉害。但代际飞跃的体感,却越来越弱。
因为它越来越像一个闷头刷题,成绩稳健提升的学生 A。
它能做更多题,做更难的题,做更复杂的题。可当你真的和它坐下来聊一聊,你却觉得乏善可陈。
这件事有点黑色幽默。
我们原本想创造一个真正理解世界、改变世界的智能。结果先创造出了一个越来越会考试的硅基优等生。
硅基智能和碳基生命,居然先在应试教育这件事上达成了和解。
人类没能逃过应试教育,AI 更不能幸免。
更讽刺的是,这不是 AI 自己选的路。
这是人类教它的。
我们以为自己在训练 AI,其实也在把人类理解智能的偏见,写进机器里。
因为人类本来就习惯用考试定义聪明。
我们从小就在这样的体系里长大。
我们知道分数有意义,考试有意义,标准化评估也有意义。
但我们也知道,会考试的人,和真正有判断力、有想象力、有迁移能力、有审美、有创造力的人,从来不是完全重合的。
人类定义“智能”的方式,本来就有很强的路径依赖。
我们崇拜高分,崇拜排名,崇拜可量化的证明,崇拜标准化体系里漂亮的表现。
于是,当我们开始训练 AI,也自然把这套逻辑搬了过去。
优绩主义被证明是高效的。
所以我们把它推进到极致。
最后,AI 也被训练成了一个乖学生。
好消息是,人类不必和 AI 比答题
读到这里,很多人可能会觉得悲观。
但我反而觉得,这对人类和企业来说,都是一个更现实的好消息。
原因有三个。
第一,真正稀缺的不是答案,而是问题。
AI 会越来越擅长回答人类已经提出过的问题,在设定好的框架下不断精进自身。
这一点是不可逆的。
但至少到今天,AI 并不擅长主动提出那些人类还没有提出过的问题。
它可以成为围棋大师。
但这不等于它会发明一种全新的游戏。
它可以在已有范式里做到很强。
但这不等于它会重新定义什么值得追求。
这恰恰是人类仍然握在手里的东西:
-
提出新问题。
-
定义新游戏。
-
决定什么值得被追求。
-
判断什么重要,什么空洞,什么有意义。
这些能力,很难被 benchmark 捕捉,也很难被一个围绕既定题目优化的系统完全接管。
所以,如果你焦虑的是“AI 会不会把人的价值全部吞掉”,眼下这条技术路径反而给出了某种缓冲。
它提醒我们:人的价值未必主要在于答题,而在于开出新的题目空间。
当答案越来越容易获取,问题会变得越来越金贵。
第二,让 AI 去做脑力苦工,人去做更重要的判断
AI 虽然未必是天才,但它非常适合做优等生擅长的事。
也就是那些规则相对清楚、流程相对稳定、重复性很高的认知工作。
很多工作并不难。
也谈不上多有创造力。
真正消耗人的,是它们的重复性、机械性和持续性。
整理、归档、复核、对照、改写、分类、汇总、初筛、跟进、生成标准版本。
这些事不是没有价值。
但它们往往不体现人的创造性。
它们只是在消耗人的时间、精力和注意力。
从这个意义上说,AI 对知识工作者的作用,很像洗衣机和洗碗机当年对体力劳动的作用。
洗衣机没有创造衣服。
洗碗机也没有创造饭菜。
但它们确实把人从大量重复、低创造性的劳动里解放了出来。
AI 正在开始对一部分脑力劳动做同样的事。
它未必会替代所有人,也未必会取代那些真正定义方向的人。
但它很可能接手大量人类本来就不该继续亲手做的认知苦工。
这不只是效率提升。
它也是一次时间和注意力的释放。
它把人的带宽,从那些“你已经会了,却不得不反复做”的事情里腾出来。
AI 最先释放的,不一定是人的创造力,而是人的注意力。
第三,模型趋于稳定,企业反而更适合真正落地
过去几年,很多企业对 AI 的态度很纠结。
一方面,大家知道它很厉害,知道不能忽视,知道这件事迟早会进入组织。
另一方面,真正落地时又觉得很虚。
-
模型变化太快。
-
概念翻新太快。
今天一个新名词,明天一个新范式,后天又出现一个更强模型。
很多企业老板会担心:
我今天搭的东西,明天会不会过时?
我今天培训完团队,下个月是不是又要推翻重来?
底层科技迭代太快的时候,组织很容易僵住。
不是因为不想做,而是不知道应该押在哪里。
但如果行业逐渐进入这样一个阶段:模型还在持续变好,但代际式、范式级的冲击开始放缓,那么对企业反而是利好。
因为这意味着企业终于可以站在一个相对稳定的底层上,认真考虑落地和产出。
当 AI 不再被当成“神乎其神的万能药”,而是被当成一种可以嵌入流程、衡量产出、持续迭代的工具时,企业才真正进入了落地阶段。
企业接下来的机会,不在于追上每一次模型更新,而在于把 AI 稳定地嵌入真实流程。
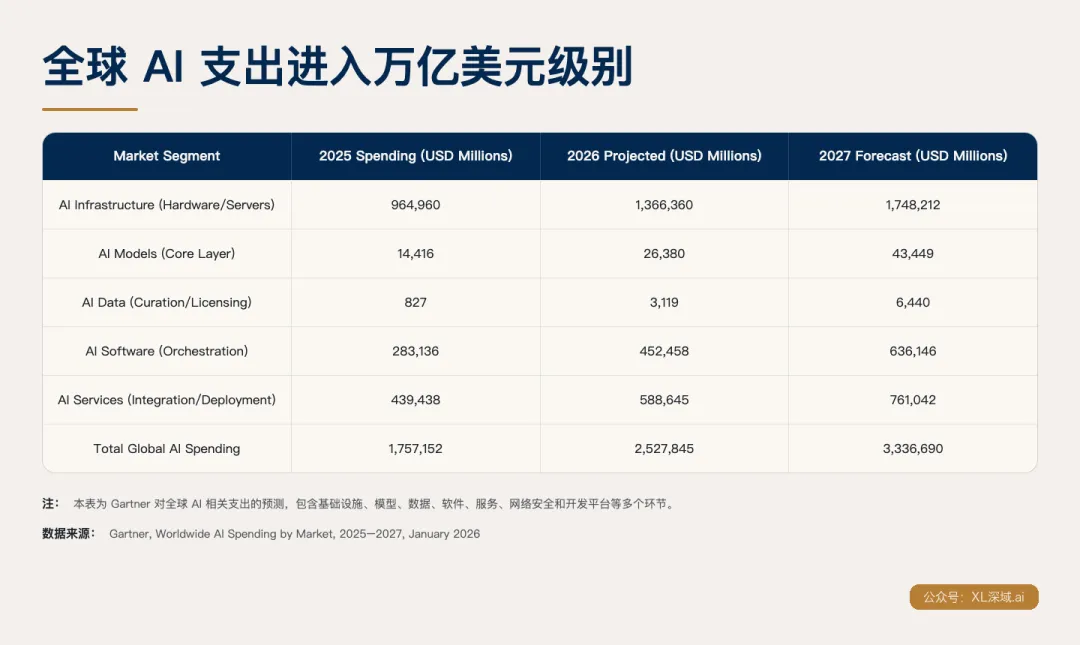
当全球 AI 支出已经进入万亿美元级别,企业真正需要的不是继续围观模型发布会。
而是把问题拉回自己身上:哪些流程可以缩短,哪些工作可以自动化,哪些知识可以结构化,哪些业务链条值得重新设计。
接下来几年,领先者不会只是跟风装了 AI 应用的企业。
而是那些能把 AI 放进真实流程,并持续产出结果的企业。
别做闷头答题的人
回到开头,我们想要天才,却先得到了一个越考越好的做题家。
这不够浪漫,但并不悲观。
因为它最适合做的事,不是替人类决定未来,而是把那些确定、重复、可以流程化的事情,做得更快、更稳定、更具性价比。
对个人来说,训练判断力和定义问题的能力。
对企业来说,把 AI 放进流程里,放进团队里,放进每天真实发生的工作里。
AI 越来越会考试,恰恰说明它终于开始变得可用。
接下来真正拉开差距的,不是谁拥有最会考试的模型,而是谁能用这些模型创造更好的结果。
所以,别只做答题的人。
去做出题的人。
THE END.
