 夜雨聆风
夜雨聆风





AI 会写代码了,但你需要的是“可控的 AI”
当你习惯 AI 辅助编码之后
把需求扔给 AI,让它自己规划任务、修文件、处理依赖——这件事很多人今年才开始正式尝试。运行起来的第一反应往往是:这也太猛了吧。然后等返回结果,发现 AI 改了十几个文件,但方向跑偏了。想撤回,已经乱成一锅粥。

看似高效便捷的 AI 辅助编码背后,藏着很多容易被忽略的现实问题,也是当下每个人在用 AI 写代码时,都会遇到的共性困境。
01
Agent 模式是什么,以及它到底好不好用?
过去的AI编程工具,基本是一个问答机——提问,得到一段代码,复制粘贴,手动集成。今年这波工具做了一件不一样的事:让AI自己规划怎么做,然后真的去做。不是”帮我写一个登录函数”,而是”帮我给这个项目加上用户鉴权”。AI会去读项目结构,判断要动哪几个文件,规划改动顺序,然后一步步执行,生成diff,甚至自己运行测试。业内把这种工作模式叫Agentic Coding,或者自主Agent模式。代表产品是Claude Code、Cursor 3的Agent面板,以及一批专门走Agent路线的新工具。

Agent模式上手的第一感受往往是真实的——确实快,真的能帮上忙。把一个明确的中等规模任务交出去,AI能自动完成70%–80%的机械性工作。以前要开好几个文件、来回对照的活,现在等着就行。
但”好用”是有前提的:任务描述要足够清晰,项目上下文要足够完整。模糊的需求喂进去,Agent会开始”猜”。猜的过程改的文件越多,猜错之后的代价越大。很多人栽在这里,不是AI不行,是没想清楚交出去的任务边界在哪。
02
现实问题:跑起来容易,控制住难
有个细节容易被忽略:Agent模式下,AI做的每一步,人都要能看懂、能接管、能叫停。但现实是,AI改了十几个文件,diff一摊,不容易快速审。有的工具直接就提交了,连确认环节都没有。等发现结果不对,想回滚,发现文件改动已经交叉在一起,撤都撤不干净。
这不是AI的能力问题,是工作流的控制权设计出了问题。真正好用的 Agent 模式,应该是:AI 规划 👉 人预览 👉 确认后执行 👉 局部可以打断和调整。而不是:AI 自己跑完,人来收拾烂摊子。

还有一个维度也很容易被低估:AI 对项目本身的理解程度。有些工具是单文件视野——打开哪个文件,它就知道哪个文件。叫它改一个影响全局的函数,它只看眼前那一块,改出来的结果和别的地方对不上。有些工具能在任务开始前,把整个项目的上下文索引进来,感知模块之间的依赖关系。这两种工具接同一个任务,最终结果可能差很远。
上下文窗口也会惹麻烦。任务一长,改过的文件一多,上下文占满,AI 开始”失忆”——不记得前面提过的需求,结果越跑越偏。有的工具直接崩掉,有的工具开始乱猜。

03
MonkeyCode 在这两件事上的做法
项目理解深度和上下文管理,是 MonkeyCode 重点投入的两个方向。
项目级全局理解
让 AI 在规划代码与内容改动的全过程中,主动感知项目内各模块、功能、文件之间的关联逻辑与依赖关系,摒弃只聚焦当前打开单一文件的碎片化视角。
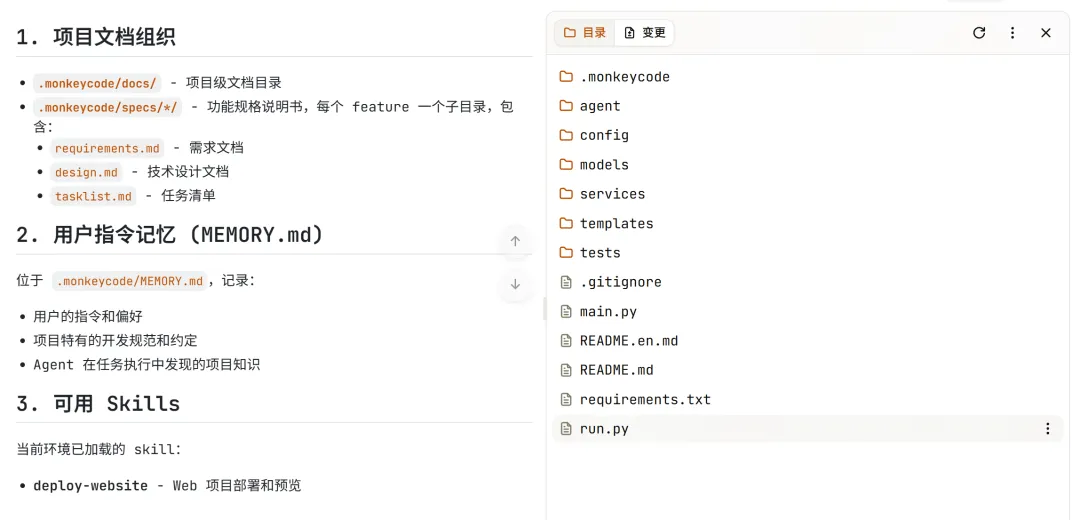
MonkeyCode 的项目级全局理解是通过 .monkeycode/ 目录下的文件实现的:MEMORY.md 记录用户偏好和项目知识,specs/ 目录存放各功能的 EARS 需求文档和技术设计文档,docs/ 目录存放项目级文档。Agent 会优先读取这些文件来保持对项目上下文的一致性理解。
上下文主动管理
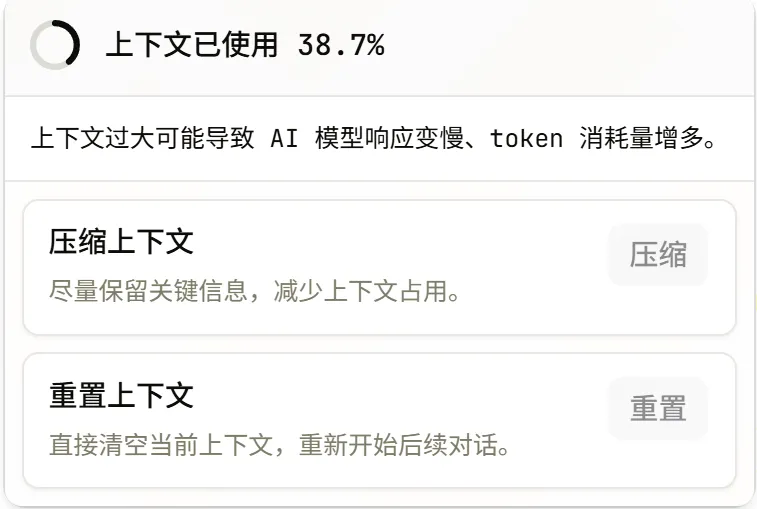
提供了上下文占用显示。当占用过高时,可以选择压缩上下文(保留关键信息,减少 token 占用),或者直接重置上下文清空重来。长对话场景下,不需要因为上下文撑满而换工具或者重新开对话。
04
写在最后-实操建议
把任务切小。 不是越大越好。一个可控的中等任务,比一个”帮我重构整个项目”效果好得多。边界越清晰,AI 的方向越准。
看懂再提交。 养成在提交前快速过一遍 diff 的习惯。找的不是细节 bug,是方向有没有跑偏。
迭代比一次到位更好。 AI 第一轮结果不完美,没关系,跑第二轮。追求”一次搞定”反而容易越改越乱。
🎉交流更多编程心得扫描下方二维码加入MonkeyCode微信交流群,解锁更多硬核技巧,和开发者们一起交流学习~
👉进群即刻领取专属积分福利。
