 夜雨聆风
夜雨聆风





你看到的AI App排名,背后是OpenRouter平台
我们经常看到类似下面的大模型或者AI Agent使用量排名,你知道这些排名是怎么来的吗?
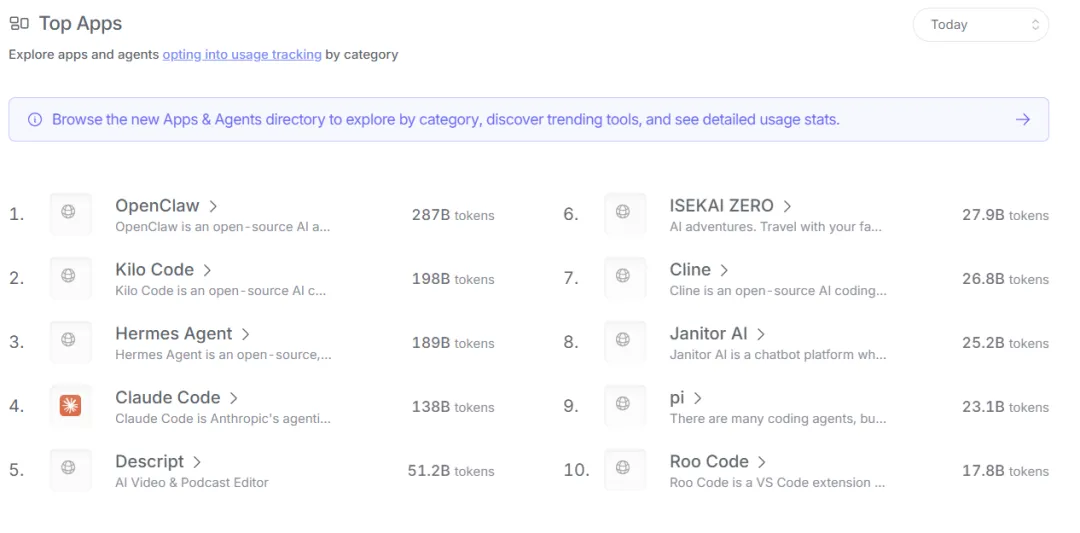
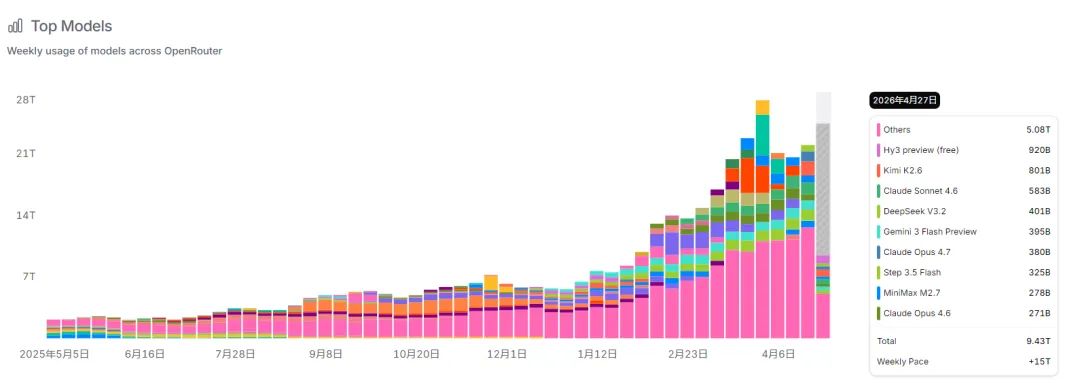
这些排名出自一个叫OpenRouter的平台。
它的创始人Alex Atallah,斯坦福大学计算机科学专业毕业,于2014年毕业,另一个身份是全球最大NFT(非同质化代币,是一种基于区块链的数字资产凭证)平台OpenSea的联合创始人。
从加密世界的NFT,到AI时代的“模型聚合器”,这套“把碎片化供给统一起来”的打法,在他手里成功了两次。
01 故事的开端:为什么他要做OpenRouter?
2022年底,ChatGPT引爆了AI热潮。但Alex Atallah看到的是一个“混乱”的局面。
每个大模型都有自己的API,互不兼容。开发者想同时用GPT-4和Claude,就要维护两套代码。新模型层出不穷,但每个都要重新集成一遍。
这个场景让他想起了2017年的NFT行业。各家平台的数字藏品标准不一,用户需要一个地方把散落各处的东西集中起来。他联合创办的OpenSea,做的就是这件事。
既然这套逻辑在NFT时代跑通了,为什么不能在AI时代再试一次?
于是,2023年初,OpenRouter开始立项。
插一句:它和LangChain有什么不同?
我上一篇文章讲过LangChain,可以回顾一下。它们都是2023年初起步的,都为了解决AI模型生态的碎片化问题,但是有较大差别。
LangChain是一个开发框架。它帮你把大模型、外部数据、各种API“链”在一起,构建复杂的AI应用。它关心的是“怎么把多个步骤串联成一个Agent或工作流”。
OpenRouter是一个API聚合层。它让你用一个接口调用所有模型,不用关心每个模型厂商的接口格式、计费方式、密钥管理。它关心的是“怎么让开发者无缝切换和调用不同模型”。
它们也可以配合使用——很多开发者用LangChain写业务逻辑,但背后的模型调用通过OpenRouter来完成。这时,LangChain负责“怎么编排”,OpenRouter负责“调哪个模型”。
02 从个人工具到公共服务
最初,OpenRouter只是一个解决自己痛点的原型工具。Alex自己写了一套代码,用一个API统一调用多个模型。
他把项目发到GitHub和Twitter上,本意是“代码开源,你们有需要可以自己部署”。
但反响出乎意料——大量开发者找过来,说的不是“代码收到了”,而是:“代码我们看到了,但我们不想自己部署服务器、维护API密钥。你能不能直接提供一个在线的API服务?”
自己部署意味着要租GPU实例、处理并发和负载、保证稳定性。不是每个开发者都有这个资源或意愿。
这成了OpenRouter的转折点。2023年4月,团队决定从“代码仓库”转向“SaaS平台”,正式推出公开的API服务。
早期用户是那些“模型尝鲜者”——AI研究者和独立开发者。他们苦于每次新模型出来都要重新写调用代码,OpenRouter正好解决了这个痛点。
一个关键的策略是:API设计完全兼容OpenAI的规范。这意味着开发者可以直接用OpenAI的SDK,只是改一个base_url,就能开始调用Claude或Llama。迁移成本几乎为零。
03 爆发:“模型丛林”时代来了
2023年下半年到2024年,情况发生了根本性变化。
开源模型爆发——Llama、Mistral、DeepSeek陆续登场,训练和推理成本急剧下降。闭源模型也在卷——GPT-4 Turbo、Claude 3、Gemini 1.5各有各的长处。“百模大战”正式打响。
Alex早先的判断被验证了:不会出现一个模型赢家通吃的局面。相反,开发者需要一个“模型路由器”,根据不同任务选择不同模型——翻译用这个、写代码用那个、做创意用另一个。
OpenRouter开始加速迭代,增加了大量“超出聚合”的价值:
- 智能回退:如果GPT-4的API堵了,自动切换到Claude。
- 自动路由:平台根据你的提示词内容,帮你选出最合适的模型。
- 成本优化缓存:重复请求实现秒级响应,费用大幅降低。
- 联网搜索:所有模型都能联网获取实时信息,并自动附上来源引用。
这些功能让OpenRouter从“API中转站”进化成了AI网关(AI Gateway)。
到2024年底,平台数据一路暴涨:对接300多个模型、60多家供应商,服务约100万注册用户,年处理Token量突破100万亿。
04 关键决策:为什么开发者信任它?
在聚合类平台中,用户最关心的永远是两个问题:数据安全和稳定性。
OpenRouter在这两方面的处理方式值得一提。
关于数据安全。平台默认不记录请求和响应内容,所有数据传输采用TLS 1.3加密。对于合规要求更高的企业用户,OpenRouter提供了“自带密钥”(BYOK)模式——请求直接路由到模型提供商,OpenRouter本身不存储任何敏感信息。
关于稳定性。平台设计了多层负载均衡和跨区域部署。当某个模型提供商的API出现故障或容量不足时,系统可在毫秒级内自动切换到备用路线。
这些设计让OpenRouter获得了包括金融、医疗等敏感行业客户的信任。一位金融数据分析团队的技术负责人曾公开表示:“我们选择OpenRouter不是因为它便宜,而是因为它稳定。对我们来说,API随时能用比省30%的成本更重要。”
05 资本入场:从工具到基础设施
随着调用量飙升,OpenRouter的商业模式也清晰了。
用户在模型原价基础上支付5%的平台费用,换取一个统一接口和所有附加功能。或者选择BYOK模式——使用自己的模型供应商账户,OpenRouter只收取少量服务费。
2025年6月,资本入场了。
顶级风投a16z和Menlo Ventures领投,红杉参投,4000万美元到账,估值达到5亿美元。
投资人的逻辑很简单:如果AI应用是未来的主流软件形态,那OpenRouter就是这些应用的“水电煤”之一。它不做模型,但所有模型都跑在它上面。
06 它到底被用来做什么?
OpenRouter不是藏在极客世界的工具。到今天,它已经渗透进大量真实的业务场景。
个人开发者:一个人做一个AI小工具,一个后台管理所有模型的调用和账单,不用和每个模型厂商分别签约。
内容创作团队:不同任务分配不同模型。新闻报道调用严谨的Llama,营销文案调用创意更强的GPT-4,成本和效果两头优化。
自动化工作流:集成到n8n等自动化平台。用户通过Telegram发一张收据照片,系统先用OCR识别文字,再通过OpenRouter调用大模型提取日期、金额等信息,最后自动填入Google Sheets。
金融数据分析:将非结构化的财报文本自动转为结构化数据。一家采用该方案的企业反馈,分析效率提升了3倍以上。
07 未来:他要做什么?
Alex Atallah曾在采访中说过一段话:“未来可能只需要几百美元就能训练出一个特定领域的小模型,那将会有几万、甚至几十万个模型。它们需要一个自己的‘应用商店’。”
OpenRouter的野心不止于API聚合,而是成为AI时代的模型层基础设施——所有模型都在这里被调用、被路由、被比较、被优化。
接下来的几个方向已经在路上:更智能的路由(通过强化学习实现策略自适应)、多模态支持(图像、音频、PDF统一处理)、插件生态(允许开发者定制个性化调度策略)。
从OpenSea到OpenRouter,Alex两次在“混乱的供给端”里找到了平台级机会。这套“把碎片化市场标准化”的方法论,在AI时代再一次被验证可行。
故事还在继续,国内的开发者有没有看到机会?
本文首发于微信公众号[ 林说AI ]。转载须注明出处。
AI辅助开发的数独小程序:数独行