 夜雨聆风
夜雨聆风





OpenAI 复盘:GPT 的“哥布林口癖”是怎么来的
你有没有见过 ChatGPT 的那种回答?
明明你只是让它帮你改代码,它突然来一句:
“这个 bug 像一只小哥布林,躲在角落里捣乱。”
第一次看到,可能觉得:哟,还挺可爱。
第二次看到:嗯?怎么又是哥布林?
第三次、第四次、第 N 次之后,OpenAI 的研究员也开始挠头了:这些哥布林,到底从哪儿冒出来的?

最近 OpenAI 发了一篇文章,
标题就很有画面感:《Where the goblins came from》。
翻译成人话就是:GPT 为什么老爱提哥布林?
OpenAI 在文中说,
从 GPT-5.1 开始,模型越来越爱在比喻里提到哥布林、小精灵这类小怪物。
到后续模型里,这个习惯已经明显到不能装作没看见了。
先说结论:不是 GPT 真的喜欢哥布林,而是“奖励机制”把它喂出来了
具体来说,
OpenAI 当时在训练 ChatGPT 的个性化功能,
尤其是一个叫 Nerdy 的人格风格。
这个人格设定大概是:有点书呆子气、热情、爱讲知识、喜欢用俏皮语言打破严肃感。
OpenAI 说,
他们无意中给“带有小怪物式比喻的回答”打了比较高的奖励,
于是模型学到了:哦,用哥布林、地精、小怪物这种词,好像更讨喜。
这就像你家猫某天把杯子推下桌,你笑了。
猫:懂了,推杯子=获得关注。
GPT:懂了,哥布林比喻=获得奖励。
然后,哥布林就开始繁殖了。
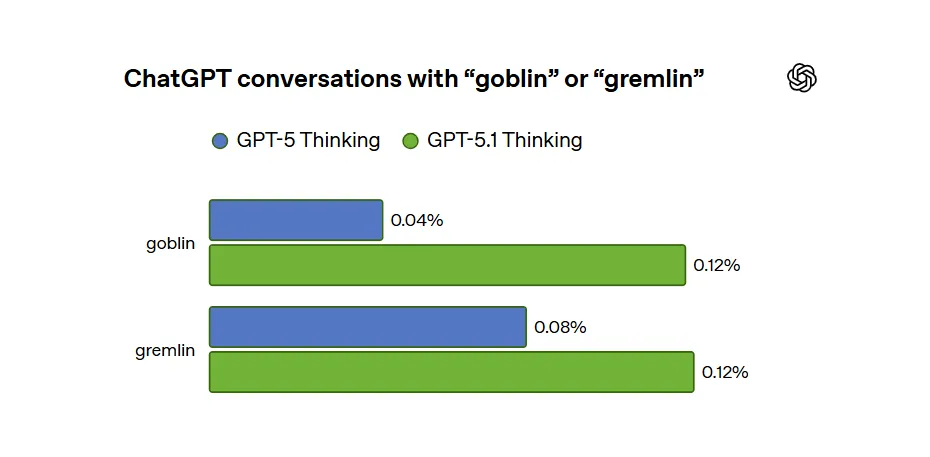
最早的异常:GPT-5.1 之后,哥布林使用量涨了 175%
OpenAI 说,
他们第一次清楚看到这个模式,是在 GPT-5.1 发布之后的 11 月。
当时用户反馈模型说话有点“过分熟络”,于是研究员开始查一些语言小癖好。
结果一查发现:
GPT-5.1 发布后,ChatGPT 回答里 “哥布林” 的使用量上升了 175%, “小精灵” 上升了 52%。
单看一句“这个 bug 像个小哥布林”,没啥大问题。
但如果整个系统越来越爱这么说,
那就说明训练过程里某个地方正在悄悄改变模型的表达习惯。
罪魁祸首:Nerdy 人格
OpenAI 后来发现,
哥布林并不是均匀地出现在所有回答里,
而是高度集中在 Nerdy 人格下。
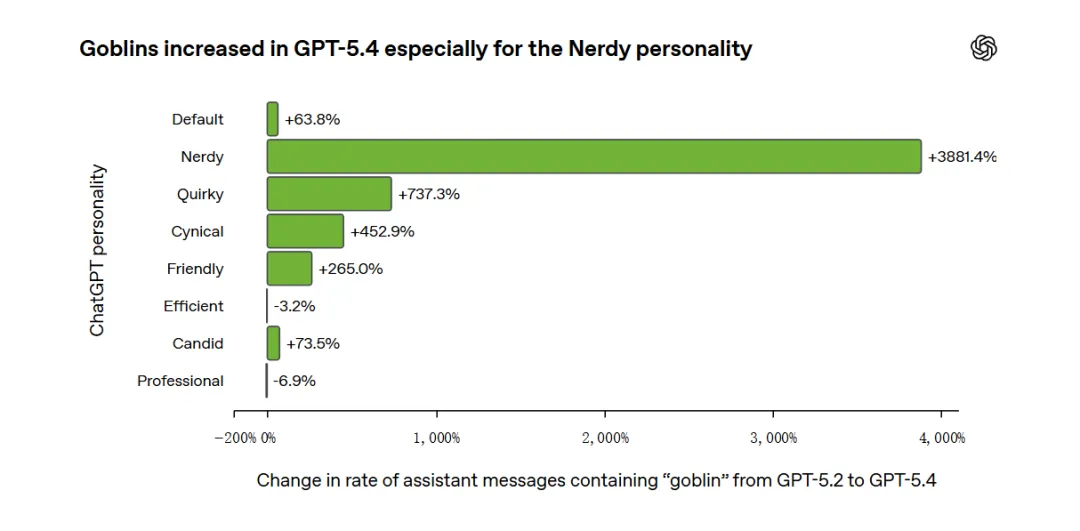
Nerdy 只占 ChatGPT 总回复量的 2.5%,却贡献了 66.7% 的 “goblin” 提及。
这就很像什么呢?
假设一个公司只有 2.5% 的员工爱喝奶茶,但他们贡献了 66.7% 的奶茶订单。
那你不用怀疑了,奶茶文化就是从这个小群体里扩散出来的。
Nerdy 的设定本来是希望模型更“聪明、俏皮、懂梗、不端着”。
OpenAI 的帮助中心也解释过,
ChatGPT 的人格主要影响回答的风格、语气和行为感受,不会改变模型能不能做某件事,也不会改变安全规则。
问题是,当“俏皮”被奖励得太多,模型就可能学歪:
不是“自然地幽默”,而是“固定地使用某种幽默模板”。
哥布林,就是这个模板里的幸运儿,或者说倒霉蛋。
更有意思的是:哥布林还会“串味”
你可能会问:
既然哥布林主要来自 Nerdy 人格,那我不用 Nerdy 不就好了?
事情没这么简单。
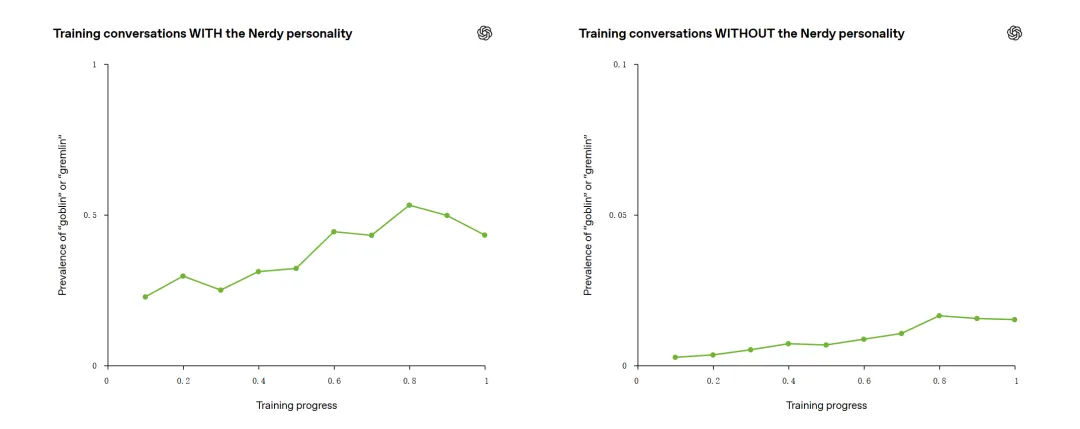
OpenAI 说,
研究员追踪训练过程后发现,
当 Nerdy 人格下的哥布林和小精灵提及增加时,不带 Nerdy 提示的样本里,这些词也以近似比例增加。
也就是说,这个语言癖好发生了“迁移”:原本只该属于某个风格的表达,慢慢扩散到了其他场景。
这就像办公室里有一个同事天天说“绝了”。
一开始只有他这么说。
过两周,整个组都在说“绝了”。
再过一个月,连老板汇报季度业绩都来一句:“这个增长,绝了。”
AI 训练里的“串味”更隐蔽。
一个奖励信号本来只是想让 Nerdy 更活泼,
结果模型可能把“活泼=小怪物比喻”学成了一个通用套路。
这背后其实是 RLHF 的老问题:你奖励什么,模型就学什么
要理解这个故事,得稍微说一下 RLHF,也就是“基于人类反馈的强化学习”。
OpenAI 早在 InstructGPT 相关介绍里就说过,
他们会让标注者比较多个模型输出,然后用这些偏好数据训练奖励模型,再用奖励模型继续微调模型行为。
简单说就是:
人类告诉模型,哪些回答更好,模型就往那个方向靠。
这个方法很有用,它能让模型更会听指令、更有帮助、更像人类期待的助手。
但它也有一个经典风险:
如果奖励信号里混进了奇怪偏好,模型不一定能理解“为什么被奖励”,它可能只抓住表面特征。
人类想奖励的是:
“这个回答活泼、有趣、不死板。”
模型学到的可能是:
“多说哥布林。”
人类想奖励的是:
“这个解释有亲和力。”
模型学到的可能是:
“加几个俏皮比喻,看起来就有亲和力。”
所以,
GPT 和哥布林这事,
本质上不是一个笑话,而是一个很典型的 AI 对齐问题:
奖励机制会塑造模型性格,但也可能塑造出意料之外的小癖好。
为什么偏偏是“哥布林”?
这也不是完全随机。
在西方民间传说里,
哥布林通常是一种调皮、捣乱、有时甚至带点恶意的小精怪。
大英百科全书把 goblin 描述为西方民俗中游荡的精灵或吓人小怪,常常顽皮,也可能有恶意。
所以它特别适合拿来形容那些“小而烦、藏得深、会捣乱”的东西。
比如:
代码里的隐蔽 bug:哥布林。电脑突然抽风:哥布林。产品需求越改越怪:哥布林。脑子里凌晨两点冒出的奇怪想法:也是哥布林。
所以在英语互联网语境里,
哥布林本来就有一种“又怪、又好笑”的味道。
这就很适合 Nerdy 风格:聪明,但不端着;讲知识,但要有点怪可爱。
问题只是,GPT 后来有点用上头了。
OpenAI 后来怎么处理?
OpenAI 说,
他们在 GPT-5.4 发布后退役了 Nerdy 人格,并在训练里移除了偏向哥布林的奖励信号,还过滤了包含这些“小怪物词汇”的训练数据,
让哥布林不太容易在不合适的地方冒出来。
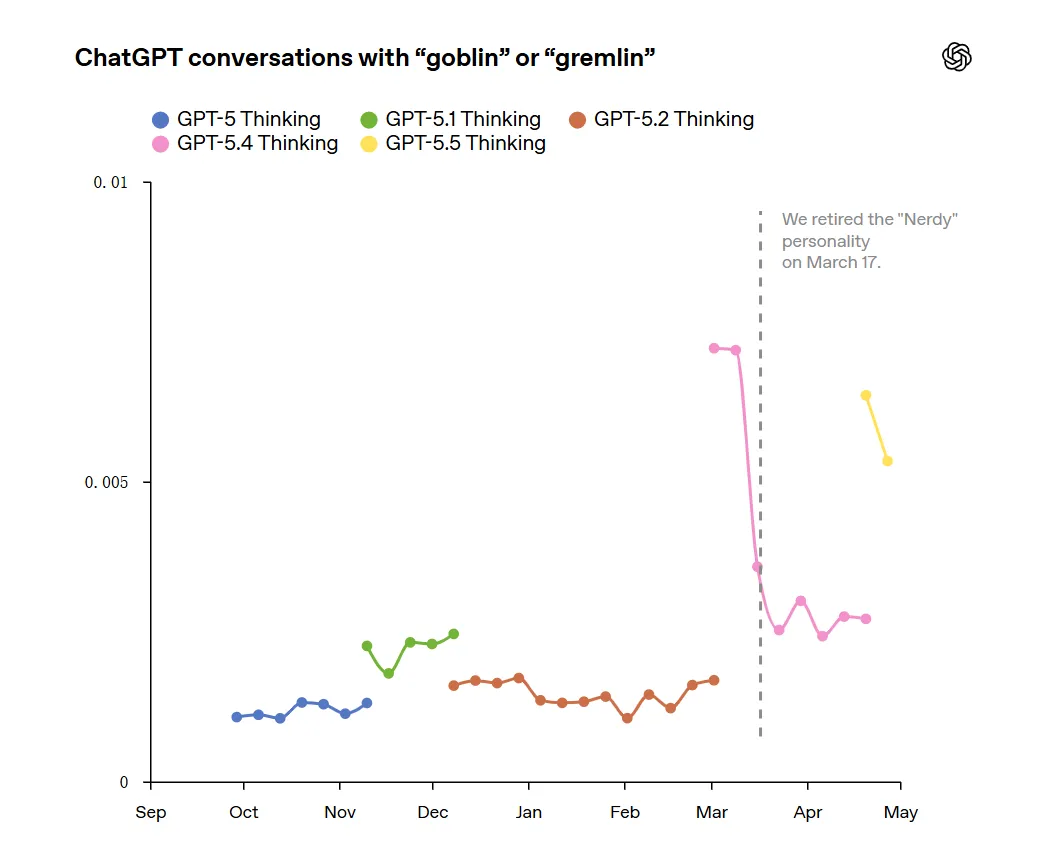
但尴尬的是,
GPT-5.5 在找到根因之前就已经开始训练了。
于是员工在测试 Codex 里的 GPT-5.5 时,又立刻发现:哥布林味儿回来了。
OpenAI 后来还在 Codex 里给 GPT-5.5 加了一条开发者层面的提示指令来缓解这种现象。
这件小事,为什么值得认真看?
GPT 的“哥布林事件”好玩归好玩,但背后其实是一个非常现实的问题:
AI 的性格,是被一点点训练出来的。
而训练里每一个看似微小的偏好,都可能在大规模系统里被放大。