 夜雨聆风
夜雨聆风





让 AI 来养知识库,只需要一句话
目前已经建了两个库:一个是 AI 知识库,一个是公司资料知识库。用下来最大的感受是,它不只是让我更快理解新概念、形成结构化知识,也给我的 agent 准备了一个很好查、带索引、带关系的本地资料库。
之前我的资料管理方式主要有两种。
一种是直接用文件夹存。资料都在,但没有被真正组织起来,找起来也很不方便。
另一种是放进 NotebookLM,需要的时候让 agent 去查 NotebookLM。这个方式也能用,但更像一个查询入口。
这两种方式都能解决“资料怎么找”的问题,但没有真正解决“知识怎么持续沉淀”的问题。
Karpathy 说的 LLM Wiki 是什么
Karpathy 这套方法的重点,不是某个具体工具,而是一种知识库组织方式。
简单说,就是把知识库分成三层:
- Raw Sources:
原始资料层。文章、论文、访谈、飞书文档、网页剪藏都放这里,原则是只读不改。 - Wiki:
结构化知识层。LLM 读完原始资料后,自动提取概念、写摘要、补案例、加来源、建立交叉链接。 - Schema:
规则层。告诉 LLM 这个知识库应该怎么编译,概念粒度怎么定,矛盾信息怎么处理,链接怎么建。
这跟向量知识库 或普通文档问答最大的区别是:向量知识库 往往是每次提问时重新检索、重新拼答案,用完就结束;LLM Wiki 是先把知识“编译”成一组可以长期维护的 Markdown 页面,后面持续增量更新。
Karpathy 的说法里,我最有共鸣的是这一点:维护知识库最烦人的部分,其实不是阅读和思考,而是那些琐碎的记账工作。比如更新目录、补链接、标记来源、发现重复概念、把新资料合并到旧页面里。
这些事人很容易懒,但 LLM 不嫌烦。
我把它做成了一个 skill
为了更方便地使用这套方法,我后来做了一个 wiki-manager skill,把新建、更新、检查知识库这些动作封装起来。
现在我不需要每次都重新解释一遍“怎么整理 wiki”。只要告诉 agent 用这个 skill,它就知道按固定流程做:
-
扫描 raw/里有没有新素材 -
读取 index.md判断新素材关联哪些已有概念 -
创建或更新 wiki/里的概念页面 -
更新总目录和编译日志 -
做一次健康检查,找孤立页面、缺失链接、过时说法 -
如果有变化,刷新 graph.html知识图谱
在公司资料库的场景里,我的用法大概是这样:
-
先让 agent 用飞书 CLI 把公司知识库下载到本地。 -
然后说“用 wiki skill 编译这个知识库”。 -
后面定期拉取飞书文档,或者本地有新文件加入时,再说“编译新增资料”。 -
如果担心质量,就让 skill 做健康检查,检查孤立节点、缺失文档、互相矛盾的表述。
AI 知识库的用法更自由一些:
-
一开始直接让 agent 下载经典博客、文章、论文,建立第一版。 -
后面我在阅读 AI 资讯时,把值得保留的内容扔进 raw/。 -
一般是新加了就及时让 agent 编译进去。
这两个库的主题不同,但工作流是一样的。
最终产物长什么样
编译后的知识库大概是这个结构:
my-wiki/├── raw/ # 原始素材:文章、论文、飞书文档、网页剪藏├── wiki/ # LLM 生成和维护的概念页├── index.md # 总目录,也是 agent 查询时的入口├── schema.md # 编译规则├── log.md # 每次处理了哪些素材、改了哪些页面├── health-check.md # 健康检查结果└── graph.html # 概念关系图谱其中最常看的其实是 index.md 和 wiki/。
比如 AI 知识库现在已经有 48 个概念页,index.md 里会按主题列出:
- [上下文工程](./wiki/context-engineering.md) — 填充上下文窗口的艺术与科学- [Agent 工具设计](./wiki/agent-tool-design.md) — 工具接口设计原则、Think Tool、eval 标准- [LLM Wiki](./wiki/llm-wiki.md) — 用 LLM 增量构建持久化 wiki- [NotebookLM](./wiki/notebooklm.md) — 基于来源的 AI 研究工具每个 wiki 页面也不是简单摘要,而是一个相对完整的概念卡片。它会保留更新时间、别名、核心解释、结构化要点、来源和相关概念。比如 MCP 这个页面,开头是概念解释和核心结构:

正文里提到相关概念时,也会直接保留可点击的链接,方便继续跳过去看:

到页面最后,再集中列出来源和相关概念:

这种结构对人和 agent 都友好。
人看的时候,它像一套持续更新的百科;agent 查的时候,也有明确入口、文件路径、来源和相关概念。
后来我又加了图谱
用了一段时间后,wiki 的概念越来越多,超过 30 个以后,单靠目录就有点难找了。
所以我又迭代了一版,让 skill 自动生成 graph.html。每个概念是一个节点,概念之间的关联是线。节点越大,说明它连接的概念越多;线越粗,说明关系越强。
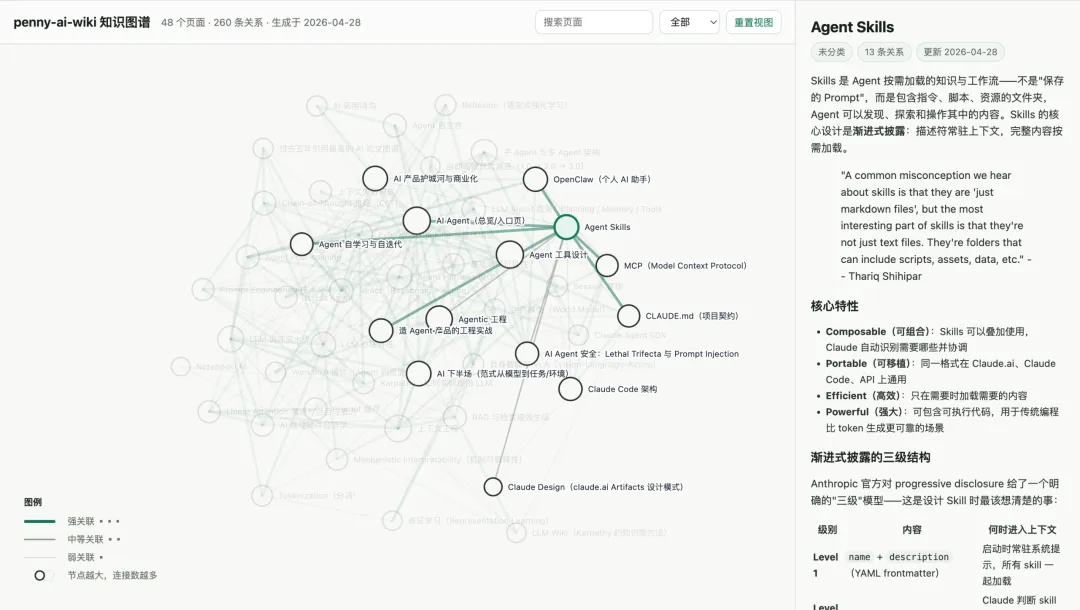
这个图谱的价值不是“好看”,而是它能让我一眼看到知识结构。现在点开一个节点,右侧还能直接预览对应的 wiki 页面,不用在文件夹里来回翻。
比如在 AI 知识库里,Agent、上下文工程、工具设计、Skills、RAG 这些概念会自然聚在一起;
有时候我不是为了查某个确定答案,而是想知道“这堆资料之间到底有什么关系”。这时图谱比搜索框更直观。
和 NotebookLM 怎么选
我一开始也很困惑:这种本地 wiki 知识库,和向量知识库,比如 NotebookLM,到底怎么选?
两个我都在用,目前的感受是:
中等规模内,两者都能用。Karpathy 原文里提到,单靠 index.md 在中等规模下也能工作得不错,大约是 100 个 source、数百个页面,不一定需要用到向量知识库。我自己的 AI wiki 现在也已经是 100+ 素材、48 个概念页,使用起来仍然良好。这个量级下,两者都能查,主要差别在组织方式。
Wiki 更适合个人长期学习。它有结构,可以修改,可以积累,可以不断把新理解写回去。NotebookLM 这类向量知识库虽然可以生成思维导图、音频概览、问答和笔记,但它更像一个基于资料的研究工作台,结构不是你长期共同维护出来的。
资料规模很大时,向量知识库更省心。比如书籍、课程、大量 PDF,尤其是图文混排资料,NotebookLM 这类工具更合适。它对原文检索、引用定位、图片相关内容的处理更顺手。本地 wiki 如果把几本书都拆成概念页,维护成本会明显上升。
所以我现在不是二选一。
持续积累的主题,我会放进本地 LLM Wiki;需要快速读一批大资料、书籍、PDF、图文材料时,我会放进 NotebookLM 这类向量知识库。
总结
这套方法给我的启发是:个人知识库不一定要一开始就上复杂系统。
一个文件夹、一套 Markdown、一个会读写文件的 agent,再加一份清楚的 schema,就能先跑起来。
它的核心不是“AI 帮我总结文章”,而是“AI 帮我长期维护一套结构化知识”。这个差别很大。
前者是一次性输出,后者会越用越厚。
如果有人对这个 skill 感兴趣,我后面会把它整理一下放到 GitHub。它目前已经支持新建知识库、增量编译、健康检查和图谱生成,基本可以覆盖我现在的日常使用。