AI 进入运维一线后,最先被改变的不是工具,而是故障处理流程
过去一段时间,越来越多企业开始把注意力放到 AI 和大模型上。但在真实业务里,决定效果的往往不是模型参数,也不是一句简单的“接入了 AI”,而是它有没有真正进入日常流程。 尤其当 AI Agent 开始处理检索、归纳、生成、分发、执行等重复性任务后,团队被改变的,往往不只是效率,还有岗位分工、协作方式和价值重心。 一、为什么 AI 在运维里开始变得“真的有用” 过去大家谈 AIOps,常常容易停留在概念层面。但现在一个更明显的变化是,AI 正在被直接嵌入监控、告警、事故响应、知识库和平台自助服务这些日常流程里。
系统越来越复杂,单靠人脑已经很难同时盯住日志、链路、监控、变更和工单。
告警越来越多,值班工程师最先消耗掉的时间,往往不是处理故障,而是判断哪些值得看。
运维经验仍然集中在少数人手里,一旦遇到夜间故障或跨团队协同,信息查找成本很高。
很多团队并不缺工具,真正缺的是把工具串成流程的能力。
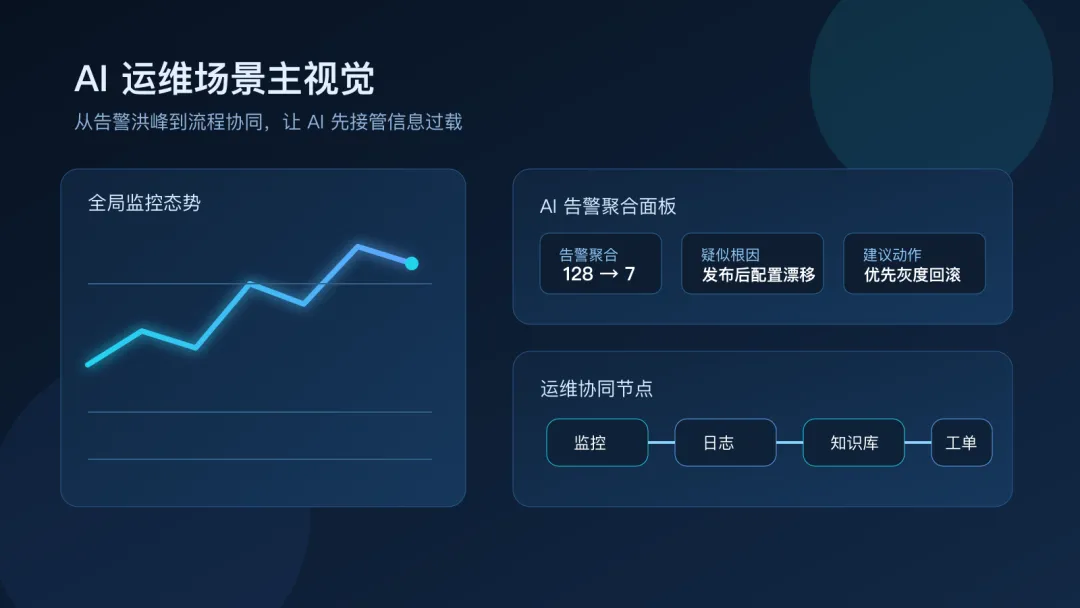
所以,AI 在运维里最先兑现价值的地方,并不是“自动修复一切”,而是先帮团队解决几个老问题:信息过载、响应太慢、知识难复用、流程难复制。 二、AI 最适合先接管哪些运维工作 如果从落地难度和收益来看,最值得优先接入 AI 的,往往是这些高频、重复、可标准化的环节:
告警初筛与聚合:判断是不是同一类故障,哪些是噪声,应该先找谁。
故障知识检索:从历史工单、Wiki、复盘文档里快速找相似案例。
变更风险预检:在发布前提示高风险点、缺失项和回滚条件。
Runbook 执行辅助:在处置过程中提示下一步该看什么、做什么、注意什么。
事故复盘初稿生成:自动整理时间线、操作记录和影响范围,减少复盘准备成本。
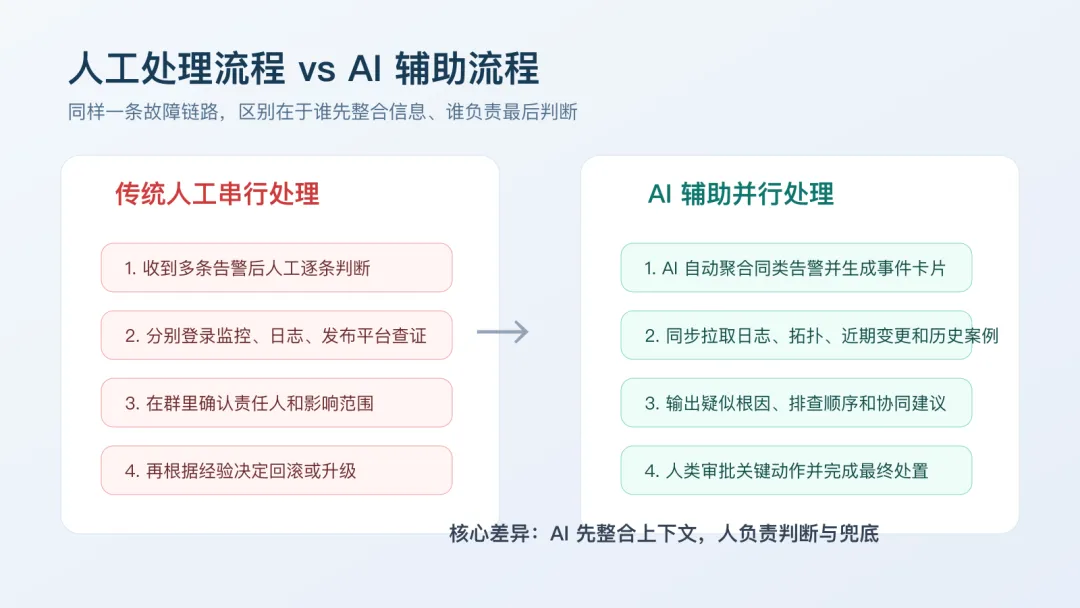
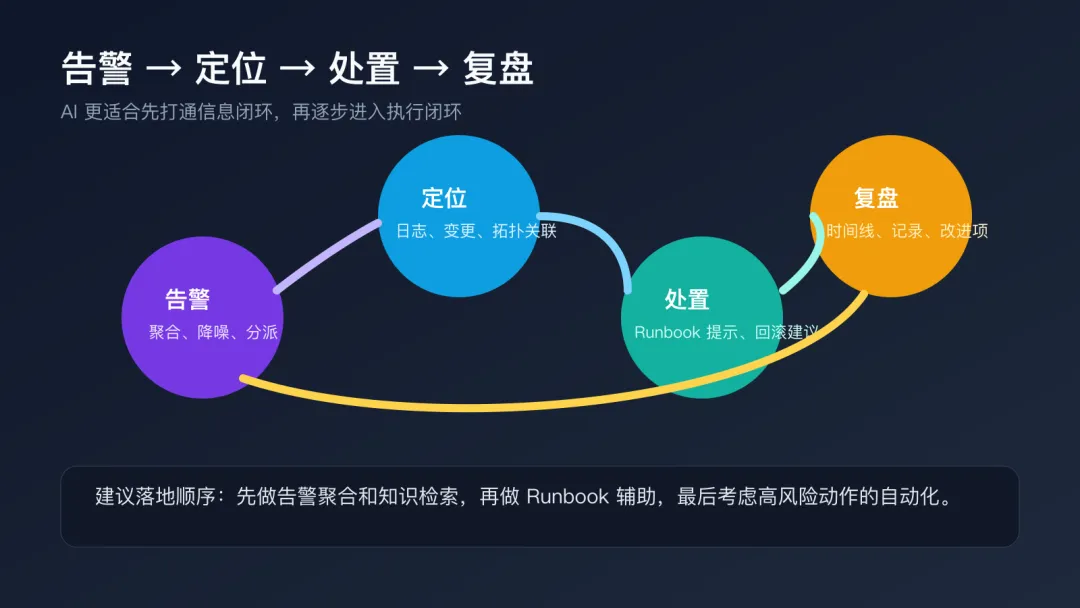
这些工作有一个共同点:它们不一定适合完全自动执行,但非常适合先由 AI 做信息组织和流程加速,人再负责判断和最终确认。 三、一个具体场景:AI 如何参与一次夜间告警处置 下面用一个接近真实运维现场的案例,来看 AI 在运维里到底能怎么用。 某业务系统在晚间发布后 10 分钟,监控平台连续发出应用延迟飙升、错误率上升、部分接口超时等多条告警。值班工程师需要在最短时间内确认:这是单点问题、连锁故障,还是发布引发的回归问题。 这套流程的问题,不是不能做,而是太依赖个人经验和临场判断。 如果值班的人经验丰富,可能几分钟就能抓到重点;如果是新人,或者恰好碰上多系统同时抖动,就很容易把时间耗在“找信息”和“确认该找谁”上。 在这个场景里,AI 最适合做的,并不是直接下命令,而是先把上下文拼起来。 第一步,AI 对多条告警做语义聚合。它会结合告警文本、服务拓扑、最近 30 分钟变更记录和历史相似事件,判断这些告警大概率属于同一故障卡片,而不是五六个彼此独立的问题。 第二步,AI 生成一份值班摘要。摘要里会告诉工程师:异常主要集中在哪个服务或依赖组件;是否发生在发布之后;最近是否出现过相似故障;建议优先拉起哪些角色参与排查。 第三步,AI 调用知识检索能力,从历史 Runbook、事故复盘和 FAQ 中找出最接近的处置路径。例如它可能给出这样的建议:优先检查新版本应用实例的错误日志;对比发布前后配置差异;观察数据库连接池和 Redis 响应时间;如果错误率在灰度实例集中,可优先回滚该批次。 第四步,AI 用对话方式辅助工程师执行 Runbook。比如提示:先确认异常是否只出现在新发布实例;再检查网关层是否同步放大了重试流量;如果回滚,先回滚哪一批、回滚后看哪些指标恢复。 第五步,故障处理结束后,AI 自动整理初版复盘材料,包括告警时间线、关键操作、回滚节点、影响时长和待补动作。 最直接的变化不是“AI 替代了值班工程师”,而是: 换句话说,AI 在这里的价值,不是让系统“自己修自己”,而是让团队先把故障处理链路从“靠人顶住”升级成“人机协同”。 四、这类场景为什么最容易落地 很多团队一谈 AI,就容易把目标设得过大,比如希望它直接根因定位、自动修复、自动闭环。 但在真实运维场景里,越高风险、越强副作用的动作,越不适合一开始就完全交给模型。 相反,像“告警聚合、知识检索、步骤提示、复盘整理”这种环节,既高频、又耗时,而且结果相对容易校验,反而更适合作为第一批落地场景。
收益直观。哪怕只把找资料和信息整合时间缩短一半,值班体验就会明显改善。
风险可控。AI 先做建议,人保留审批和最终执行权。
容易沉淀。每次故障处理后的结果,都可以继续反哺知识库和 Runbook。
便于扩展。先在一个场景跑通,后面再延伸到变更评审、补丁执行、容量治理,路径会清晰很多。
五、AI 运维落地最容易踩的 4 个坑 当然,AI 在运维里并不是接上就能用,真正做起来,最容易踩的通常是下面几个坑:
只关注模型能力,不关注流程接入。如果告警、工单、知识库、变更记录彼此割裂,再强的模型也只能“看见一部分”。
只做演示,不做持续复用。很多试点项目在演示时效果很好,但没有沉淀模板、规则和验证机制,最后很难真正进入值班流程。
没有边界意识。哪些动作只能建议、哪些可以自动执行、哪些必须人工确认,如果不提前划清,风险会被迅速放大。
知识库质量太差。如果底层 Runbook 过期、复盘记录混乱、资产标签不准,AI 只会更快地把错误经验扩散出去。
六、给运维团队的 3 条实用建议 如果你所在的团队也准备在运维里引入 AI,我更建议从下面三个方向开始:
先挑高频、重复、标准化场景。不要一开始就追求“全自动自治运维”,先从告警初筛、知识检索、变更预检这些容易见效的环节做起。
明确“AI 做什么,人做什么”。规则、审批、回滚、删除数据、权限变更等高风险动作,边界一定要清楚。AI 可以提建议,但不能替代责任主体。
把每一次使用过程沉淀成可复用机制。模板、Runbook、案例库、处置路径、复盘格式,这些东西一旦标准化,AI 才能越用越准,而不是每次都像重新开始。
结语 AI 真正带来的,不只是多一个工具,而是一次工作方式的重新分配。对运维团队来说,最先被改变的,往往不是命令本身,而是“怎么更快找到信息、找到人、找到正确步骤”的那条流程。 谁能更早把这些重复劳动标准化、把经验沉淀成可复用机制、再让 AI 接入其中,谁就更有机会在下一阶段建立新的效率优势。 你所在的团队,已经把 AI 用到运维流程的哪一步了?欢迎留言聊聊你看到的实际场景。
 夜雨聆风
夜雨聆风