当前时间: 2026-05-03 22:04:28
更新时间: 2026-05-03
分类:软件教程
评论(0)
AI"画图"和大语言模型有关系吗?
AI写文章和AI画图,这两个能力,有什么区别和联系
这条路从2012年2012年ImageNet竞赛冠军获得者设计的AlexNet开始,核心是CNN(卷积神经网络)。那时候AI学会了认猫、认狗、认红绿灯。后来Vision Transformer把Transformer架构引入视觉领域,再后来有了GPT-4V这样的多模态模型,能同时”看”和”说”。
这条路从GAN(生成对抗网络)开始,但真正的爆发是2020年后的Diffusion扩散模型。DALL-E、Midjourney、Stable Diffusion,还有现在的GPT-Image-2,都是这条路上的产物。
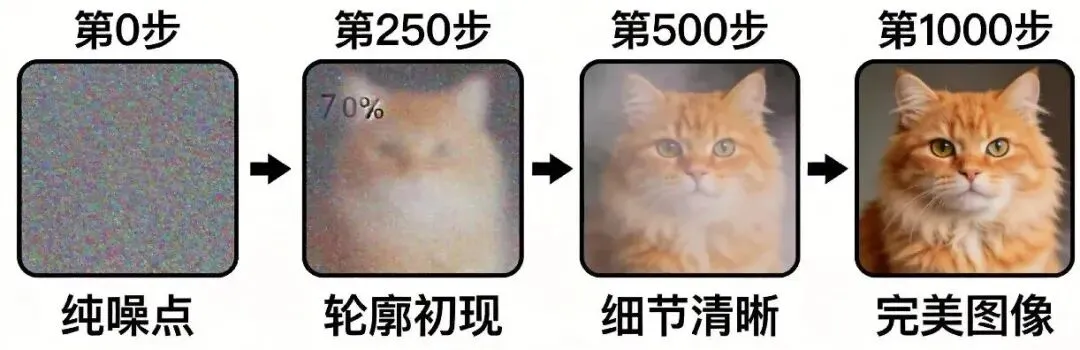
这个过程不是AI一次性画完的,而是在做一件事: 去噪 。
米开朗基罗面前有一块原始大理石,什么都看不出来,就像电视机雪花屏。
AI画图的过程叫做“去噪”,其实和米开朗基罗“雕刻”的过程差不多——
拿一张清晰的猫图,一步步加噪点,直到变成纯噪点。AI记住了每一步怎么加的。
让AI反过来学习——给它任何程度的噪点图,它都知道怎么还原。
训练了几亿张图后,AI脑子里就有了”正常的图应该长什么样”的概念。
-
-
学习素材超多。互联网上几十亿张图片,AI看了个遍。
-
语言和图像模型融合发展(我理解就是多模态技术呗)。语言模型负责”理解”,图像模型负责”画”,两者配合。
最新发布的GPT-Image-2被称为”首个会思考的图像模型”
——它不是简单地把文字变成图,而是会”推理”想要什么。
这意味着图像AI也在从”工具”变成“数字员工”和”合作者”。
在一块看不见的大理石上,AI正在按照我的描述,一刀一刀雕刻。每一刀都在去噪,每一刀都在接近我想要的样子。
 夜雨聆风
夜雨聆风