 夜雨聆风
夜雨聆风





想让 AI Agent 又稳又省钱?模型该这样分工

这两年用 AI 的人,大概都经历过一个很微妙的心理变化。
一开始,我们只关心一个问题:哪个模型最聪明?
后来慢慢发现,光聪明还不够。
你让顶级模型写方案、做判断、改代码,它确实强;但你让它一遍遍总结网页、压缩上下文、识别图片、跑一些重复的小任务,账单也会很强。更尴尬的是,一旦服务商限流、余额不足、接口抽风,整个智能体就像高速路上突然没油的车,任务卡在半路,用户只能干瞪眼。
所以,今天真正值得聊的,是“怎么搭一套模型组合”,而不只是盯着单个模型排名。
如果用一句话讲清楚:
主模型负责关键判断,工作模型负责高频处理,回退模型负责稳定接力,本地模型负责隐私和低成本。
这就是 Hermes Agent 这类智能体框架特别有意思的地方。它已经不再把 AI Agent 当成“一个聊天窗口”,而是把它当成一个可以调度多种模型、多个账号、多个工具的工作系统。
先把 AI Agent 想成一个小团队
很多小白第一次配置智能体,容易犯一个错误:所有事情都交给同一个模型。
比如主模型选 Claude 或 GPT,然后:
-
• 用户对话,它来; -
• 长文总结,它来; -
• 图片理解,它来; -
• 上下文压缩,它来; -
• 子任务拆分,它来; -
• API 出错后的补救,它还来。
听起来简单,实际很浪费。
这就像一家小公司请了一个顶级顾问,结果让他既定战略、又填表格、又接电话、又打快递单。能做,但用法太奢侈。
更合理的方式,是把智能体里的模型分成几类角色:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
理解了这个表,Hermes Agent 的很多配置就突然变得直观了。
它的重点在于,把 AI 模型变成一套“可调度的生产力团队”。
Primary:主模型一定要舍得用好模型
主模型是智能体的大脑。
它负责理解用户意图,决定要不要调用工具,判断搜索结果是否可信,写最终答案,必要时还要拆任务、纠错、反思、回滚。
这一层不建议为了省钱盲目降级。
原因很简单:主模型一旦判断错,后面再多高性价比模型都在替错误方向打工。
比如你让 Agent 帮你做一份行业研究报告,主模型需要决定:
-
• 该搜哪些关键词; -
• 哪些资料可信; -
• 是否需要读取本地文件; -
• 表格数据怎么解释; -
• 什么时候应该调用 Python 计算; -
• 最终报告采用什么结构; -
• 哪些结论需要谨慎表达。
这些环节更像“总导演”或“项目经理”,不能只看单次调用成本。
所以我的建议很明确:
主模型优先用 Claude、GPT 这类顶级模型。
它贵一点,但它决定了整个智能体的上限。尤其是涉及复杂写作、代码修改、商业判断、跨工具编排时,主模型的稳定性和理解力非常关键。
Auxiliary 工作模型:高频任务才是省钱关键
很多人不知道,AI Agent 背后有大量“看不见的执行任务”。
比如:
-
• 网页抓回来以后,要先做摘要; -
• 上下文太长了,要压缩; -
• 图片要识别; -
• 搜索结果要整理; -
• 子任务结果要归纳; -
• 长会话要保存记忆线索。
这些任务很重要,但不一定都需要最贵的模型。这里的 Auxiliary 不更像团队里的高频工作层:它承担量大、重复、上下文长、成本敏感的任务,让主模型把精力留给关键判断。
在实际配置里,vision、web summarization、上下文压缩、MoA 等任务,都可以单独指定模型。这样就不用让 Claude/GPT 从头到尾包办所有环节,而是把更适合高频处理的任务交给 DeepSeek-V4、Gemini Flash、本地 Qwen 等模型。
这也是成本优化最明显的地方。
举个很直观的例子:
你让智能体读 10 篇网页,最后写一篇文章。真正需要顶级模型发力的,是最后的选题判断、结构组织和表达。但前面 10 篇网页的初步摘要、要点抽取和信息清洗,完全可以交给高性价比模型先处理。
这有点像拍电影:总导演要把控成片质量,但摄影、灯光、场记也都是专业岗位,分工越清楚,整套系统越能跑起来。
Fallback:别等主模型挂了才想备胎
再强的模型服务,也会遇到现实世界的三个小怪兽:限流、报错、余额不足。
Hermes Agent 的 fallback providers 机制,就是为这种情况准备的。
这套机制的价值在于:当主模型遇到 rate limit、server overload、auth failure、connection drop 等问题时,Hermes 可以在不中断当前会话的情况下,切换到备用的 provider:model。
这对真实使用非常重要。
因为智能体执行任务时,往往已经超出“一问一答”的范围。它可能已经搜索了网页、读取了文件、跑了脚本、生成了中间结果。如果此时主模型突然限流,最糟糕的体验就是整个任务断掉。
有 fallback 以后,体验会像这样:
-
1. 先用 Claude/GPT 做主模型; -
2. 如果主模型接口出问题; -
3. Hermes 自动切到 DeepSeek-V4 或另一个备用提供商; -
4. 当前上下文继续保留; -
5. 任务接着往下跑。
这就像开车出远门,主油箱当然最好,但备胎和备用油桶也得有。
Credential Pool:多个账号轮询,解决“好模型不够用”
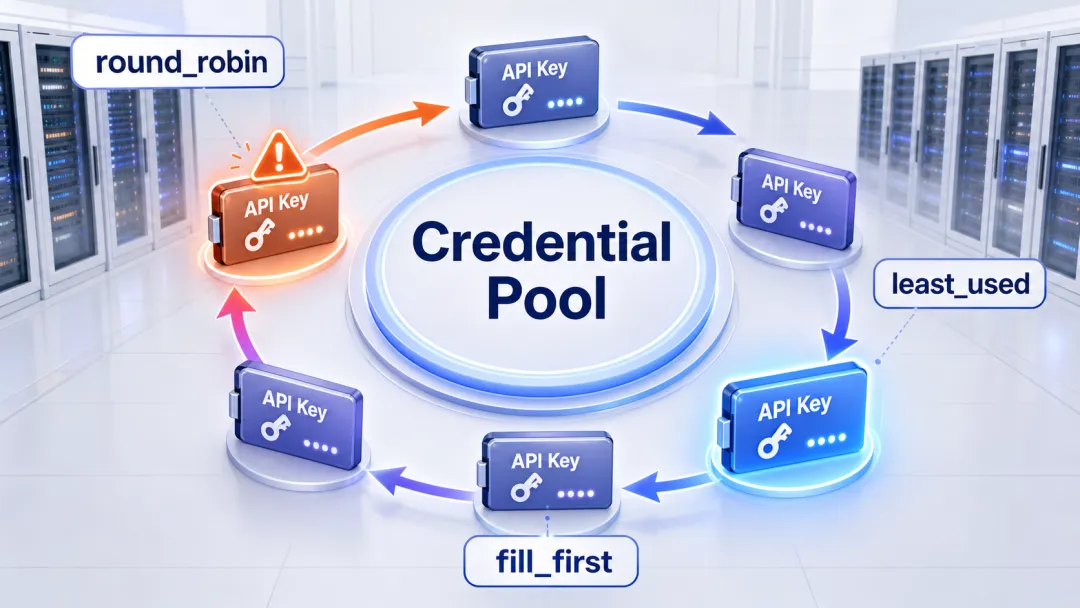
还有一个很多人忽视的配置:credential pools,凭证池。
简单说,它允许你给同一个 provider 配多个 API key 或 OAuth 账号。
这类凭证池的逻辑很好理解:当一个 key 遇到 rate limit 或 quota 问题时,系统自动切到同一 provider 下的另一个健康 key。常见轮询策略包括:
-
• fill_first:默认策略,先用第一个健康 key,用完再换; -
• round_robin:轮流使用,每次请求尽量平均分摊; -
• least_used:优先用请求次数最少的 key; -
• random:随机挑一个健康 key。
它和 fallback 的区别也很重要:
Credential Pool 是同一个服务商内部换账号;Fallback 是换到另一个服务商或另一个模型。
比如你有两个 OpenRouter key、两个 Anthropic key,credential pool 会先在同一类服务里轮询。等同一池子都用不了,再考虑 fallback 到 DeepSeek、Qwen、本地模型或其他备用线路。
这套逻辑很像机场调度:
-
• 同一个航司还有航班,就先改签到同航司; -
• 同航司都没票了,再换别的航司; -
• 实在不行,本地模型先顶上,保证任务不断。
为什么 DeepSeek-V4 适合做高频工作层和回退
DeepSeek-V4 的定位很精准:它是智能体里的主力干将。它的优势集中在长上下文、高性价比、API 可用、开源路线这些方向,特别适合承担大量中间处理和稳定接力。
按任务强度来分,可以把它理解成两个层次:
-
• DeepSeek-V4-Pro:更适合长上下文、复杂整理和回退接力; -
• DeepSeek-V4-Flash:更适合高频摘要、抽取、批处理和成本敏感任务。
对 AI Agent 来说,这类能力非常实用。智能体经常要读网页、读文档、压缩上下文、整理搜索结果,这些环节不是“低端活”,而是任务能不能持续跑下去的底座。
这就解释了为什么它适合放在 Hermes 的高频工作层和回退层。
坦率说,在特别复杂的跨工具规划、长链路纠错和最终表达上,Claude/GPT 这类顶级模型仍然更稳。但这不等于国产模型只能“打下手”,大量国际论坛上的例子证明,越来越多的国外企业也是使用这套搭配方案。更准确的说法是:关键判断交给最稳的主模型,大量高频处理交给 DeepSeek-V4 这样的高性价比模型。
-
1. 长上下文友好:适合处理长文档、长网页、长会话摘要。 -
2. 成本更低:大量中间任务可以交给它,主模型集中处理关键决策。 -
3. API 可用:可以接入 Hermes 的 provider/fallback 体系。 -
4. 开源路线:对企业和开发者更友好,便于后续私有化、评估和定制。
所以,一个很实际的搭配是:
-
• 关键判断:Claude/GPT; -
• 高频处理:DeepSeek-V4-Flash; -
• 长上下文整理和回退:DeepSeek-V4-Pro; -
• 简单批处理:DeepSeek-V4-Flash 或本地 Qwen。
这套方案的核心,是按任务特点分工,而不是按国别给模型排座次。
为什么本地层更适合用 Qwen 小模型
本地模型这一层,核心目标不是追大参数,而是三个字:够用、稳定、省心。
如果以普通 Mac 为例,尤其是 16GB 或 24GB 统一内存的机器,我更建议直接推荐 Qwen3.5-4B、Qwen3.5-9B 这一类小参数模型。它们的 4-bit / 5-bit GGUF 文件体积小得多,系统、浏览器、Hermes Agent、上下文缓存也都有余量,日常用起来不容易卡成 PPT。
比如:
-
• 16GB Mac:优先选 Qwen3.5-4B 或 Qwen3.5-9B 的 Q4 / Q5 量化; -
• 24GB Mac:可以更舒服地跑 Qwen3.5-9B,也可以把量化档位提高一点; -
• 如果只是做分类、摘要、草稿、批处理,本地 4B / 9B 往往已经够用。
部署也不用搞得很复杂。小白最容易上手的是 Ollama:下载安装到 Mac 后,一条命令就可以拉起本地模型,再通过 OpenAI-compatible 接口接入 Hermes Agent。
可以把它理解成:云端 Claude/GPT 负责关键拍板,DeepSeek-V4 负责高性价比的长上下文与高频处理,本地 Qwen 小模型负责隐私、低成本和日常小任务。
本地层要处理的,通常是这些任务:
第一,隐私敏感的预处理。
比如内部文档初步摘要、客户资料分类、会议纪要预处理。你不一定想把所有原始材料都发到云端。
第二,低成本高频任务。
比如每天自动整理一批文件、提取标题、做初步分类、生成待办草稿。这些任务如果全部走顶级云模型,账单会慢慢变成玄学。
第三,离线或弱网场景。
比如出差、演示、内网环境,本地小模型可以保证智能体还有基本可用性。
所以,这里不要把本地层讲成“参数越大越好”。对普通个人电脑来说,小模型更容易部署,也更符合这篇文章要给小白的操作路线。
更清晰的推荐是:个人电脑先用 Qwen 小参数模型,本地层做轻量跑腿;复杂判断继续交给主模型。
一套给普通用户的推荐配置
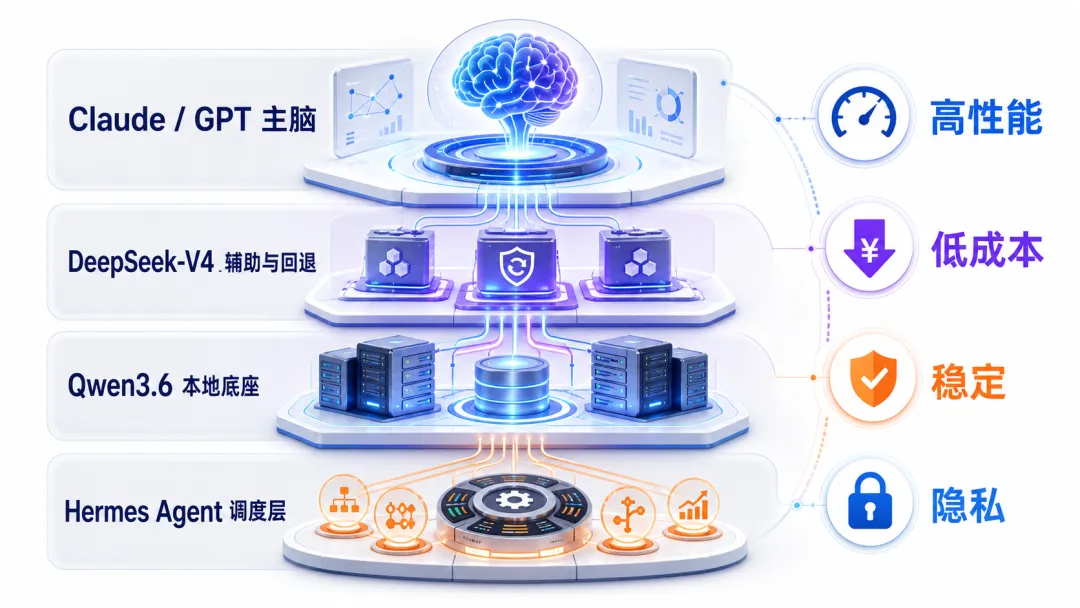
如果你刚开始搭 Hermes Agent,我会建议按这个思路来:
1. 主模型:顶级模型
用于:对话主脑、复杂任务规划、最终输出。
推荐:
-
• Claude Sonnet/Opus 系列; -
• GPT 顶级模型; -
• 或通过 OpenRouter 、清心API等第三方平台接入的高质量 frontier model。
2. 高频工作模型:DeepSeek-V4-Flash
用于:网页摘要、长文抽取、上下文压缩、批量中间任务。它承担的是工作主力层,不是“低配替补”。
原因:高性价比、响应快、长上下文友好,适合中国用户把成本和稳定性一起控住。
3. 回退模型:DeepSeek-V4-Pro 或另一路 Claude/GPT
用于:主模型限流或报错时接管。
如果你更看重稳定,可以选择另一个 provider 的同等级模型;如果你更看重成本,可以让 DeepSeek-V4-Pro 做第一回退。
4. 本地模型:Qwen3.5-4B / 9B 小模型
用于:隐私任务、低成本小任务、分类、摘要、批处理和草稿生成。
部署方式优先推荐 Ollama:安装后用一条命令运行本地模型,再通过 OpenAI-compatible 接口接入 Hermes。16GB Mac 优先 4B / 9B 低量化;24GB Mac 可以更舒服地跑 9B 或稍高量化。
5. 账号池:同一 provider 配多个 key
用于:减少限流、提高稳定性。
策略建议:
-
• 日常用 round_robin,请求平均分摊; -
• 如果某个账号额度特别大,可以用 fill_first; -
• 如果想尽量均衡消耗,用 least_used。
真正的智能体,不该只会“选模型”
过去我们谈 AI,常常像买手机:哪个芯片强,哪个跑分高,哪个发布会更炸。
但 AI Agent 进入真实工作流以后,问题变了。
你要考虑的不只是聪明,还包括:
-
• 稳不稳定; -
• 成本能不能控; -
• 出错能不能接上; -
• 隐私能不能守住; -
• 长任务能不能跑完; -
• 多账号、多模型、多工具能不能协同。
Hermes Agent 这类框架的价值就在这里。它把“模型选择”升级成“模型调度”。
主模型负责大脑,工作模型负责高频处理,回退模型负责保险,本地模型负责隐私和低成本,credential pool 负责把好模型的账号资源用得更平滑。
如果你只是偶尔问 AI 一个问题,单模型够用。
如果你真的想让 AI Agent 帮你写文章、做报告、查资料、改代码、跑脚本、发消息、定时执行任务,那就应该尽早接受一个现实:
未来好用的 AI 系统,大概率会从“一个模型包打天下”,走向“一组模型各司其职”。
这就像团队协作。
老板不需要亲自搬砖,专家不该一直填表,实习生也不能拍板战略。把人用对,组织效率才会上来;把模型用对,智能体才真的跑得起来。
别追求“一把神剑走天下”。
给智能体配一套工具箱,才是更长期、更省钱、更稳定的玩法。