 夜雨聆风
夜雨聆风





AI 能解世界难题,却改不好你的文档
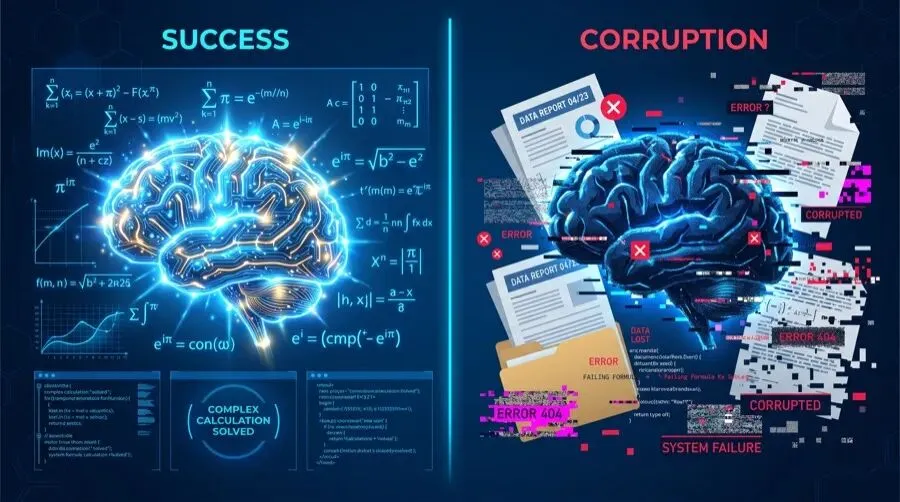
AI 的双面性:解得了数学难题,改不好日常文档
2026 年 5 月的两个热帖,把 AI 的”两面性”摊在了桌面上。
一边是菲尔兹奖得主 Timothy Gowers 的实测:ChatGPT 5.5 Pro 用不到 1 小时,完成了一项 PhD 级别的组合数学研究,把指数级上界改进为多项式上界。MIT 学生 Isaac Rajagopal 看了结果后说,这个思路”completely original”——完全原创。
另一边是微软研究院的论文 DELEGATE-52:19 个主流大模型在 52 个专业领域的文档编辑任务中,前沿模型平均腐蚀 25% 的文档内容,所有模型平均腐蚀 50%。只有 Python 代码领域勉强达标——因为代码有编译器校验,错了就报错。
同一个星期,同一批模型。解得了世界难题,改不好你的周报。
一小时 vs 人类数月的效率震撼

ChatGPT 5.5 Pro 在组合数学上的突破
Gowers 的实验起点很日常。他在 Mel Nathanson 的一篇论文里挑了几个开放问题,丢给 ChatGPT 5.5 Pro,想看看它能不能处理。
第一个问题:给定整数集合 A,其 h 重和集 hA 的可能大小集合记为 R(h,k)。Nathanson 证明了当 h=2 时,所有中间大小都可以实现。但对于一般的 h,R(h,k) 的完整描述仍是开放问题。更具体的一个子问题是:如果要构造一个大小为 k 的集合,使其 h 重和集的大小为某个指定值,这个集合的直径——也就是元素最大值——最小可以是多少?
ChatGPT 5.5 Pro 思考了 17 分 5 秒,给出了一个构造,把直径上界从指数级改进为二次多项式级——这是最优的,不能再好了。Gowers 让它写成 LaTeX 预印本格式,2 分 23 秒后交稿。Gowers 花了一些时间验证,结论是对的。
Gowers 没停手,又丢了一个更难的问题:MIT 学生 Isaac Rajagopal 之前证明了对于固定 h,直径关于 k 的依赖是指数级的。Gowers 问 ChatGPT 能不能把这个指数上界收紧。
16 分 41 秒后,ChatGPT 把指数级改进为关于 k 的指数级——比之前好,但仍非多项式。Gowers 让它写成预印本,这次花了 47 分 39 秒。Rajagopal 看了说”looks correct”。
Gowers 贪心了一把,问能不能直接推到多项式级。13 分 33 秒后,ChatGPT 说”乐观”,但有几个技术细节要验证。9 分 12 秒后验证完毕。31 分 40 秒后,预印本出炉。
Rajagopal 的评语很直接:”almost certainly correct”——而且不是在逐行层面,是在思想层面。他专门写了一节客座评论,解释 ChatGPT 的核心贡献:用 ε-dissociated sets 来控制低阶关系,这个想法”completely original”。Rajagopal 的原话是:”This idea is completely original.”
“ChatGPT’s idea to use ε-dissociated sets to control relations of order at most h feels quite ingenious. As far as I can tell, this idea is completely original.”
— Isaac Rajagopal, MIT
Gowers 自己给这个结果定了性:水平相当于”一个相当合理的组合数学 PhD 章节”。不算惊天动地,毕竟它很大程度上建立在 Rajagopal 的工作之上,但绝对是非平凡的扩展。一个 PhD 学生要做出来,得花不少时间消化 Rajagopal 的论文,找哪里还能优化,熟悉各种代数技巧。
ChatGPT 用了不到 1 小时。
Gowers 提到一个他不愿意深谈的点——不少让人”哇”的 LLM 解法,仔细一查其实有先例。但这次不一样。Rajagopal 是领域内的专家,他明确说这个思路是原创的。LLM 在某些特定类型的数学问题上,已经跨过了”组合已有知识”的门槛,开始产生人类专家认可的新思路。
但 Gowers 也留了一个警示:给新手研究生布置”温和”的入门问题,这个传统方法失效了。LLM 能解温和问题,那人类新手得去证明 LLM 证不了的东西——门槛被抬高了。
52 个领域,19 个模型,无一幸免的文档腐蚀

DELEGATE-52:长工作流中的文档腐蚀
就在 Gowers 发博客的同一天,微软研究院的 DELEGATE-52 论文也在 HN 上被热议。这篇论文的研究问题很直接:如果你把文档编辑任务委托给 LLM,让它在长时间工作流中反复操作,文档会变成什么样?
答案是:面目全非。
DELEGATE-52 构建了 52 个专业领域的工作环境——从 Python 代码、Docker 配置,到晶体学、音乐谱表、家谱、食谱——每个环境包含真实的文档(约 15k tokens)和 5-10 个复杂编辑任务。测试了 19 个 LLM,包括 Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4 等前沿模型。
实验设计很巧妙:每个编辑任务都是”可逆”的——先执行一个正向编辑,再执行对应的反向编辑,理论上应该回到原始文档。通过比较往返前后的文档相似度,就能量化 LLM 引入了多少”腐蚀”。
结果:
前沿模型(Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4)在 20 轮交互后,平均腐蚀 25%的文档内容。
所有 19 个模型的平均腐蚀率:50%。
唯一达标的领域:Python 代码(17/19 个模型实现无损编辑)。
80%的模拟条件下,模型严重腐蚀文档( degradation ≥ 20%)。
Python 为什么特殊?因为代码有编译器。写错了就报错,模型能根据错误反馈修正。文本、乐谱、晶体学文件没有这种自动校验机制,错误就悄悄留在那里,越积越多。
论文还发现几个反直觉的结论:
1. 短交互性能不能预测长交互性能。GPT 5 和 Kimi K2.5 在前 2 轮表现几乎一样(91.5 vs 91.1),但 20 轮后差距拉到 48.3 vs 64.1。Gemini 3 Flash 早期落后 Mistral Large 3 达 6.4 分,最后却反超。这意味着你试了几轮觉得”还行”,不代表长期委托没问题。
2. Agentic 工具使用不能改善性能。给模型配上文件读写、代码执行工具,DELEGATE-52 上的表现没有提升。论文作者补了一句”这不是优化的 state-of-the-art agent 系统”,但至少说明,简单的工具增强解决不了根本问题。
3. 错误不是”千刀万剐”,而是”暴击”。模型在大多数轮次里表现近乎完美,但偶尔一轮就掉 10-30 分。这种”稀疏但严重”的错误模式最危险——你很难通过抽查发现它。
HN 上的热评把这种现象比作传话游戏和反复保存 JPEG——每次通过 LLM,意图就被稀释一点,细节被磨平,棱角被削掉。一位评论者造了个词:semantic ablation(语义消融)。另一位说 LLM 是 mean reversion machines(均值回归机器),越超出训练分布的任务,越会被拉回到一个同质化的抽象均衡态。
“LLMs are mean reversion machines, the more ‘outside of their training’ the context/work load they are currently dealing with, the more they will tend to gradually pull that into some homogenous abstract equilibrium.”
— HN 用户 timacles
还有一位评论者(Simon Willison)提出了一个务实的观察:频繁使用 LLM 的人其实早就知道”不要把长内容反复过 LLM”。DELEGATE-52 的价值在于用系统性的数据量化了这个直觉,并且证明了一个很多人不愿面对的事实——即使是当前最好的模型,在长委托工作流中也是不可靠的。
能力 vs 可靠性:两个不同的维度
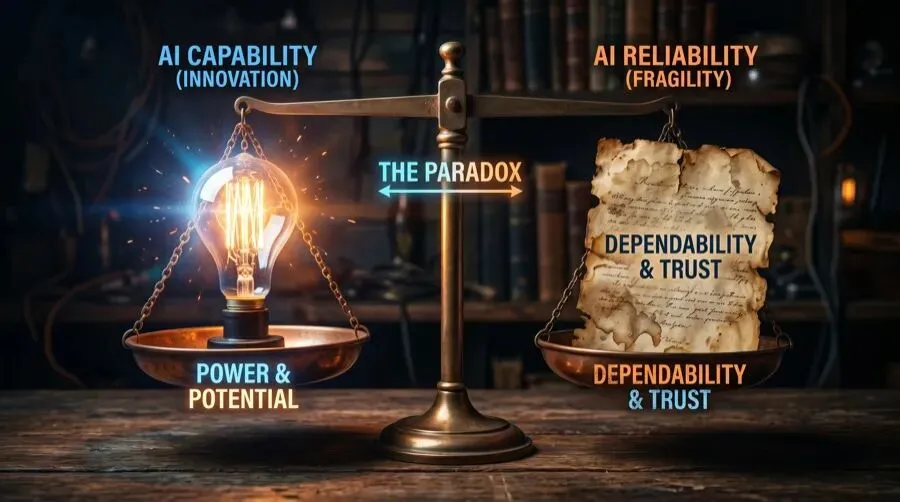
能力 vs 可靠性:AI 的两个独立维度
这两个实验放在一起,揭示了一个被很多人混淆的区别:能力(capability)和可靠性(reliability)是两回事。
ChatGPT 5.5 Pro 在 Gowers 的实验中展现了惊人的”能力”——在组合数学这个对精确性要求极高的领域,它能产生被领域专家认可的原创思路。这是”峰值性能”的体现:给定一个清晰定义的问题、充足的思考时间、和人类专家的验证闭环,LLM 可以产出顶级成果。
但 DELEGATE-52 测试的是”可靠性”——在长时间、多轮次、多领域的委托工作流中,模型能否持续保持精确性,不引入静默错误。答案是:不能。即使是同一个”ChatGPT 5.5 Pro”级别的模型(论文测试了 GPT 5.4,与 5.5 同属 GPT-5 系列),在文档编辑任务中也会腐蚀内容。
这有点像什么?像一位能拿诺贝尔奖的科学家,却记不住自己的银行卡密码。或者像一位能写交响乐的作曲家,却会在抄谱时漏掉升降号。
Gowers 的实验和 DELEGATE-52 的另一个关键差异是验证机制。Gowers 花了时间验证 ChatGPT 的证明;Rajagopal 作为领域专家审阅了结果。这是一个”人类在环”的闭环。而 DELEGATE-52 模拟的是”委托”场景——用户把任务交给 AI,没有专家逐轮审查。论文的标题说得直白:”LLMs Corrupt Your Documents When You Delegate”。
HN 上一位评论者(andrewljohnson)提出了一个务实的解决方案:LLM 编辑应该产生确定性的 diff,用户审查后再接受。这和代码 review 一样——不是不让 AI 写代码,而是不让 AI 直接 merge 到 main 分支。
另一位评论者(wtetzner)的观点更深入:问题出在我们让 LLM 做了太多工作。应该设计 agent,让 LLM 只做最薄的一层——把自然语言意图翻译成确定性流程,最小化对 LLM 的往返调用。
这两个实验的对比,本质上是在问——AI 到底是”工具”还是”合作者”?Gowers 的实验里,AI 是合作者,人类数学家提供方向、验证结果。DELEGATE-52 的实验里,AI 被当成工具,用户期望它”忠实地执行”而不引入错误。当 AI 作为工具时,它的不可靠性暴露无遗;当 AI 作为合作者时,它的能力令人惊艳。
所以当前 LLM 的最佳使用方式可能不是”委托”,而是”协作”。不是”你帮我做了”,而是”我们一起做,我负责把关”。
给实际工作流的启示
这两篇研究对实际工作有什么具体启示?挑几条实用的:
1. 长文档别反复过 AI。HN 上的”JPEG 反复保存”比喻很贴切。如果你有一篇重要文档,不要让它在 AI 工作流里来回传。每次传递都是一次”语义消融”。
2. 代码可以委托,文本不行。DELEGATE-52 的数据很清晰:Python 是唯一达标的领域。原因是代码有编译器、有测试、有类型系统做自动校验。文本没有这些护栏。
3. 用 diff 模式,不用重写模式。让 AI 生成修改建议(diff),而不是直接输出修改后的完整文档。人类 review 后再应用。这和代码 review 的逻辑一样。
4. 短期测试不能代表长期表现。DELEGATE-52 的核心发现之一:前 2 轮的表现和 20 轮后的表现相关性很弱。试了几轮觉得”还行”就放手,是危险的。
5. 领域越”软”,腐蚀越严重。音乐谱表、小说、财报、食谱这些”自然语言为主”的领域,腐蚀率远高于代码和结构化数据。如果你的工作涉及这些领域,对 AI 输出要格外警惕。
6. Agentic 工具不是万能药。给 AI 配了文件读写、代码执行工具,DELEGATE-52 上的表现没有提升。工具本身不能解决 LLM 的”均值回归”倾向。
Gowers 在博客结尾提了一个他自己也没答案的问题:AI 产出的数学成果,该怎么归档?期刊不合适,arXiv 有政策限制 AI 内容。也许需要一个新的仓库,由人类数学家验证后收录。
这背后是个更深层的变化:AI 不是在”替代”人类研究者,而是在重新定义”研究”的边界和流程。验证、归档、信用归属——这些学术基础设施,都是为人类设计的。AI 的出现,让这些基础设施显得过时了。
但 DELEGATE-52 提醒我们:在欢呼 AI 能力的同时,别忘了它的另一面。它能在一小时内解决你花几个月才能想通的数学问题,也能在你不知情的情况下,把你的文档改得面目全非。
能力在飙升,可靠性在掉队。这个 gap,可能是 2026 年 AI 应用最大的风险点。
“The lower bound for contributing to mathematics will now be to prove something that LLMs can’t prove, rather than simply to prove something that nobody has proved up to now and that at least somebody finds interesting.”
— Timothy Gowers
如果你的工作既需要 AI 的”峰值能力”(创造性、推理、复杂问题解决),又需要”长期可靠性”(文档编辑、数据处理、持续维护),你会怎么设计你的人机协作流程?
欢迎在评论区聊聊你的实践。