 夜雨聆风
夜雨聆风





ICSE’26|再也不用翻官方API文档了!用Stack Overflow自动生成API
基于众包知识的API文档
自动化生成

作为开发者,你一定有过这样的噩梦:
调用一个新 API,翻遍官方文档,只找到一句语焉不详的「该方法用于处理数据」;遇到 bug,官方文档完全没提,只能去 Stack Overflow 搜,结果要翻十几页长帖,从各种吐槽和歪楼里找有用的答案;好不容易找到解决方案,结果是 3 年前的旧版本,现在早就不能用了……据统计,70% 以上的官方 API 文档存在内容过时、信息不全、质量低下的问题,开发者每天要花 1-2 小时在找 API 用法上。
好消息是!2026 年 ICSE 软件工程顶会的最新研究,彻底解决了这个问题 ——
来自普渡大学、加州大学戴维斯分校的团队,提出了一个叫AutoDoc的工具,能自动从 Stack Overflow 的海量讨论中,提取开发者真正需要的 API 知识,生成比官方文档更全面、更实用、更准确的 API 文档。
今天这篇文章,我们就来拆解这个顶会成果,看看它是怎么做到的,以及对你有什么用。

摘要
API 文档是开发者学习和使用 API 的核心依据。但众所周知,大量官方 API 文档存在内容过时、信息不全的问题。为解决这一挑战,本文提出了名为 AutoDoc 的全新方法,该方法可从堆栈溢出(Stack Overflow,简称 SO)平台的在线讨论中提取 API 知识,进而生成 API 文档。AutoDoc 借助经过微调的稠密检索模型,从 SO 帖子中识别 7 类 API 知识,随后利用 GPT-4o 将这些帖子中的 API 知识汇总为简洁的文本内容。同时,本研究设计了两个专用模块,用于解决大语言模型(Large Language Models,简称 LLMs)生成内容中的幻觉与信息冗余问题。
本研究基于不同流行度的 48 个 API,将 AutoDoc 与 5 个对比基线方法进行了评估。结果表明,AutoDoc 生成的 API 文档准确率最高提升 77.7%,内容重复率降低 9.5%,同时包含 34.4% 官方文档未覆盖的知识。本研究还测试了 AutoDoc 对不同大语言模型选型的敏感性,发现尽管规模更大的大语言模型能生成质量更高的 API 文档,但 AutoDoc 可让小型开源模型(如 Mistral-7B-v0.3)取得与之相当的效果。最后,本研究通过用户研究评估了 AutoDoc 生成 API 文档的实用价值,所有参与者均认为,与对比基线方法相比,AutoDoc 生成的 API 文档更全面、更简洁、实用性更强。这一结果表明,通过精心设计对抗大语言模型幻觉与信息冗余的方案,利用大语言模型实现 API 文档自动化生成具备可行性。

研究动机
API 文档是开发者学习和使用 API 的核心依据,但官方文档普遍存在内容过时、信息不全、缺乏实践向内容的问题,无法满足真实开发需求;
Stack Overflow 平台积累了海量实时、贴近开发实践的 API 众包知识,能有效弥补官方文档的信息缺口,但这些知识分散在海量冗长的讨论帖中,开发者检索、筛选的时间成本极高;
同时现有解决方案存在明显短板,传统基于规则或机器学习的方法灵活性差、依赖大量人工标注、泛化能力不足,而直接用大语言模型生成文档则存在幻觉严重、内容冗余、与官方文档高度重叠、增量价值低的问题,因此亟需一种能自动化从众包知识中提取、提纯并整合高质量 API 文档的新方法。

方法
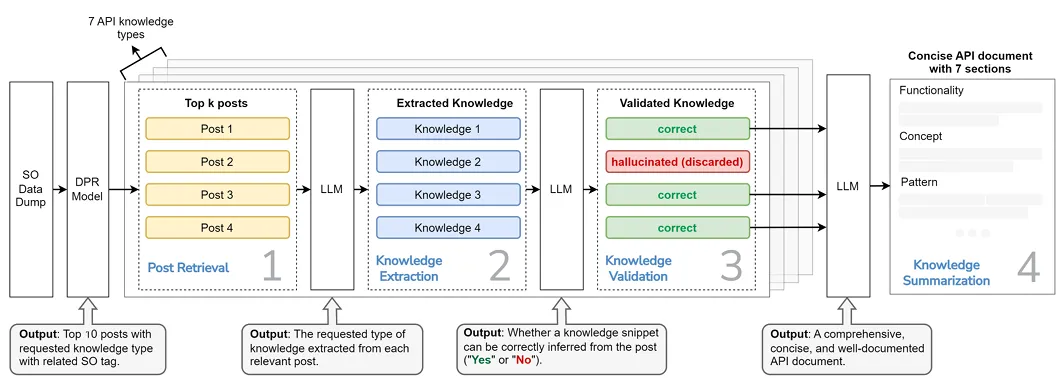
本节将介绍 AutoDoc 的四个核心组件。
整体流程如上图所示。
1、相关帖子检索
该步骤旨在解决 Stack Overflow 全量数据量过大无法直接输入大语言模型的问题,以 Dense Passage Retrieval 稠密段落检索模型为基础,针对 SO 帖子独特的技术语言特征和开发者讨论语境,使用 14.4 万条 SO 问题帖与 17.5 万条点赞数≥5 的高赞回答帖构建领域微调数据集,通过对比学习完成模型的 SO 场景专项适配;随后为每个 API 的 7 类核心知识分别设计专属检索查询词,为每类知识召回排名前 10 的高相关回答帖,最终使 DPR 模型的整体检索准确率提升 13%,其中概念、替代方案类知识的检索准确率提升 15%,为后续知识抽取过滤了大量无关噪声。
2、知识抽取
该步骤负责从检索到的 SO 帖子中精准提取对应类型的 API 知识,基于 GPT-4o 设计了包含上下文信息、抽取指令、API 描述、知识类型定义、知识示例、待抽取帖子 6 个字段的标准化少样本提示词模板;创新性地采用 “先校验相关性、再执行抽取” 的逻辑,要求大语言模型先判断帖子是否包含目标类型知识,若不包含则直接输出 “无对应知识” 并丢弃该帖子,若包含则按规范抽取结构化知识片段,同时所有 API 描述均由 GPT-4o 基于官方文档自动生成以避免人工标注偏差,最终实现了 93.7% 的知识抽取准确率,彻底过滤了检索环节引入的无关帖子干扰。
3、知识校验
该步骤是缓解大语言模型幻觉、保障生成文档可靠性的核心环节,采用 “源帖锚定的 LLM 自校验” 机制,以原始 SO 帖子作为唯一事实依据,将抽取得到的知识片段与对应的原始帖子一同输入大语言模型,让模型反向判断该知识能否从原帖中精准提取、语义是否完全一致,无法通过校验的幻觉内容或与原帖不符的错误信息会被直接丢弃;该模块不仅使生成文档的整体准确率提升了 3.7%,还过滤了大量无来源的通用冗余内容,间接降低了 15.2% 的文档重复率。
4、知识汇总
该步骤用于解决多源 SO 帖子抽取知识的重复冗余问题,并生成符合开发者阅读习惯的结构化文档,首先将所有通过校验的知识片段按照功能、概念、使用模式等 7 类核心知识进行分模块整理,再让大语言模型对重复、同义的知识片段进行合并、同义改写与内容精简,最后严格按照预设的 7 类知识章节顺序,输出逻辑清晰、结构规范的完整 API 文档;该模块使生成文档的内容重复率降低了 31.7%,内容唯一性比纯大语言模型直接生成方法最高提升 9.5%,在用户研究中获得了开发者对文档结构与简洁性的高度认可。
创新点
本文的核心创新点如下:
1、提出了端到端的AutoDoc完整 Pipeline:首次实现了 “SO 帖子检索→分类型知识抽取→幻觉自校验→去重结构化汇总” 的全流程自动化,直接输出覆盖 7 类开发者需求的规范 API 文档,解决了传统方法只能抽取零散句子、纯 LLM 生成增量价值低的问题。
2、实现了SO领域适配的精准检索:用 14.4万条SO问题帖和17.5万条高赞回答帖微调 DPR模型,解决通用检索模型看不懂技术语言的问题,整体检索准确率提升13%。
3、设计了轻量化的幻觉缓解机制:提出 “源帖锚定的LLM自校验” 方法,以原始SO帖子为唯一事实依据反向验证知识,使文档整体准确率提升3.7%,有效过滤无来源的虚假内容。
4、解决了多源知识的冗余问题:按 7 类知识分模块做智能合并去重,将文档重复率降低 31.7%,内容唯一性比纯GPT-4o生成提升 9.5%。
5、大幅降低了大模型依赖:AutoDoc的流程架构不绑定特定大模型,即使是7B参数的 Mistral小模型,也能达到84.9%的准确率和 34.1%的增量知识占比,适配资源受限的落地场景。

实验
本研究的定量实验构建了覆盖Java、Android、Kotlin、TensorFlow四大主流开发生态的标准化评估基准,通过分层抽样选取了48个不同流行度的API(高、中、低流行度API各16个),将AutoDoc与5种对比基线方法进行系统对比,包括SISE、API caveat两种传统API文档生成方法,以及GPT-4o的零样本、少样本、思维链三种直接生成方法;实验由两位作者采用双人交叉标注方式完成所有数据标注,经两轮标注校准后,三个指标的科恩卡帕系数分别达到0.95、0.91和0.88,确保了标注结果的高可靠性,整个标注过程累计耗时102人/时。
本研究通过实验,回答以下 7 个问题:
RQ1:与现有方法相比,AutoDoc 生成 API 文档的准确率与全面性表现如何?生成内容中有多少知识未被官方文档覆盖?
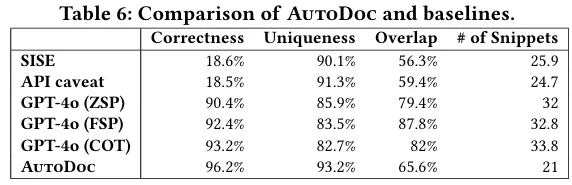
AutoDoc 生成的 API 文档在所有核心指标上全面超越基线方法,正确率达 96.2%,比 SISE、API caveat 等传统非 LLM 方法最高提升 77.7%,比 GPT-4o 思维链提示的最优基线高 3%;内容唯一性达 93.2%,比 GPT-4o 的三种直接生成方法高出约 10%;与官方文档的重叠度仅为 65.6%,平均包含 34.4% 官方文档未覆盖的增量知识,而 GPT-4o 直接生成的文档因依赖预训练内部知识,与官方文档的重叠度普遍在 80% 左右,增量价值显著更低。
RQ2:生成文档中的错误信息由哪些因素导致?
AutoDoc 生成的 38 条错误知识片段可分为三类,其中无 SO 依据的幻觉是最主要的错误来源,占比 50%,表现为模型编造无法追溯到任何检索帖子的虚假内容;其次是对 SO 帖子内容的误解读,占比 36.8%,主要是模型对原帖内容进行过度泛化、错误分类或生成误导性摘要;占比最低的是 SO 原帖原生错误,占 13.2%,源于模型直接复用了检索帖子中本身存在的错误或误导性信息。
RQ3:不同方法生成的文档之间,互补性达到何种程度?
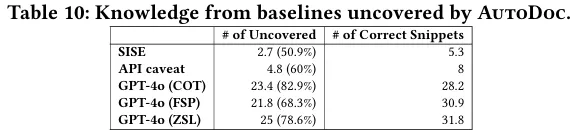
AutoDoc 与不同基线方法的互补性存在显著差异,与 SISE、API caveat 等同样基于 SO 帖子抽取知识的传统方法互补性较低,其未覆盖的正确知识占比分别仅为 50.9% 和 60%;而与不依赖 SO 帖子、仅靠内部知识生成文档的 GPT-4o 系列方法互补性极高,GPT-4o 零样本、少样本、思维链方法生成的正确知识中,分别有 78.6%、68.3%、82.9% 未被 AutoDoc 覆盖,这一差异主要源于 GPT-4o 的知识主要来自官方文档,而 AutoDoc 的知识主要来自 SO 众包实践内容。
RQ4:API 的流行度对 AutoDoc 的效果有何影响?

AutoDoc 的性能随 API 流行度的降低呈现合理的下降趋势,正确率方面,高流行度 API 达 99.1%,中等流行度为 96.3%,低流行度仍保持 91.1%;唯一性方面,低流行度 API 表现最差(90.7%),原因是相关 SO 讨论帖数量不足,模型需依赖内部知识补全空白章节,易引入重复的通用内容;重叠度方面,低流行度 API 与官方文档的重叠度最高(70.6%),高流行度 API 最低(58.4%),因为低流行度 API 的 SO 讨论中未被官方记录的增量知识更少。
RQ5:AutoDoc 的每个组件对整体效果的贡献度分别是多少?
AutoDoc 的四个核心组件均对最终效果有不可替代的贡献:经过 SO 数据微调的 DPR 模型,整体检索准确率比原始 DPR 提升 13%,其中概念和替代方案类知识的检索准确率提升最多(15%);知识抽取组件的准确率达 93.7%,能有效过滤检索引入的无关帖子;移除知识校验组件后,文档整体准确率下降 3.7%,重复率上升 15.2%;移除知识汇总组件后,文档重复率大幅上升 31.7%,充分证明了幻觉缓解和去重模块的核心价值。
RQ6:AutoDoc 对大语言模型选型的敏感性如何?
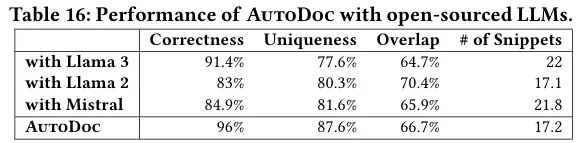
AutoDoc 对不同规模的 LLM 均有良好的适配性,替换为开源模型后性能呈现合理的梯度下降:Llama 3-70B-Instruct 表现最优,正确率达 91.4%;Mistral-7B-v0.3 虽为 7B 参数的小模型,但正确率达 84.9%,与 70B 参数的 Llama 2-70B-Chat 效果相当,且生成的知识片段数量最多,这得益于其混合专家架构的优势;所有模型均能生成包含 7 类知识的结构化文档,差异主要体现在代码示例的使用和格式一致性上。
RQ7:温度参数设置对 AutoDoc 的效果有何影响?

AutoDoc 的生成效果对温度参数的变化不敏感,在 0、0.5、0.8 三种常用温度设置下,文档的正确率、唯一性、重叠度均无显著波动,且同一温度下的两次重复实验结果也高度一致,例如温度为 0 时两次实验的正确率分别为 95.3% 和 93.9%,温度为 0.5 时分别为 95.7% 和 94.5%,证明 AutoDoc 的流程设计具备极强的稳定性,生成结果可复现性高。

除此之外,本研究还开展用户研究,旨在验证 AutoDoc 生成 API 文档在真实开发场景中的实用价值,共招募 12 名平均拥有 5.2 年编程经验的学生开发者,从实用性、整体概览性、全面性、简洁性、实践适配性五个维度,让参与者盲测对比 AutoDoc、SISE 与 GPT-4o 零样本提示生成的 API 文档,实验采用平衡设计确保每份文档由 4 名不同参与者评估,并随机打乱文档呈现顺序以降低偏差;结果显示平均 80% 的参与者在全部五个维度中均优先选择 AutoDoc 生成的文档,其中 88% 的参与者认为其实用性最强,83% 的参与者认为其对 API 的整体概览呈现效果最好,参与者普遍认可 AutoDoc 文档章节结构清晰、内容聚焦实践且无信息过载的优势,同时也提出了增加知识片段的原帖来源追溯、自动高亮官方文档未覆盖增量知识的优化建议。


讨论
本研究证实其可从Stack Overflow众包知识中提取34.4%官方文档未覆盖的增量实践知识,能有效弥补官方文档的信息缺口;同时验证了基于源帖锚定的LLM自校验机制可提升3.7%的文档准确率,为缓解LLM幻觉提供了轻量化可行方案,还揭示了通用NLP模型应用于软件工程任务时,领域微调的必要性——SO数据微调使DPR检索准确率提升13%。
在此基础上,研究明确了当前方案的两大核心局限性:一是低流行度API因SO讨论帖不足,效果仍有下降空间,且存在少量无法溯源的幻觉内容,未来计划增加知识片段的原帖来源追溯功能以提升用户信任度;二是生成内容仍有部分与官方文档重叠,易降低开发者的使用意愿,后续将开发官方文档对比模块,自动过滤重复内容并高亮增量知识,进一步提升文档的实用价值。

结论
本文提出了名为 AutoDoc 的 API 文档生成新方法,其核心思路是利用堆栈溢出平台中丰富的 API 知识,对官方 API 文档进行补充增强。具体而言,AutoDoc 通过微调后的 DPR 模型,从 SO 全量数据集中识别包含 API 知识的相关帖子,随后利用 GPT-4o 完成 API 知识抽取、知识校验与知识汇总,最终生成包含 7 类 API 知识的完整 API 文档。
评估实验表明,与基线方法相比,AutoDoc 生成的 API 文档准确率最高提升 77.7%,内容唯一性最高提升 9.5%。本研究的代码与数据艺开源,为相关领域的复现研究与后续工作提供支持。
END
