 夜雨聆风
夜雨聆风





OpenClaw 发展至今:从“会做事”到“能进化”,还差多远?
arxiv:http://arxiv.org/abs/2604.17308
http://arxiv.org/abs/2604.08523
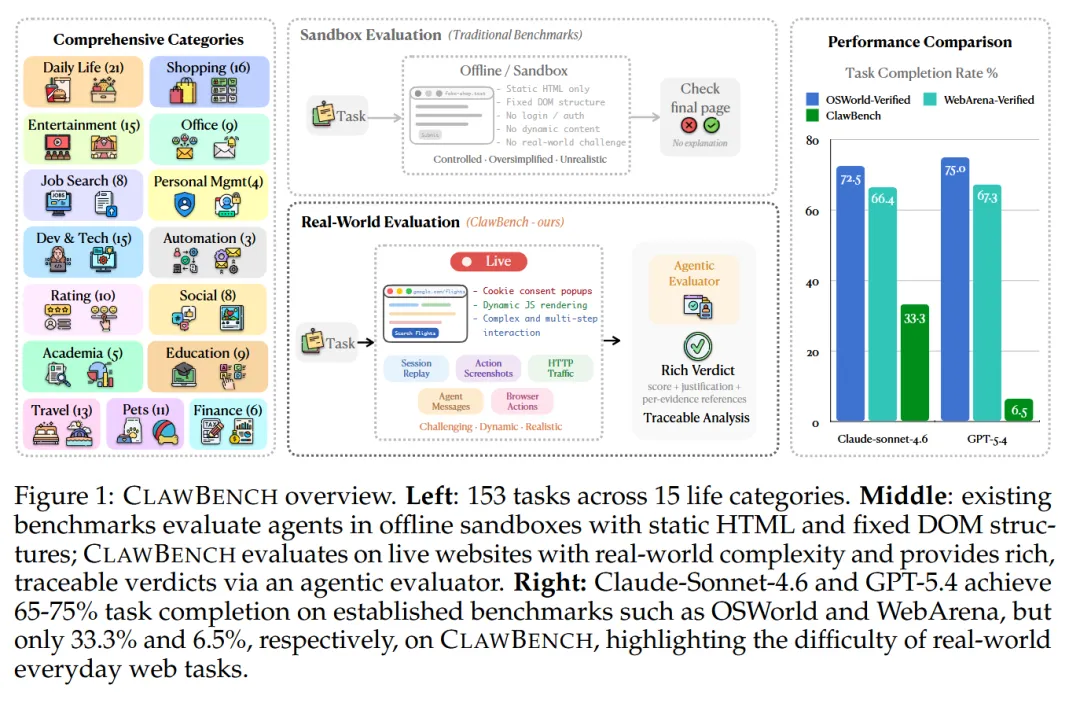
benchmark:ClawBench — 真实浏览器代理基准测试


随着 Claude Code、OpenClaw、Gemini CLI 等命令行与浏览器智能体的兴起,AI 不再只是“对话工具”,而是开始真正代替人类操作电脑、填写表单、完成任务。
但问题来了:OpenClaw 真的能像人一样,在日常网页中完成复杂任务,并从中持续进化吗?
两篇最新论文《SkillFlow》与《ClawBench》给出了目前为止最系统的回答。
✅ 优点:OpenClaw 已具备的能力
1. 真实的网页操作能力
-
在《ClawBench》中,OpenClaw 类智能体可以:
-
操作144个真实网站
-
完成购买、预约、填表、申请工作等写操作
-
处理动态内容、弹窗、登录流程
这比传统只能在静态页面中导航的智能体进了一大步。
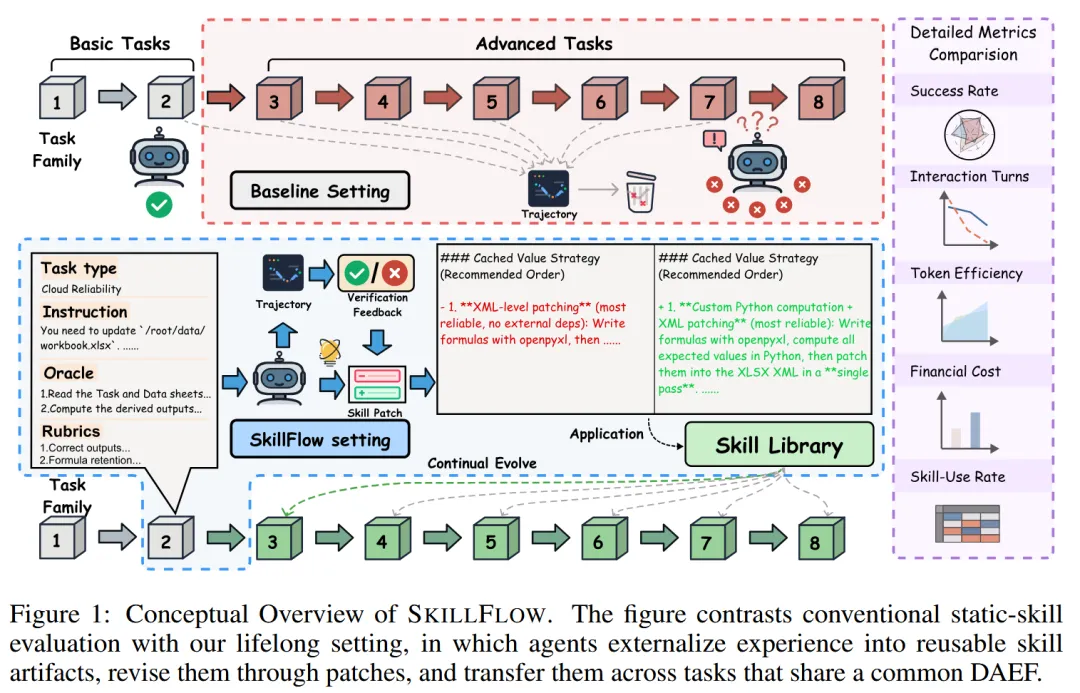
2. 支持技能发现与复用
-
在《SkillFlow》框架下,智能体可以:
-
从一次任务中总结出可复用的技能
-
将技能保存为
SKILL.md+ 脚本 -
在后续任务中调用、修正、丢弃技能
这意味着 OpenClaw 不再是“一次性执行器”,而是一个可进化的程序系统。
3. 与真实环境的可控交互
-
通过 Chrome 扩展 + CDP 拦截机制:
-
智能体可以访问真实网站
-
但最终提交请求被拦截(不真正下单、不提交申请)
-
保证安全性的同时不牺牲真实性
❌ 局限性:离“可靠助理”还有明显差距
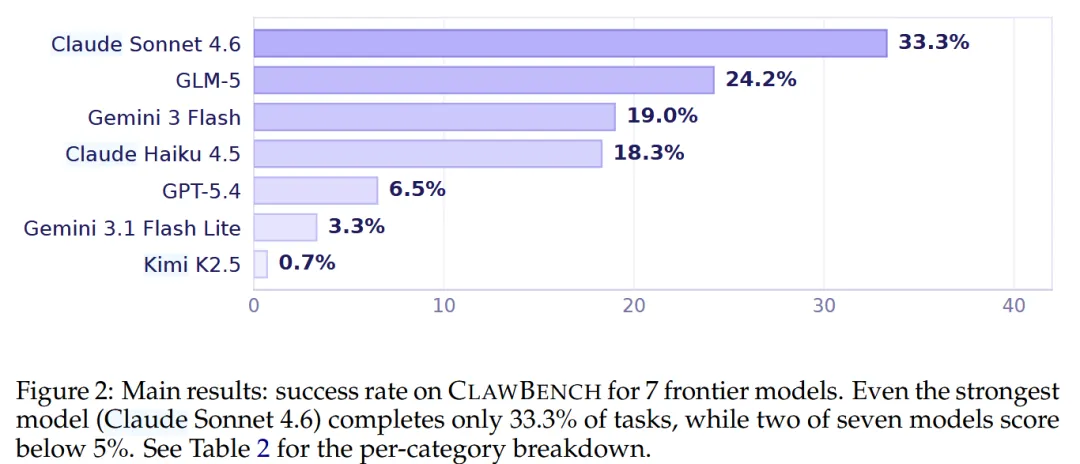
1. 真实任务成功率仍然很低
-
在《ClawBench》153个真实任务中:
-
最强模型 Claude Sonnet 4.6 仅完成 33.3%
-
GPT-5.4 仅 6.5%
-
两个模型甚至低于 5%
换句话说:70% 以上的日常网页任务,当前最强智能体也完成不了。
clawbench中的部分任务如下:
2. 技能进化不稳定,甚至倒退
-
在《SkillFlow》中:
-
Claude Opus 4.6 从 62.65% → 71.08%(✅ 正向进化)
-
Qwen-Coder 反而从 45.18% → 44.58%(❌ 退化)
技能不是越多越好,错误的技能会污染整个任务族。
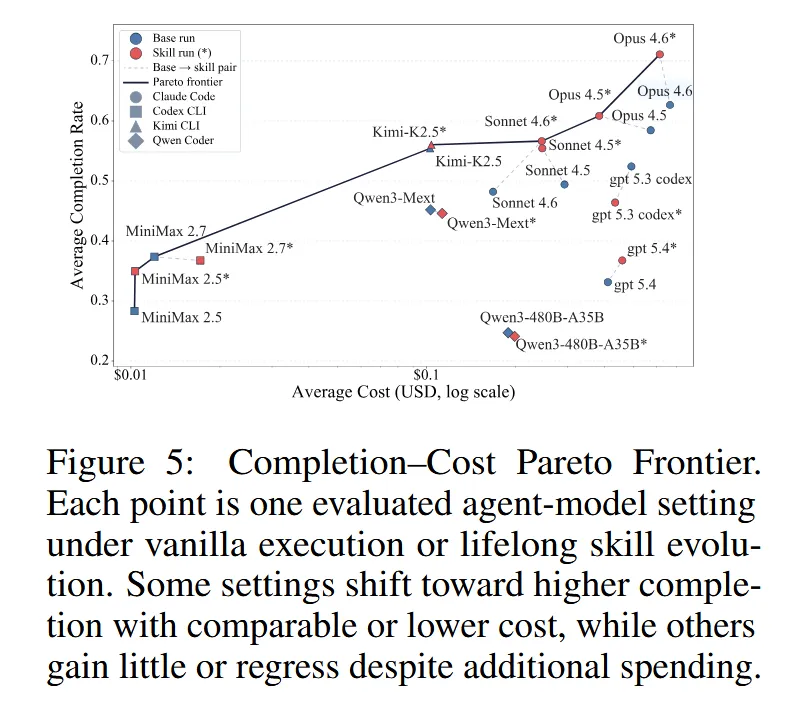
3. 技能膨胀,而非真正的抽象与压缩
-
弱模型(如 Qwen、MiniMax):
-
几乎为每个任务都生成一个“新技能”
-
最终技能库膨胀,但无正向收益
它们更擅长“记录经验”,而不是“提炼原则”。
4. 缺乏真正的任务间迁移能力
-
大多数模型:
-
在同一任务族内表现尚可
-
一旦跨任务族(如从财务 → 医疗),技能几乎无法迁移
说明当前技能更多是任务特定的“脚本片段”,而不是真正的可迁移知识。
🧠 核心结论:OpenClaw 的下一步是什么?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OpenClaw 已经走出了“能做”的第一步,但离“可靠、可进化、可迁移”的通用助理,还有很长的路。
📌 写在最后
这两篇论文(SkillFlow & ClawBench)是目前最系统地揭示 OpenClaw 类智能体真实能力边界的工作:
-
开发智能体工具链 → 必须关注技能膨胀与修复机制
-
评估智能体能力 → 不要只看静态 benchmark,要上真实网页 + 写操作
-
研究智能体进化 → 请记住:写出技能 ≠ 写出好技能
真正的智能体,不是会做事,而是能从做错的事中学会更好。