 夜雨聆风
夜雨聆风





中国信通院“方升”大模型(OpenClaw场景)最新测试结果发布
随着人工智能技术加速向现实世界场景渗透,以OpenClaw为代表的智能助手正从概念验证迈向规模化应用。智能助手通过将复杂操作指令转化为对本地或远程系统的直接操控,实现从“信息处理”到“任务执行”的能力跨越,成为重塑人机交互范式与产业数字化发展格局的关键动能。中国信息通信研究院(以下简称“中国信通院”)人工智能研究所高度关注智能助手技术及应用发展动态,研究推出了“方升”大模型(OpenClaw场景)基准测试体系。近期,中国信通院组织完成了最新“方升”大模型(OpenClaw场景)基准测试工作,最新测试体系及测试结果分析如下。
一
测试体系
“方升”大模型(OpenClaw场景)基准测试体系旨在全面、客观评价大模型支撑Claw类任务时的综合能力。该体系覆盖6类任务场景,基于成功率、效率、成本三个维度进行综合评分。其中,成功率用于衡量模型完成任务的能力,统计模型成功完成任务的百分比及各模型的任务平均得分;效率用于评估模型的执行性能,以完成全部任务所需的总耗时及平均执行时间为主要指标;成本用于衡量模型运行开销,以任务执行过程中的词元总消耗量作为统一计量标准。
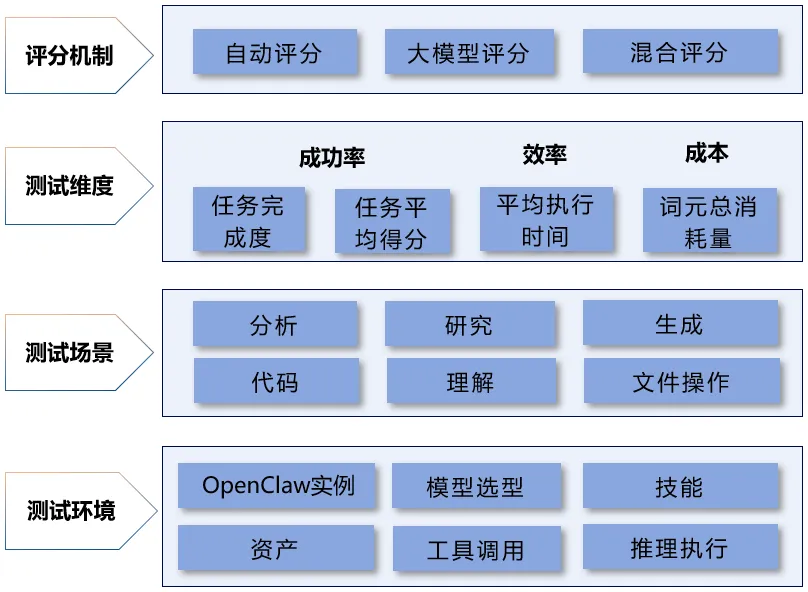
图1 “方升”大模型(OpenClaw场景)基准测试体系
二
测试数据和测试方法
本轮测试共测评了33个大模型,测试数据覆盖分析、研究、生成、代码、理解、文件操作6类任务场景,测试方法采用自动评分、大模型评分和混合评分三种模式进行评分。
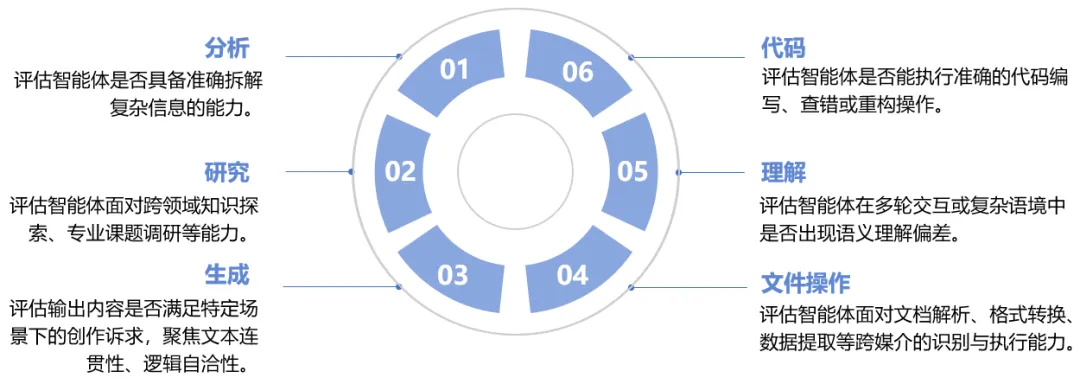
图2 “方升”大模型(OpenClaw场景)基准测试任务场景
三
测试分析及结论
本次评估从任务得分表现、任务完成效果、词元消耗以及执行时间等多个维度展开系统评估,综合分析不同大模型在OpenClaw场景下的能力差异与性能特征,为大模型在智能助手场景的选型优化与能力提升提供客观依据与决策参考。
(一)基准测试总体分析
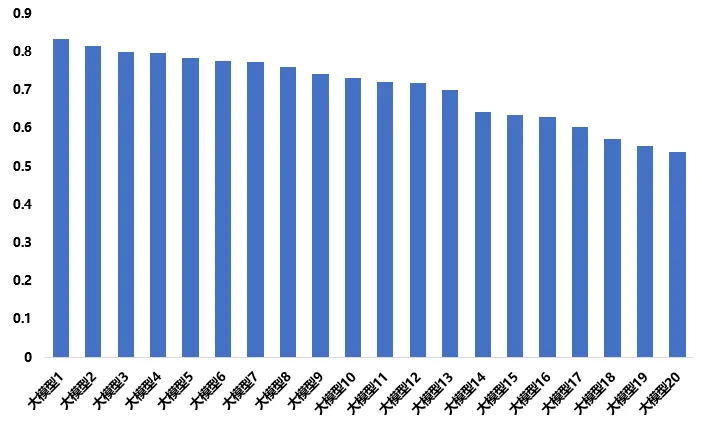
图3 “方升”大模型(OpenClaw场景)测试结果
从总体得分来看,一是大模型竞争较为激烈,模型之间呈现出较明显的能力分层,头部模型优势逐步显现。模型最高得分为0.83,超过0.8分以上的模型有3个,表明部分模型已具备较强的复杂任务执行与自主规划能力。模型最低得分为0.54,模型平均得分为0.71,表明模型在OpenClaw场景任务上的整体能力已达到中等偏上水平,但不同模型之间仍存在较大差距。二是模型版本迭代对能力提升影响显著,部分模型相较上一版本得分提升超过50%,表明当前大模型能力演进仍处于快速增长期。
从总体得分分布特征来看,测试结果整体呈现“头部集中、中部密集、尾部拉开”的分布特点。中后段模型得分下降明显,反映其在复杂任务规划、长链路执行及环境适应性方面仍存在短板。模型得分差异的根本原因与模型架构、训练策略、推理能力适配等有关。
(二)任务类型分析
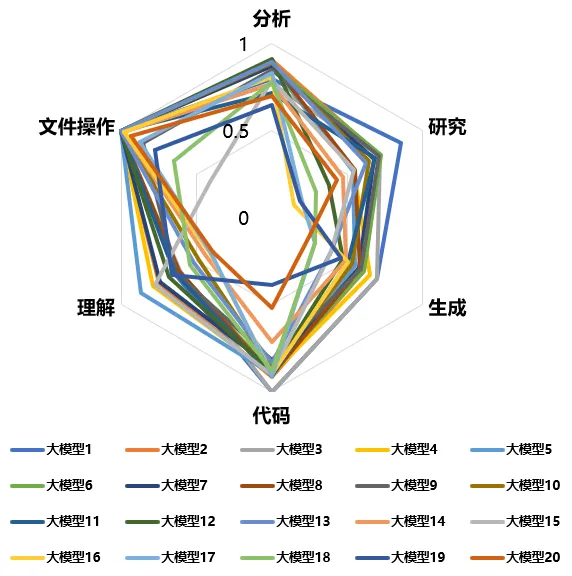
图4 “方升”大模型(OpenClaw场景)任务得分
从任务得分来看,一是在文件操作、代码任务上模型得分普遍较高,文件操作任务整体得分最高,平均得分达到0.92。代码任务同样保持较高水平,整体表现稳定。各模型在两类任务上的得分差异相对较小,表明当前大模型已具备较成熟的规则执行能力与标准化流程处理能力。二是在研究、生成及理解任务上表现较弱,生成任务平均得分为0.51,在所有任务类型中表现最弱,表明开放性任务仍是当前大模型能力提升的核心难点,存在较大优化空间。
从任务得分分布特征来看,各类任务之间呈现出明显的能力差异,模型在结构化任务与开放性任务中的表现分化明显。文件操作与代码任务因其结构化特征与明确规则,不仅易于执行,且验证过程简单直接,为模型的学习与优化提供了便利。研究、生成及理解任务缺乏固定规则,需要模型具备较强的语义理解、上下文关联、逻辑推理以及多步骤规划能力,导致模型难以实现全面且准确的处理。
(三)执行时间分析
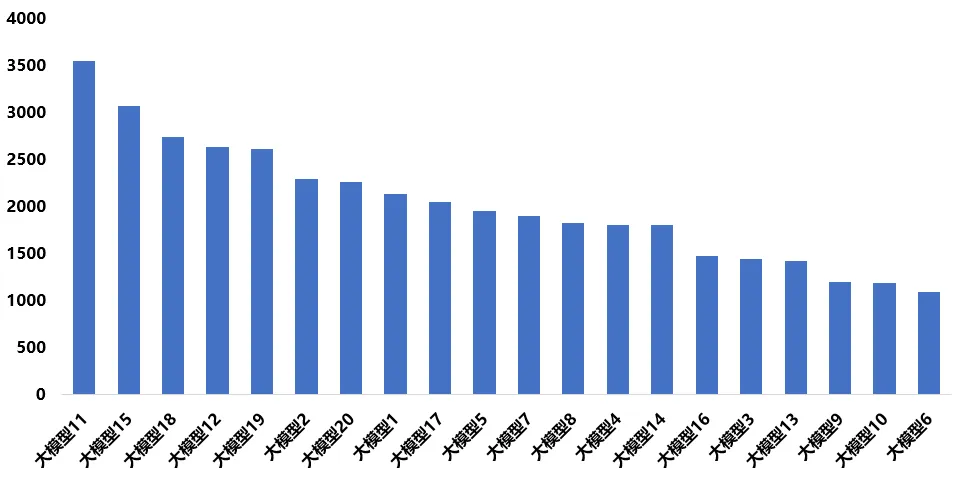
图5 “方升”大模型(OpenClaw场景)执行时间(单位:秒)
从执行时间结果来看,一是各模型的执行时间差异较大,最短执行时间为1086秒,最长执行时间为3552秒,大量模型聚集在1500到2500秒的区间内,这代表了当前行业在处理该类复杂场景时的普遍算力与推理效率基准线。二是执行时间并未与最终得分形成简单线性关系,部分高分模型虽然执行时间较长,但能够通过更充分的任务规划与推理过程提高任务完成质量;而部分低分模型虽然执行时间较短,却存在任务执行不完整、推理过程过于简化等问题。
执行时间差异的根本原因主要与以下因素有关:一是任务分解与规划能力,不同模型在复杂任务中的步骤拆解策略差异明显;二是探索与决策机制,高性能模型通常能够更快找到有效执行路径;三是资源调度与上下文管理能力,部分模型在长任务链执行过程中能够保持较高稳定性,而部分模型则容易出现上下文冗余与推理效率下降问题。
(四)词元总消耗量分析
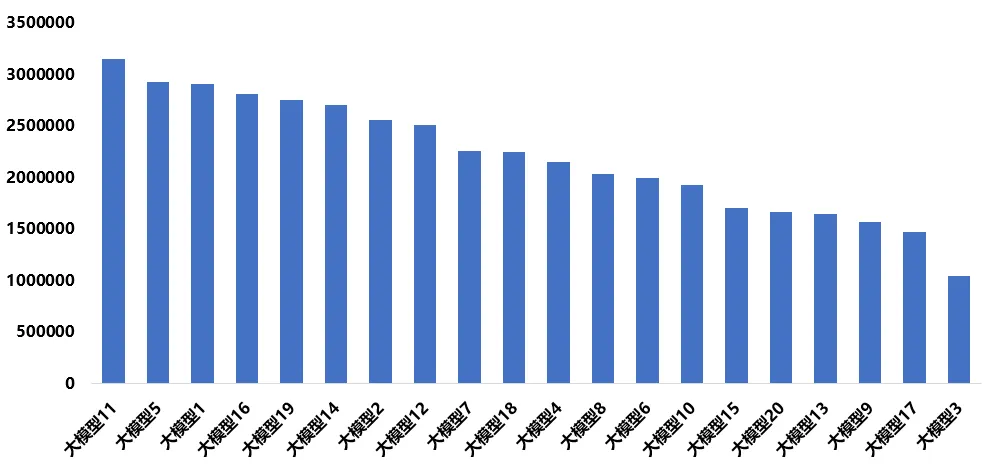
图6 “方升”大模型(OpenClaw场景)词元总消耗量
从词元总消耗量结果来看,一是模型在各任务下的词元消耗差异较大,最高词元总消耗量为3153368,最低词元总消耗量为1049117,词元消耗相差约3倍。高分模型的词元消耗普遍集中在200万至290万区间。二是技术路线分化,巨大的消耗量差异反映出当前大模型在解决复杂问题时采用了不同的策略。一部分模型倾向于通过长链路推理提升任务完成度,因此会消耗更多词元,而另一部分模型则通过压缩推理路径、优化上下文管理与强化任务决策效率,实现更高效的资源利用。另外,OpenClaw任务本身对于上下文窗口管理、记忆机制以及工具调用能力的适配程度有较高要求,这也会直接影响词元消耗水平。
下一步重点方向
中国信通院将持续推进“方升”大模型(OpenClaw场景)基准测试体系的研究与推广工作,一是持续构建数据集与测试场景建设,夯实评测基础;二是热忱欢迎产业界联合构建高质量、代表性的智能体评测数据集,提升基准的行业适配性;三是开放模型测试通道,欢迎相关企业提交模型参与基准测试,共建开放协同的评测生态。基准体系的建设离不开产学研各界的共同参与,诚挚邀请技术企业、科研机构、行业专家携手共建,推动智能体评测技术与产业应用健康发展。
联系人
张学强 15722924458
zhangxueqiang@caict.ac.cn
张嘉夫 13207520325
zhangjiafu@caict.ac.cn
王怡茹 18755879708
wangyiru@caict.ac.cn