 夜雨聆风
夜雨聆风





论文精读:OpenClaw-RLTrain Any Agent Simply by Talking
📌 论文基本信息
|
|
|
|---|---|
| 标题 |
|
| 作者 |
Mengdi Wang†, Ling Yang† |
| 机构 |
|
| arXiv |
|
| 发表时间 |
|
| 代码 |
|
| 关键词 |
On-Policy Distillation · Personal Agent · LLM Fine-tuning |
🧭 一句话总结
每次智能体交互产生的「下一状态信号」(用户回复、工具输出、GUI 变化)都是隐含的训练数据——OpenClaw-RL 是第一个把它们统一转化为在线强化学习信号的框架,让模型「边用边变强」。
🎯 核心问题与动机
被浪费的信号
现有 Agentic RL 系统存在一个根本性缺陷:每次智能体执行动作 后,环境都会返回一个下一状态信号 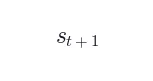 (用户回复、工具执行结果、GUI 状态变化、测试结果等),但现有系统仅将其作为「下一步的上下文」,完全忽略了它作为训练信号的价值。
(用户回复、工具执行结果、GUI 状态变化、测试结果等),但现有系统仅将其作为「下一步的上下文」,完全忽略了它作为训练信号的价值。
Waste 1 — 评估信号(Evaluative Signals)
下一状态信号隐式地对前一个动作打分:用户重新提问 = 不满意,测试通过 = 成功,错误 trace = 失败。这天然构成了「过程奖励」,无需额外标注流水线,却被现有系统完全忽略。
Waste 2 — 指令信号(Directive Signals)
下一状态信号往往还包含「如何改正」的方向性信息:用户说「你应该先检查文件再编辑」,不仅说明了响应是错的,还在 token 级别告诉了应该怎么改。现有 RLVR 方法只能处理标量奖励,无法利用这种方向性信息。
核心洞察
下一状态信号是通用的——个人对话、终端执行、GUI 交互、SWE 任务、工具调用,产生的都是同一种信号,同一个策略可以从所有这些信号中同时学习。
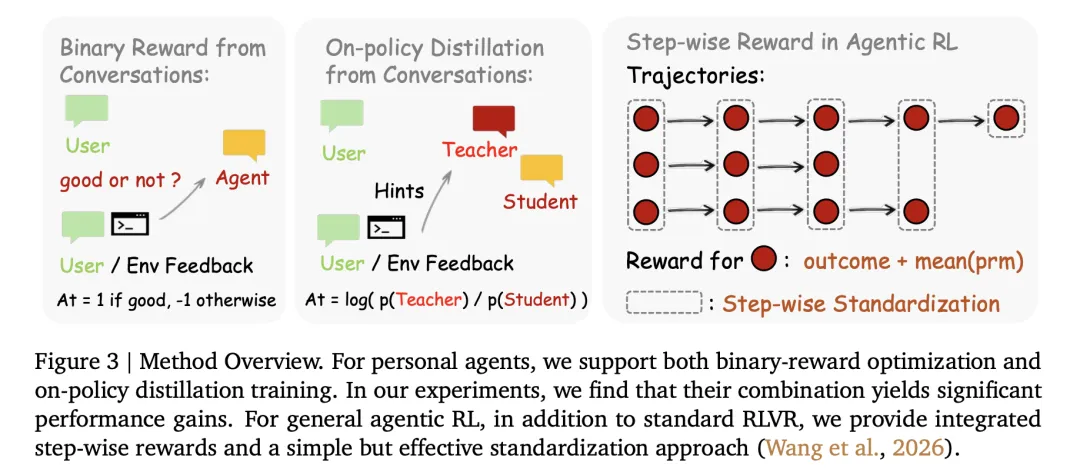
🏗️ 方法架构
四组件完全解耦异步流水线
OpenClaw-RL 基于 slime 框架,将系统拆分为四个完全独立的异步循环:
Policy Serving (SGLang) ↓ Environment (HTTP/API) ↓ PRM Judging (SGLang/API) ↓ Policy Training (Megatron)
各组件独立运行、互不阻塞:
- Policy Server(SGLang)
:服务线上用户请求,同时提供旧版 log-probs - Environment Server
:个人设备(私密 API)或云端服务(大规模并行) - PRM Server(SGLang/API)
:异步评判每个 interaction turn 的质量 - Training Engine(Megatron)
:持续更新策略权重,支持 Graceful Weight Update
关键设计:零协调开销,无需等待;支持在服务线上请求的同时持续训练。
两类智能体的统一处理
|
|
|
|
|
|---|---|---|---|
| Personal Agent |
|
|
|
| Terminal Agent |
|
|
|
| GUI Agent |
|
|
|
| SWE Agent |
|
|
|
| Tool-call Agent |
|
|
|
🔬 核心方法
方法一:Binary RL(处理评估信号)
核心思路:用 PRM Judge 将下一状态信号转化为标量过程奖励。
PRM Judge 构建:
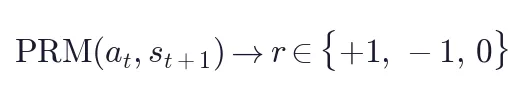
对动作 及其下一状态 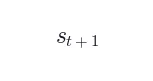 ,独立运行
,独立运行 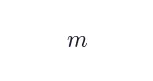 次 Judge,通过多数投票得到最终奖励:
次 Judge,通过多数投票得到最终奖励:

训练目标:标准 PPO-style clipped surrogate + 不对称边界:
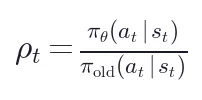
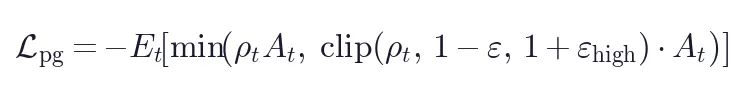
其中 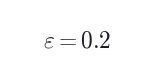 ,
,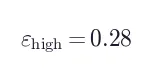 ,
,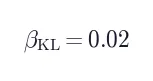 。
。
注意:实时对话场景下没有可用于标准化的 group structure(如 GRPO),因此直接用 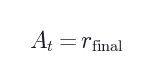 。
。
方法二:Hindsight-Guided On-Policy Distillation(OPD)
核心思路:将下一状态信号中的方向性信息转化为 token 级别的优势监督,提供比标量奖励更丰富的梯度信号。
Step 1 — Hindsight Hint 提取
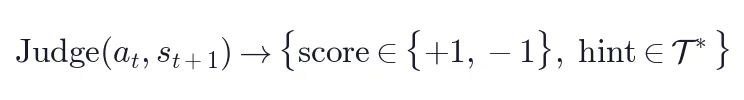
Judge 从 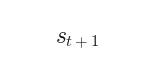 中提炼 1–3 句简洁可操作的指令性提示(hint),放入
中提炼 1–3 句简洁可操作的指令性提示(hint),放入 [HINT_START]...[HINT_END]。关键:不直接使用原始 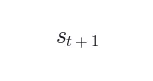 (往往冗余嘈杂),而是提炼核心指令内容。
(往往冗余嘈杂),而是提炼核心指令内容。
Step 2 — Hint 质量过滤
只选取 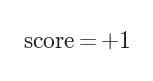 且 hint 长度 >10 字符的样本,取最长 hint。若无有效 hint 则丢弃该样本。OPD 宁可少样本,也要保证每个样本都携带清晰的纠错方向。
且 hint 长度 >10 字符的样本,取最长 hint。若无有效 hint 则丢弃该样本。OPD 宁可少样本,也要保证每个样本都携带清晰的纠错方向。
Step 3 — 增强 Teacher Context 构建
将 hint 附加到最后一条用户消息之后:
s_enhanced = s_t ⊕ “[user’s hint / instruction] {hint}”
模拟「如果用户一开始就提供了纠正建议,模型应该如何响应」的场景。
Step 4 — Token 级优势计算
在  下以原始响应 作为强制输入,计算每个 token 的 log-prob,得到 token 级优势:
下以原始响应 作为强制输入,计算每个 token 的 log-prob,得到 token 级优势:

-
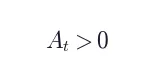
:teacher(知道 hint)认为该 token 更可能 → student 应该上调概率 -
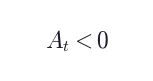
:teacher 认为该 token 不合适 → student 应该下调概率
与现有方法的本质区别:
-
vs RLHF/DPO:使用标量或偏好对,无法提供方向性信息 -
vs 标准蒸馏:需要独立的更强 teacher 模型 - OPD:同一个模型既是 teacher 又是 student,仅上下文不同,无需额外模型
方法三:Binary RL + OPD 联合(Combined)
两种方法互补,不竞争:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
联合优势:
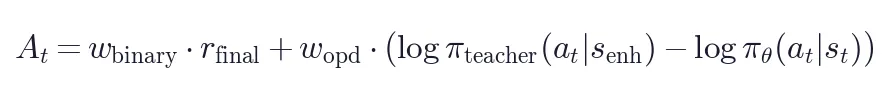
其中 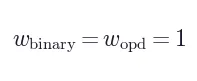 (默认值)。
(默认值)。
方法四:Stepwise Reward for General Agentic RL
对于长 horizon 的通用智能体任务,纯粹的 outcome reward 只在终止步提供梯度,绝大多数中间步骤得不到监督。
解决方案:将 outcome reward 与 PRM step reward 相加:
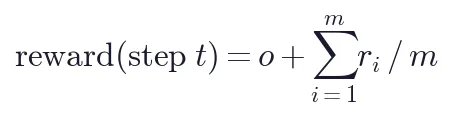
Stepwise Standardization:直接按 step index 对动作分组做标准化(terminal 等环境中状态不易聚类),经验上有效。
🧪 实验设计与结果
Personal Agent Track:学习对话信号
实验设置:用 LLM 模拟两种用户场景:
- Student
:用 OpenClaw 完成 GSM8K 数学作业,不想被发现用 AI(要求去掉 AI 腔调) - Teacher
:用 OpenClaw 批改作业,想要具体、友好的评语
基础模型:Qwen3-4B;学习率 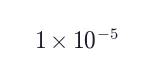 ;KL 系数 0;每 16 个样本触发一次训练。
;KL 系数 0;每 16 个样本触发一次训练。
关键结论 [Q1]:各方法得分对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
0.72 |
| Combined | 0.76 | 0.81 |
-
Combined 方法效果最强 -
OPD 前期慢(样本稀疏),但后期爆发 -
Binary RL 单独效果有限,但作为 OPD 的补充很关键
关键结论 [Q2]:个性化速度惊人
-
Student 场景:仅需 36 次问题求解交互,模型就学会避免 AI 腔调,转向自然口语风格 -
Teacher 场景:仅需 24 次批改交互,评语变得更具体且友好
General Agent Track:跨场景统一 RL
实验模型与规模:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
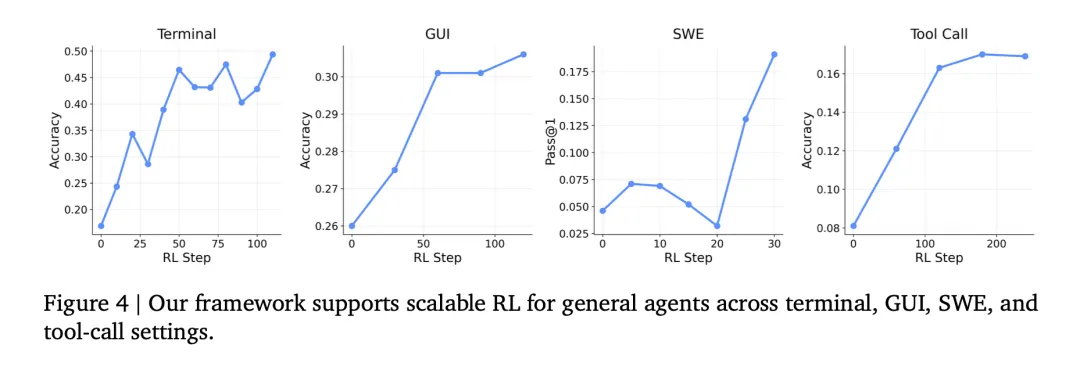
关键结论 [Q3]:框架在四种真实 agentic 场景下均有效,验证了统一框架的通用性。
关键结论 [Q4]:整合 outcome + process rewards 显著优于纯 outcome reward:
|
|
|
|
|---|---|---|
|
|
0.30 (+76%) |
|
|
|
0.33 (+6%) |
|
💡 创新点总结
① 识别了「下一状态信号」的普遍性
首次将个人对话、终端、GUI、SWE、工具调用统一为同一训练信号来源,构建通用框架。
② OPD(Hindsight-Guided On-Policy Distillation)
一种全新的自蒸馏方式——同一模型在 hint 增强上下文下产生 token 级优势,无需额外 teacher 模型,无需配对偏好数据。
③ 完全解耦的异步架构
serving、rollout、PRM judging、training 四个独立循环,对个人设备无侵入,对大规模训练消除 long-tail 阻塞。
④ Session-aware 个人智能体优化
将主线 turn 和辅助 turn 区分,精准识别可训练样本,支持持续个性化。
🔍 深度批判性分析
优势
- 信号无处不在
:无需专门的标注流水线,只要智能体在跑,信号就在产生 - OPD 的优雅性
:用同一模型在不同上下文下的 log-prob 差构建 token 级梯度,既不需要外部 teacher 又比标量奖励丰富得多 - 工程设计务实
:异步解耦架构解决了在线 RL 最棘手的延迟和阻塞问题 - 个人智能体的商业价值
:让模型在日常使用中自然个性化,门槛极低
局限与挑战
- PRM Judge 质量依赖
:整个框架的效果高度依赖 Judge 的准确性,而 Judge 本身可能出错(特别是在模糊的用户反馈场景下) - OPD 样本稀疏
:只有携带清晰 hint 的 turn 才能进入 OPD 训练,导致前期学习缓慢 - 个人智能体实验为模拟
:Personal Agent 实验使用 LLM 模拟用户,真实用户的反馈模式可能更加多样和嘈杂 - 联合损失超参数
:  和
和 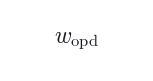 默认均设为 1,不同场景下最优比例可能不同,缺乏自动调节机制
默认均设为 1,不同场景下最优比例可能不同,缺乏自动调节机制 - Graceful Weight Update 细节
:论文提到了 zero-interruption 权重更新,但技术细节未充分展开
与相关工作的对比定位
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
(Hübotter 2026) |
|
|
|
|
|
|
|
|
| OpenClaw-RL | 实时交互下一状态 | 全在线异步 | 标量+Token 级 |
📊 关键超参数
|
|
|
|---|---|
|
|
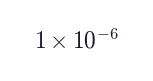 |
|
|
|
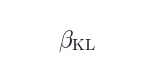 |
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
🗺️ 对后续研究的启发
- 自适应 OPD 权重
:根据 hint 质量动态调整 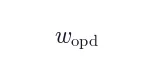 ,而非固定为 1
,而非固定为 1 - 跨用户泛化
:从单一用户个性化扩展到用户群体聚类,实现更高效的个性化 - PRM 自我演化
:随着策略更新,PRM Judge 是否也需要联合优化? - 更长 horizon 的信号传播
:当前只用当前 turn 的下一状态,如何利用更长序列的回溯信号? - 多模态扩展
:GUI 场景中视觉状态差异作为下一状态信号的充分利用
📝 个人总结
OpenClaw-RL 提出了一个非常有价值的视角转换:把每次智能体交互本身视为训练数据的来源,而不是只依赖精心收集的静态数据集。核心贡献在于把这一洞察工程化——既要有能处理多种信号类型的统一架构(异步四组件),又要有把方向性信号转化为 token 级梯度的方法(OPD)。
OPD 是本文最有原创性的技术贡献:它巧妙地绕过了「需要更强 teacher」的困境,用同一模型在 hint 增强上下文下自我对照,实现了比标量奖励丰富得多的梯度信号。这个想法与 STaR、Self-Rewarding LMs 一脉相承,但在在线 agentic 设置下的实现更加优雅。
个人智能体在数十次交互内就能显著个性化的结果令人印象深刻,如果在真实用户数据上也能复现,将是 AI 个人助理领域的重要进展。
解读时间:2026-05-09 | 解读人:AI (Claude)