 夜雨聆风
夜雨聆风





AI Coding For Real Engineers:软件工程基本功如何让AI编程事半功倍
在如今的开发圈,“AI编程”早已不是新鲜词汇。许多开发者每天都在与AI结对编写代码,但现实往往是,我们时常被AI的“幻觉”和错误气得抓狂。AI编程究竟只是一种依赖运气的“氛围编程(Vib Coding)”,还是可以被纳入严谨的软件工程体系,成为可控制、可预测且高质量的工程流程?
在《跨国串门儿计划》第510期播客中,知名TypeScript专家、在线教育平台AI Hero的创始人Matt Pocock,通过一场深度工作坊给出了他的答案。Matt的核心观点振聋发聩,我们往往认为AI是一个新范式,但却忽略了软件工程的基本功。那些在人类协作中至关重要的基本功,在与AI协作时同样效果拔群。糟糕的代码库只会造出糟糕的智能体,而优秀的架构才能让AI发挥真正的威力。
本文将深入拆解Matt Pocock这套从“规划”到“生产”的完整AI编程工作流,为你揭示如何真正驾驭AI,而不是被AI驾驭。
一、 理解大语言模型(LLM)的“阿喀琉斯之踵”
要高效使用AI,首先必须理解其能力边界与底层约束。Matt指出了大语言模型在编程场景下的两大核心痛点。
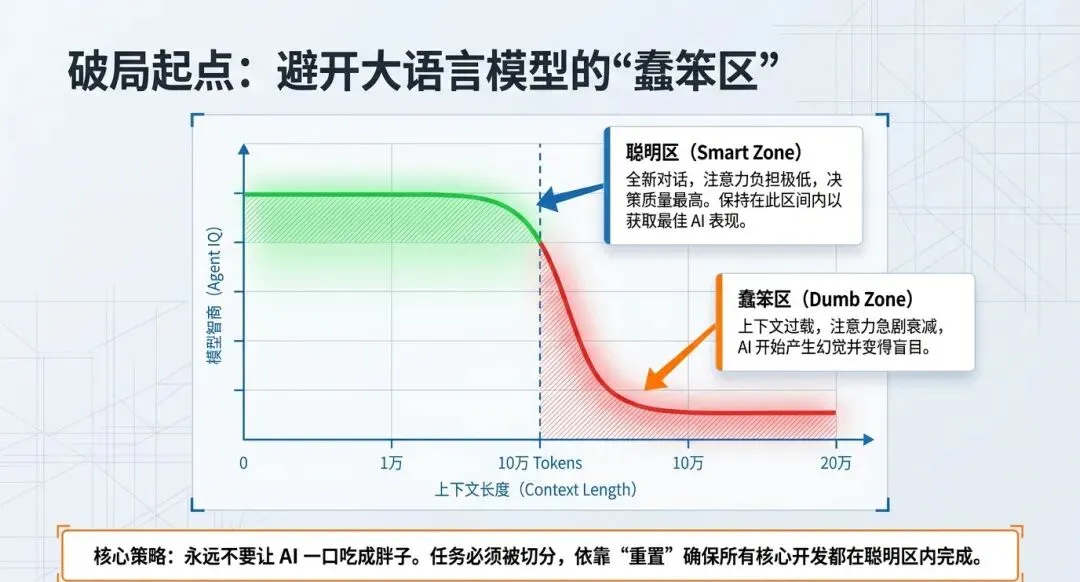
1. “聪明区”与“蠢笨区”(注意力衰减)
大语言模型存在一个“聪明区(Smart Zone)”和“蠢笨区(Dumb Zone)”。当你开启一个全新的对话窗口时,由于注意力机制的负担最轻,这恰恰是模型表现最聪明、最好的时刻。然而,随着上下文(Token)的不断堆积,尤其是在进度条达到40%(或大约10万Token)左右时,模型的性能会急剧下降,开始做出愚蠢的决策,一脚踩进“蠢笨区”。
应对策略:多阶段计划。 不能让AI“一口吃成个胖子”。必须将庞大的任务拆解成小块,确保每一小块工作都能在模型的“聪明区”内完成。
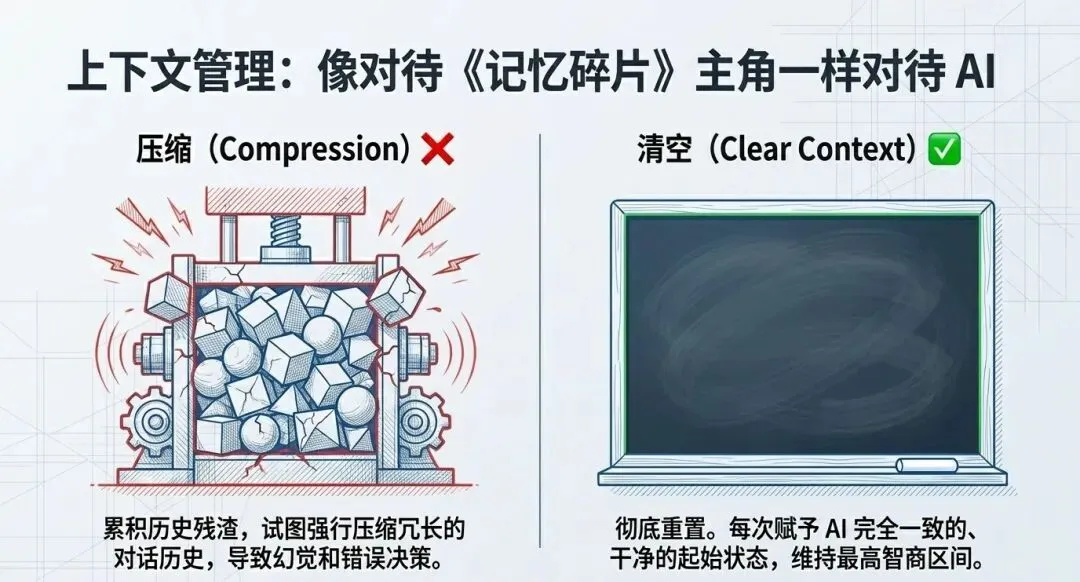
2. “记忆碎片”效应与上下文管理
大语言模型就像电影《记忆碎片》(Memento)里的主角,它们会持续遗忘并重置回初始状态。在处理过长的上下文时,开发者通常面临两种选择,是让AI“压缩(总结)”历史对话,还是直接“清空”上下文重新开始?
Matt极度反感“压缩”历史的做法,因为压缩会累积大量的“残留物”和冗余信息。相反,他更倾向于彻底清空上下文,让AI不断回到干净的初始状态。围绕这一特性进行优化,是保持AI高效输出的关键。
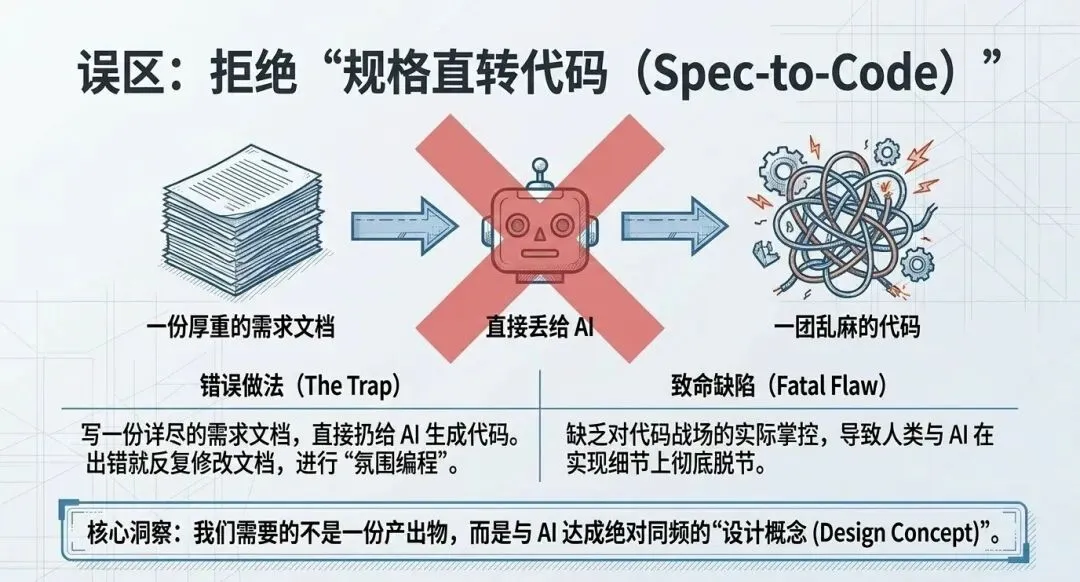
二、 规划与对齐,拒绝“规格直转代码”,用“追问”建立共识
在获取了一个初步的想法或客户需求(例如,为平台增加游戏化积分功能)后,许多开发者的本能反应是直接进入计划模式,或者奉行“规格直接转代码(Spec-to-Code)”的运动,即写一份需求文档扔给AI,生出错的代码就去改文档,完全不看代码。
Matt严厉批判了这种做法,认为这本质上是另一种糟糕的“氛围编程”。代码才是真正的战场,你必须驾驭并塑造型代码。
独创的“追问我(Grill Me)”技巧
为了避免需求对齐的失衡,Matt独创了“Grill me”技能。当你把模糊的需求给到AI时,不是让它立刻产出计划,是强迫AI不断向你提出尖锐的设计与逻辑问题,直到双方达成共同理解。
-
• 隔离上下文: 通过调用“子代理(Sub-agent)”,让子代理在隔离的窗口中消耗Token去探索代码库,从而降低主对话窗口的上下文压力。 -
• -
• 达成“设计概念”: 这个盘问过程(可能长达40到100个问题)的核心目的,是建立软件工程大师Fred Brooks所说的“共享的设计概念(Design Concept)”。 -
• -
• 团队协作放大器: 这些问题不应只由单一开发者回答,遇到盲区时,完全可以拉上产品经理或领域专家,像“结对编程”一样共同向AI提供输入。 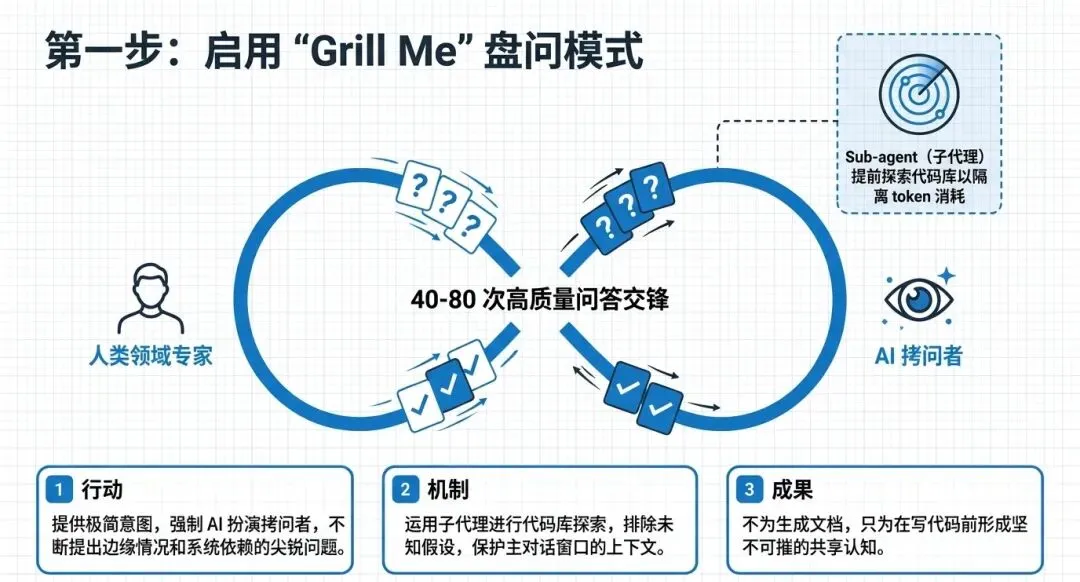
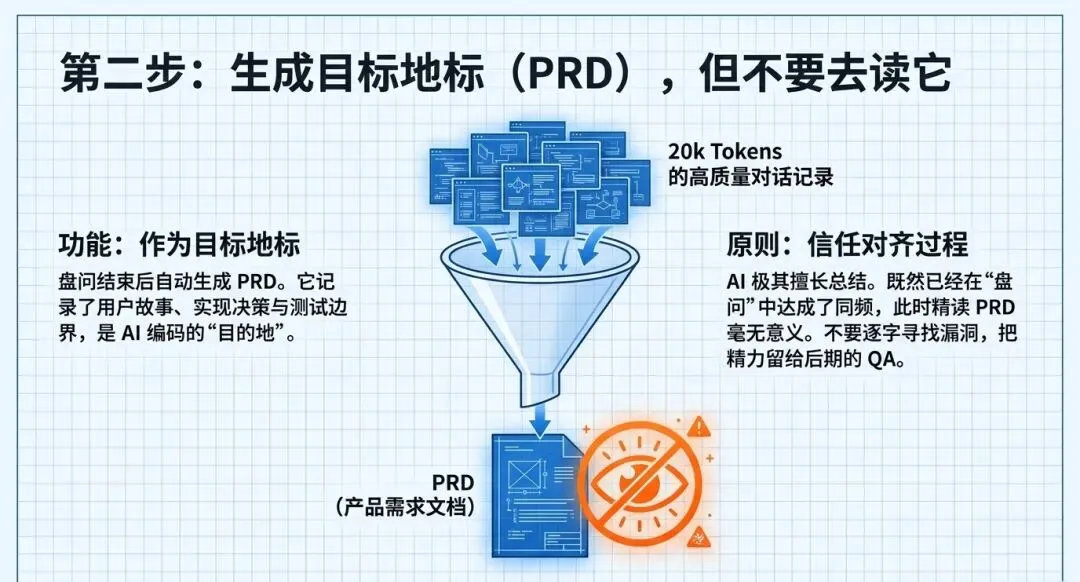
PRD的生成与“不读”哲学
盘问结束后,你需要一份产品需求文档(PRD)来记录这个“目的地”。Matt的工作流会自动生成包含用户故事、实现决策和模块划分的PRD,并将其存为本地的Issue文件。
但有趣的是,Matt强烈建议不要去逐字阅读这份PRD。因为在深度盘问阶段,人与AI已经达成了思维同步;此时去读PRD,只是在测试LLM的“总结能力”。更关键的是,我们要把精力留在后续的质量保证(QA)上。
三、 任务拆分,看板、垂直切片与“曳光弹”开发
一份模糊的PRD无法直接喂给AI,必须将其转化为结构化的任务。
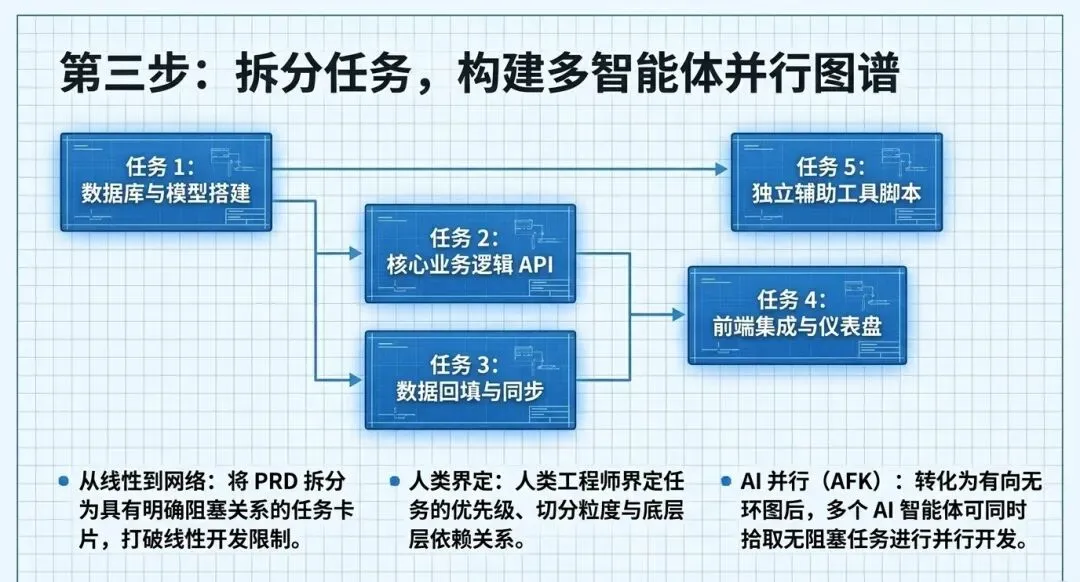
1. 看板方法(Kanban)与任务依赖图
将PRD拆解成带有阻塞关系的独立任务卡片(例如,任务二依赖任务一)。这种将计划变成“有向无环图”的方式,使得多智能体(Agents)并行开发成为可能。你可以让不同的AI智能体同时拾取互不阻塞的任务,极大提升效率。
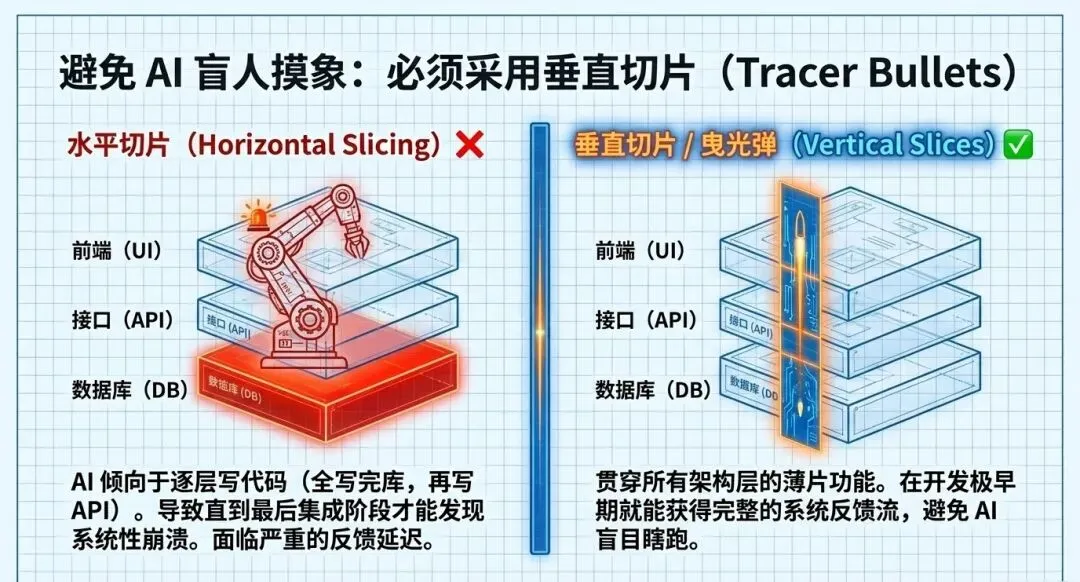
2. 避免AI的“水平编码”,采用“垂直切片”
这是整个工作流中最具启发性的工程思想之一。
AI有一种天然的倾向,喜欢“水平编码”,先写完所有的数据库模式,再去写API层,最后写前端。这种做法是致命的,因为直到最后一步完成前,你都无法获得完整的反馈回路,AI等同于在“盲写”。
解决方案是借用《程序员修炼之道》中的“曳光弹(Tracer Bullets)”概念,即垂直切片。每一个分发给AI的任务切片,都必须横跨数据库、服务层到前端的最简形态。这样在开发早期就能获得端到端的反馈,验证系统各层是否能协同工作。
四、 实现阶段,自动智能体(Night Shift)与TDD
在完成了繁重的人工规划与对齐(“白班”工作)后,就进入了AI火力全开自动实现的“夜班”阶段。
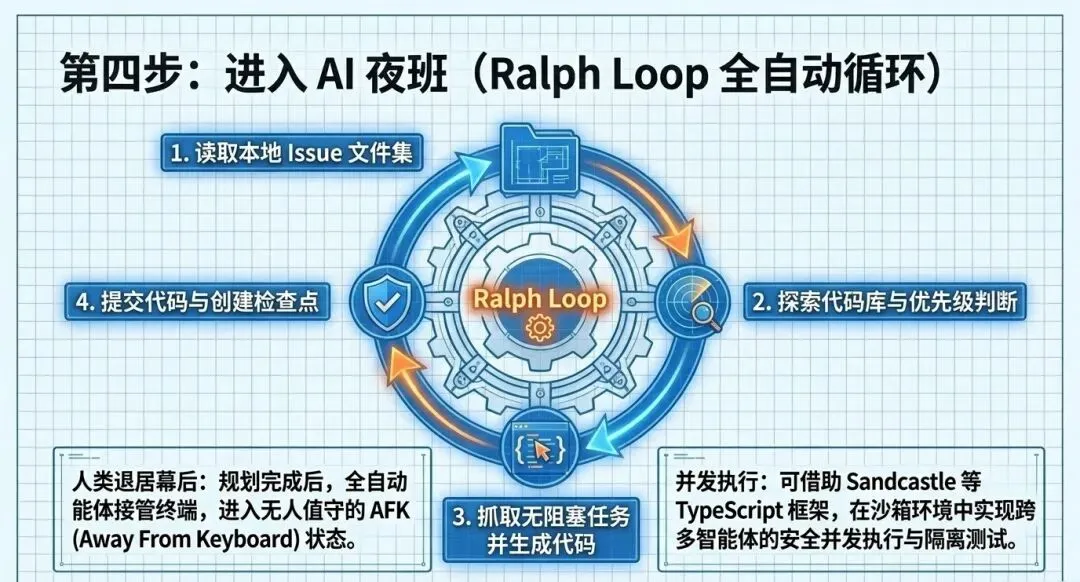
1. Ralph全自动智能体循环
Matt展示了一个名为“Ralph循环”的自动化脚本。它会读取本地的Markdown任务文件,通过循环脚本自动探索代码库,并以执行者的身份去逐个实现任务。
2. 测试驱动开发(TDD),AI编程的生命线
TDD(红-绿-重构)是榨取AI最大价值的绝对关键。
-
• 原理: 先让AI写一个注定会失败的测试(红),再去写实现代码让测试通过(绿),最后优化(重构)。 -
• 反馈回路: 如果没有测试反馈,AI完全就是在“瞎写”。反之,反馈循环的质量直接决定了AI代码产出的天花板。通过强制AI使用TDD,不仅避免了AI为了图省事而在写完实现后“作弊”补测试,还能显著提升代码库的测试覆盖率和系统鲁棒性。 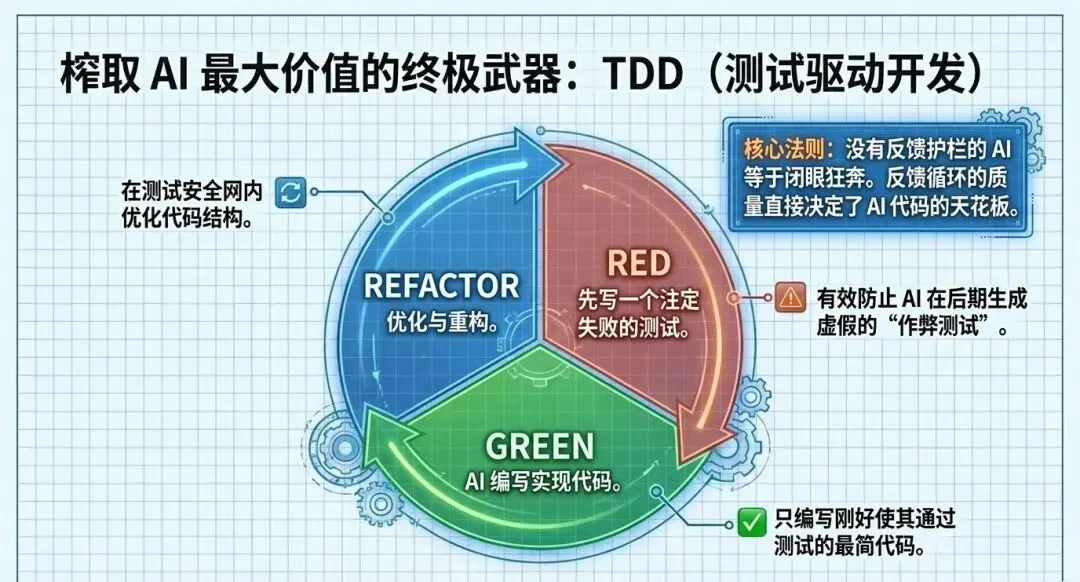
五、 质量审查与架构优化,重塑代码库形态
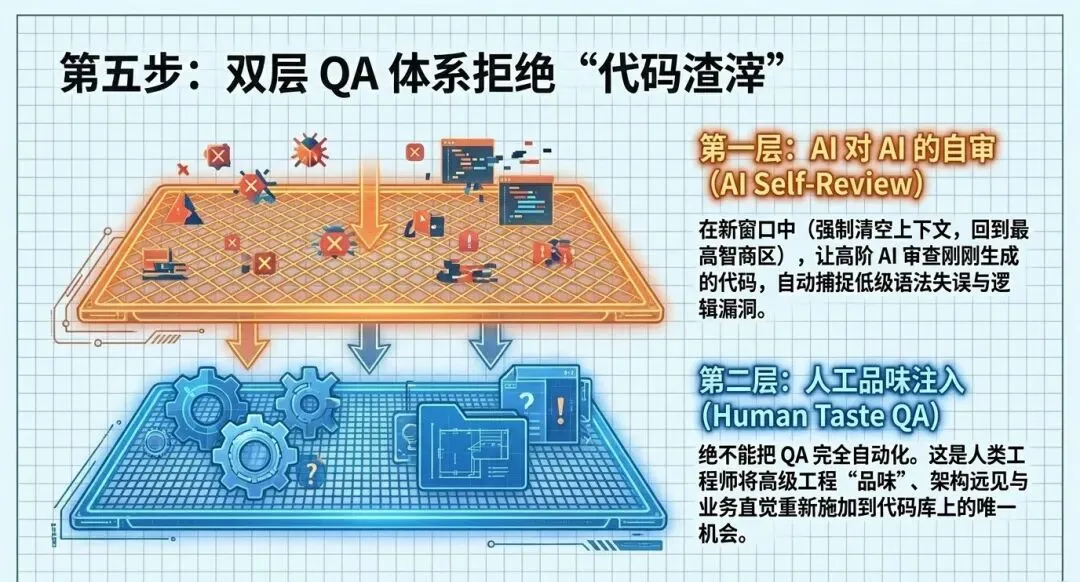
当AI完成了实现,人类必须重新介入循环。试图将QA(质量保证)也完全自动化是极其危险的,那只会产出一堆缺乏品味的“代码渣滓”。人类的职责是将“品味”重新注入代码库。
面对AI产出的大量代码,如何进行有效审查和架构管理?
1. 让AI先自审(AI对AI的QA)
在人工QA之前,可以先让AI自审代码。关键技巧是,清空之前的上下文。因为实现阶段AI可能已经烧掉了大量Token,进入了“蠢笨区”;通过清空上下文,利用更聪明的模型(如Claude Opus),AI可以在全新的“聪明区”里找出许多意想不到的Bug。
2. 深模块(Deep Modules) vs 浅模块(Shallow Modules)
参考John Ousterhout在《软件设计的哲学》中的理论,代码库的架构直接决定了AI的智商。
-
• 浅模块: 将代码拆碎成无数相互依赖的小文件,这会让AI迷失在依赖关系网中,并且极难确定测试边界。 -
• 深模块: 对外只暴露极小且简单的接口,内部封装大量逻辑。好的代码库让AI更聪明。深模块使得包裹测试边界变得极为容易,反馈循环更快,AI在其中的表现也呈指数级提升。 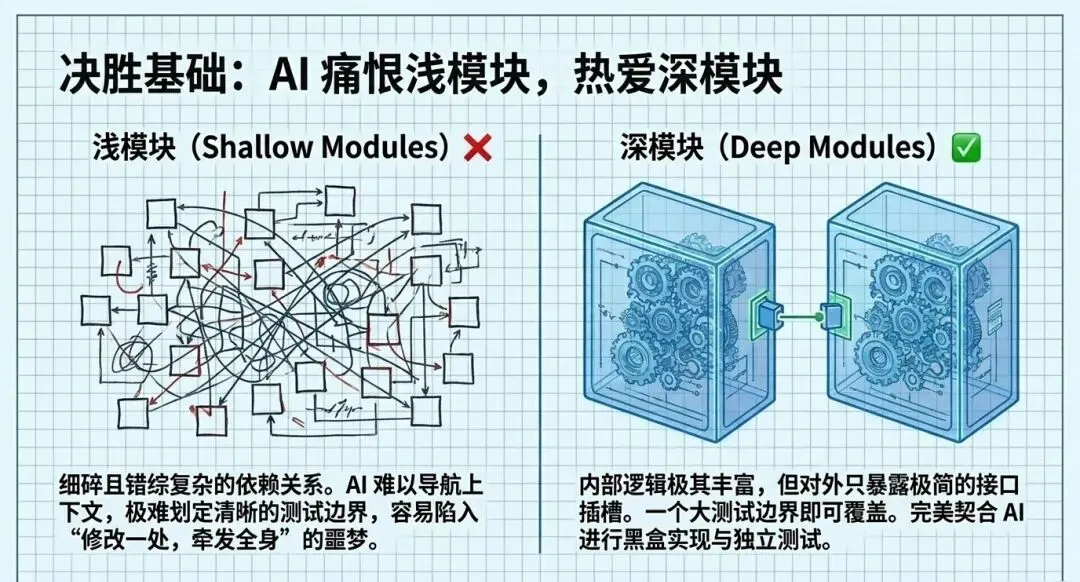
-
• 作为人类架构师,你的核心工作是设计这些深模块的接口轮廓,并将内部细节的实现委托给AI,从而在保持对全局架构感知的掌控时,不被代码细节逼疯。 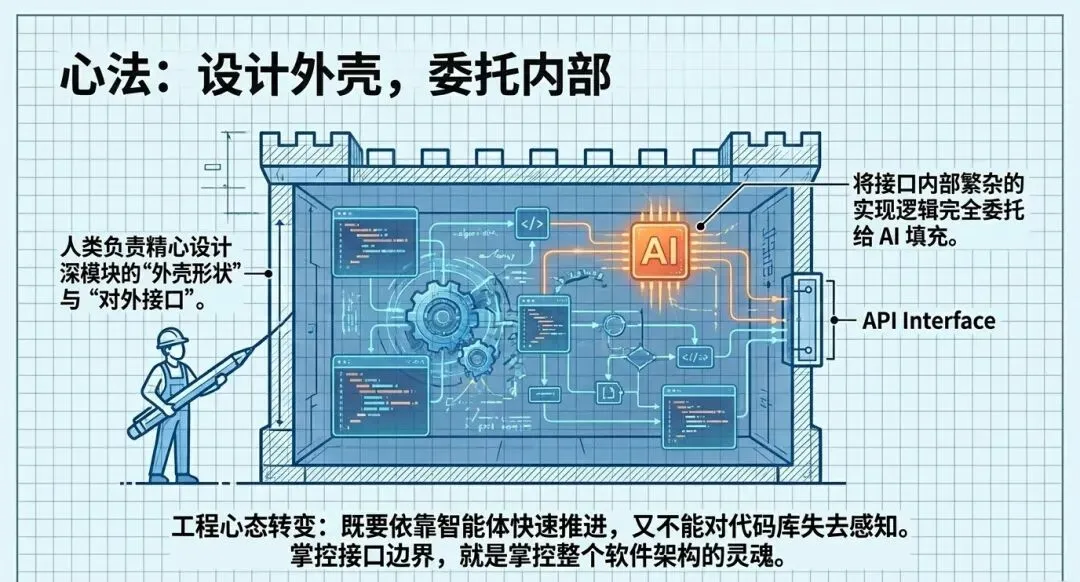
3. 文档腐烂与编码规范推送
-
• 清理文档: 一旦任务完成,那些曾经的PRD和计划文档应该被直接丢弃或关闭(如关闭GitHub Issue)。如果把它们留在代码库中,随着系统的演进,它们会变成“腐烂的文档”,反而会误导AI。 -
• 规范推送与拉取: 想要AI遵循特定的编码规范,对于“实现者(Implementer)”,允许它们去库中“拉取(Pull)”规范;而对于“审查者(Reviewer)”,则需要在系统提示词中强制“推送(Push)”这些规范,确保它们以此为标准进行校验。 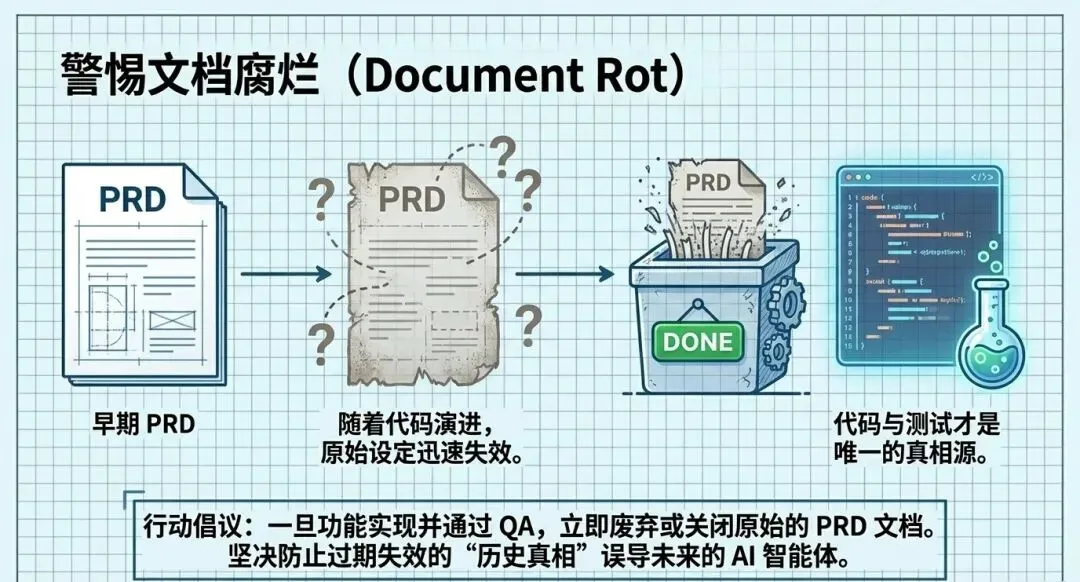
结语,重读经典,在AI时代夯实基石
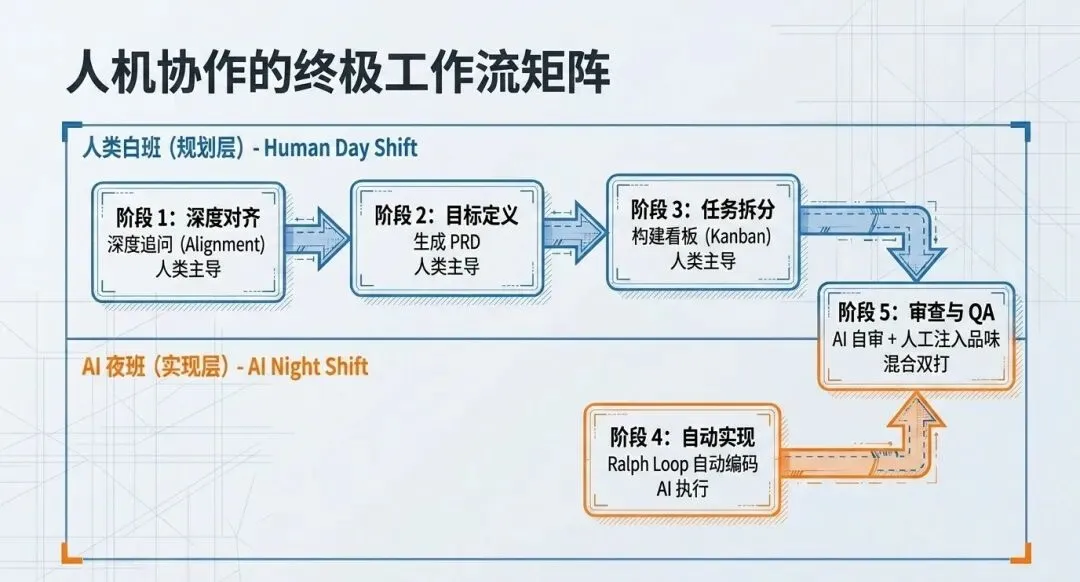
回顾Matt Pocock的完整工作流,想法 → 深度对齐(Grill Me) → 目标PRD → 看板与垂直切片 → AI全自动实现(TDD) → 人类QA与代码审查。这套流程完美地将AI的极致效率与人类的工程品味结合在了一起。

有趣的是,尽管我们在探讨最前沿的AI编程工具,但贯穿始终的核心武器,敏捷开发、看板、垂直切片(曳光弹)、测试驱动开发(TDD)、模块化设计(深模块),无一不是沉淀了数十年的软件工程经典智慧。
正如Matt在分享最后给出的核心建议,如果你想在这个时代写出完美的AI提示词来指导智能体,去读一读经典的软件工程书籍吧,它们是一座未被充分挖掘的纯金矿。在AI这个强大的”放大器”面前,坚实的软件工程基本功,才是决定你最终能走多远的基石。

【从第 0 分钟,走向第 1 分钟】
所有的文字导览,终究只是路标,而非风景本身。如果刚才的某个片段击中了你,或许是因为它承载了这里无法完全复刻的思考密度与情感颗粒。
我们已为你完成了”打捞”与”指路”,现在,请把时间交还给原作者。
《#510.AI Coding For Real Engineers:软件工程基本功如何让AI编程事半功倍》,收录于《跨国串门儿计划》,预计 84 分钟
点击阅读原文去收听原片,去感受声音的起伏,那里有更完整的灵魂,和更深切的共鸣。