 夜雨聆风
夜雨聆风





WordStylist: Styled Verbatim Handwritten TextGeneration with Latent Diffusion Models
WordStylist: Styled Verbatim Handwritten TextGeneration with Latent Diffusion Models
论文链接https://openaccess.thecvf.com/content/CVPR2023/html/WangWordStylist_for_FewShot_Font_Generation_CVPR_2023_paper
本文摘要
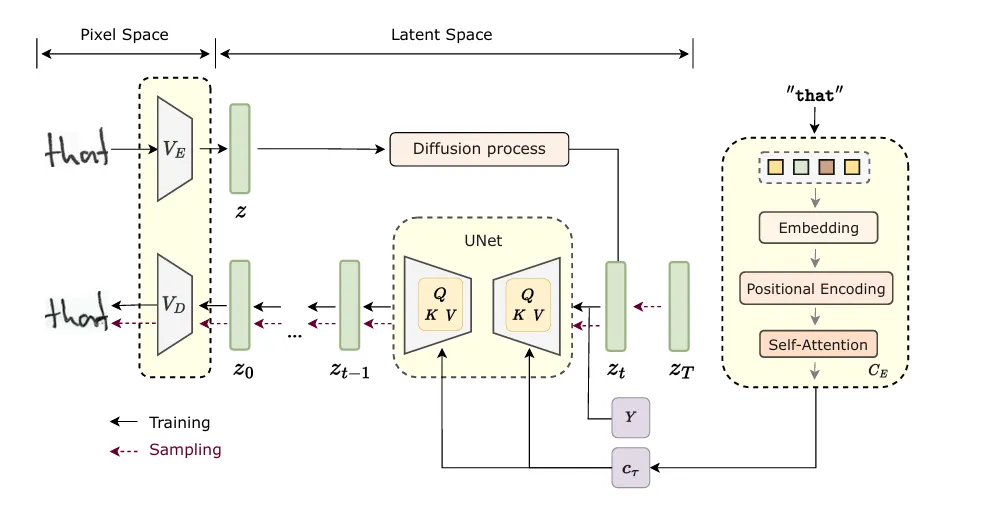
WordStylist 是基于潜在扩散模型(LDM)构建的词级风格化手写文字生成系统,整体架构围绕 “VAE 压缩 — 扩散加噪 —U-Net 去噪 — 条件控制 —VAE 解码” 这一完整链路搭建,核心组件包含预训练变分自编码器(VAE)、扩散过程模块、噪声预测 U-Net、文本内容编码器、风格嵌入层、解码器六大部分。模型以真实手写词图像、词文本序列、书写风格类别标签为输入,完全摆脱传统 GAN 生成手写体依赖对抗训练、风格判别器、OCR 识别网络的复杂范式,转而利用 LDM 在低维潜在空间对数据分布进行建模,显著降低训练算力需求、减少模型参数量并提升生成稳定性。输入的手写词图像先送入预训练 Stable Diffusion VAE 编码器,将高分辨率像素空间压缩至低维潜在空间,得到紧凑的潜在表示;随后进入扩散过程,按线性噪声调度从 10⁻⁴到 0.02 逐步添加高斯噪声,迭代 1000 步直至潜在变量近似纯噪声;噪声预测 U-Net 作为核心去噪模块,采用残差块 + 中间 Transformer 块结构,同时接收含噪潜在变量、时间步嵌入、风格嵌入、文本内容编码四类条件信息,实现噪声的精准预测;文本内容编码器对输入词序列进行字符级嵌入与位置编码,再通过多头注意力融合上下文信息,形成文本条件向量;风格嵌入层将离散风格类别映射为连续风格向量,与时间步嵌入融合后作为风格条件;最后由 VAE 解码器将去噪后的干净潜在表示重构为高分辨率手写词图像,完成从条件输入到风格化手写文字的生成闭环。
01
FUTURE
TECHNOLOGY

创新点
WordStylist 在传统手写文字生成方法基础上实现了四大核心创新,全面突破 GAN 类模型的固有局限并拓展扩散模型在手写体生成领域的应用边界。第一,首次将潜在扩散模型(LDM)引入词级风格化手写文字生成任务,区别于 GANwriting、SmartPatch 等依赖对抗损失、易出现模式坍塌与伪影的方法,LDM 通过逐步去噪的生成逻辑,天然具备生成多样性强、细节自然、风格还原度高的优势,同时无需额外 OCR 网络辅助训练,简化模型 pipeline。第二,设计 “风格类别 + 文本内容” 双条件精准控制机制,将离散风格标签映射为可学习风格嵌入、文本序列经字符嵌入 + 位置编码 + 多头注意力融合为上下文感知的文本条件,两类条件独立建模后共同引导 U-Net 去噪,实现任意风格与任意词内容的灵活组合生成,支持训练集外词汇(OOV)生成且保持风格一致性。第三,优化 LDM 架构适配手写文字生成特性,针对手写数据稀缺、图像尺寸固定、字符序列短(2–7 字符)的特点,在 U-Net 中采用单残差块、320 维基础维度、4 头注意力的轻量化设计,平衡模型表达能力与参数量,同时将扩散采样步数从 1000 步降至 600 步,在保证生成质量的前提下大幅提升生成效率,单张词图像生成时间显著缩短。第四,提出风格插值与数据增强的双重实用方案,通过线性加权融合两种风格嵌入实现平滑风格过渡,生成介于两种真实风格之间的新风格手写体,丰富风格多样性;生成的合成手写数据可直接用于手写文本识别(HTR)模型训练,有效缓解标注数据稀缺问题,显著提升真实数据 + 合成数据联合训练下 HTR 模型的识别精度,为文档图像分析领域提供高效数据扩充手段。
FUTURE TECHNOLOGY
02
FUTURE
TECHNOLOGY

文字生成流程
WordStylist 的手写文字生成流程分为训练阶段与采样生成阶段,两个阶段逻辑连贯、分工明确,共同实现从条件输入到高质量风格化手写词图像的输出。在训练阶段,首先对 IAM 离线手写数据库进行预处理,筛选 2–7 字符的手写词图像,统一调整为 64 像素固定高度、256 像素最大宽度,不足宽度中心填充、超出宽度缩放,确保输入尺寸一致;随后构建训练数据集,包含真实手写词图像、对应词文本、书写风格类别标签三类信息;模型训练时,将真实图像送入 VAE 编码器得到潜在表示,从 1–1000 步随机采样时间步,按噪声调度向潜在表示添加高斯噪声得到含噪潜在变量;同时,文本内容编码器对词序列进行字符嵌入、位置编码与多头注意力融合,生成文本条件向量;风格嵌入层将风格标签映射为风格向量,与时间步嵌入融合得到风格时间条件;噪声预测 U-Net 接收含噪潜在变量、时间步嵌入、风格时间条件、文本条件向量,预测添加的高斯噪声;训练目标为最小化预测噪声与真实噪声的均方误差,采用 AdamW 优化器、10⁻⁴学习率、224 批次大小,在单张 A100 GPU 上训练 1000 轮,直至模型收敛。在采样生成阶段,无需真实图像,仅需输入目标词文本、目标风格类别即可生成手写词图像;首先从标准高斯分布中随机采样纯噪声潜在变量(对应时间步 T=600);随后进入反向去噪过程,从 600 步逐步迭代至 0 步,每一步中,U-Net 根据当前含噪潜在变量、当前时间步、目标风格嵌入、目标文本编码预测噪声;基于预测噪声更新潜在变量,逐步去除噪声、还原干净潜在表示;迭代结束后,将干净潜在表示送入 VAE 解码器,重构输出 64×256 像素的风格化手写词图像;整个生成过程无需对抗训练、风格判别或文本识别,仅通过条件引导与逐步去噪,即可生成自然流畅、风格可控、内容准确的手写文字,且支持批量生成、风格插值生成、OOV 词汇生成等多种实用场景。


FUTURE TECHNOLOGY
03
FUTURE
TECHNOLOGY

评价指标
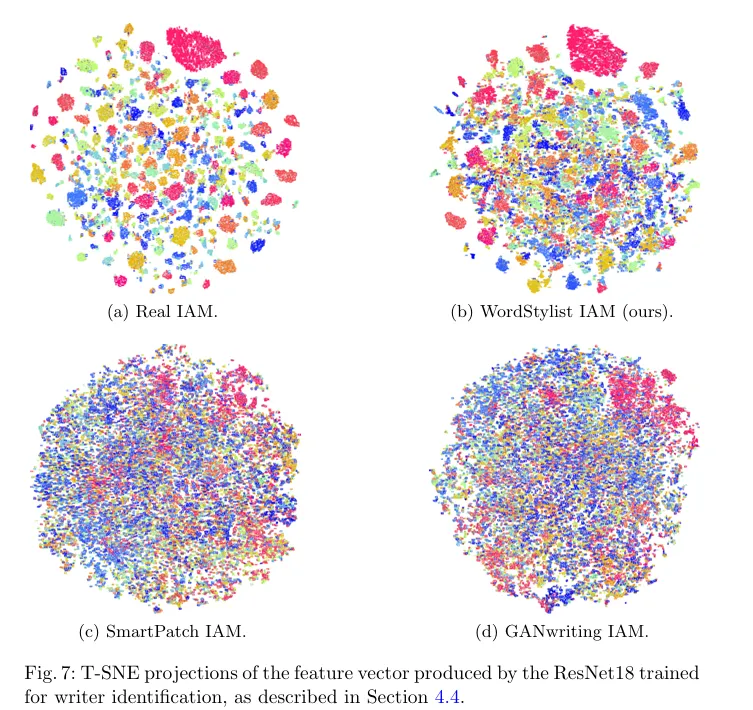
WordStylist 基于 IAM 离线手写数据库开展全面实验,从视觉质量、文本可读性、风格真实性、下游任务性能四大维度设计量化指标,与 GANwriting、SmartPatch 两种主流 GAN 类手写生成方法对比,充分验证模型优越性。在视觉质量指标上,采用弗雷歇 inception 距离(FID)评估生成图像与真实图像的分布相似度,FID 值越低表示分布越接近、视觉质量越高;WordStylist 生成数据 FID 为 22.74,与 SmartPatch(22.55)相当,显著低于 GANwriting(29.94),表明生成手写图像视觉真实度远超 GANwriting,与当前最优 GAN 方法持平。在文本可读性指标上,以字符错误率(CER)、词错误率(WER)衡量生成数据用于手写文本识别(HTR)训练的有效性,CER/WER 越低表示文本可读性越强、对 HTR 提升效果越好;仅用合成数据训练 HTR 时,WordStylist 合成数据 CER 为 8.80%、WER 为 21.93%,远优于 GANwriting(CER 38.74%、WER 68.47%)与 SmartPatch(CER 36.63%、WER 65.25%);真实数据与合成数据联合训练时,WordStylist 组合数据 CER 降至 4.67%、WER 降至 13.28%,显著优于仅用真实数据(CER 4.86%、WER 14.11%)及其他两种组合数据,统计显著性 p 值为 0.035,证明合成数据能有效提升 HTR 性能。在风格真实性指标上,通过风格分类准确率、t-SNE 特征可视化、作者检索 top-1 准确率与 mAP三重评估;用真实数据训练的 ResNet18 风格分类模型测试合成数据,WordStylist 分类准确率达 70.67%,而 GANwriting 与 SmartPatch 仅为 4.81% 和 4.09%;t-SNE 可视化显示,WordStylist 合成数据特征分布与真实数据高度重合,而 GAN 类方法特征分布杂乱无章;作者检索实验中,WordStylist 合成数据与真实数据配对检索 top-1 准确率达 97.13%、mAP 达 97.84%,与真实数据配对(97.45%、97.61%)几乎无差异,而 GAN 类方法 mAP 均低于 8%,充分证明生成风格与真实风格高度一致、难以区分。此外,模型还验证了OOV 生成能力、风格插值平滑度、采样步数对质量的影响,结果显示 WordStylist 能生成训练集外词汇且风格自然,风格插值过渡平滑无突变,600 步采样可平衡质量与效率,低于 500 步则质量明显下降,全面证明模型在各维度的优异性能与稳定性
FUTURE TECHNOLOGY
04
FUTURE
TECHNOLOGY

消融实验
为验证 WordStylist 各核心组件、关键参数对生成性能的影响,论文设计文本条件模块消融、风格条件模块消融、U-Net 架构消融、采样步数消融、风格插值消融五大系列消融实验,逐一验证各设计的必要性与有效性,为模型优化提供坚实依据。文本条件模块消融实验聚焦文本内容编码器的位置编码与多头注意力机制,对比 “无文本条件、仅字符嵌入、字符嵌入 + 位置编码、字符嵌入 + 位置编码 + 多头注意力” 四种设置;结果显示,无文本条件时生成文字内容混乱、字符错误率极高,仅字符嵌入时字符顺序错乱、可读性差,加入位置编码后字符顺序基本正确但上下文连贯性不足,加入多头注意力后能精准捕捉字符间依赖关系、生成文字内容准确清晰,证明位置编码与多头注意力是文本条件有效引导生成的核心,缺一不可。风格条件模块消融实验对比 “无风格条件、随机风格嵌入、可学习风格嵌入” 三种设置;无风格条件时生成风格随机杂乱、无一致性,随机风格嵌入时风格不稳定、波动大,可学习风格嵌入时风格固定且还原度高、与目标风格高度匹配,验证了可学习风格嵌入能有效建模真实书写风格、实现精准风格控制。U-Net 架构消融实验针对 U-Net 残差块数量、基础维度、注意力头数,对比 “1 残差块 vs 多残差块、320 维 vs512 维、4 头注意力 vs8 头注意力”;结果显示,多残差块、高维度、多头注意力虽提升表达能力,但参数量激增、训练难度加大、易过拟合,而 1 残差块、320 维、4 头注意力的轻量化设置,在保持生成质量的同时大幅减少参数量、加快训练收敛、降低过拟合风险,适配手写数据稀缺的特性,是最优架构选择。采样步数消融实验对比 500、600、800、1000 步四种反向去噪步数;500 步时生成图像细节模糊、笔画断裂、伪影明显,600 步时图像清晰、笔画流畅、伪影极少,800 步与 1000 步时质量无明显提升但生成时间显著增加,证明 600 步是平衡生成质量与效率的最优采样步数,低于 500 步质量急剧下降,高于 600 步收益递减。风格插值消融实验选取两种差异明显的书写风格,设置 0.0、0.2、0.4、0.6、0.8、1.0 六种插值权重,生成过渡风格手写词;结果显示,随着权重从 0.0 向 1.0 变化,生成风格从风格 A 平滑过渡至风格 B,笔画形态、连笔特征、字体倾斜度逐步变化,无风格突变或混合失真,证明模型能实现连续风格插值、生成自然过渡的新风格,丰富风格多样性。所有消融实验结果均一致表明,WordStylist 的各项核心设计(双条件控制、轻量化 U-Net、位置编码 + 注意力文本编码器、600 步采样)均为最优选择,各组件协同作用,共同保障模型生成高质量、高可控性、高真实性的风格化手写文字。
05
FUTURE
TECHNOLOGY

总结
WordStylist 作为一款基于潜在扩散模型的词级风格化手写文字生成模型,成功突破传统 GAN 类手写生成方法的技术瓶颈,构建了一套简洁高效、性能优越、实用性强的手写文字生成框架,在手写体生成技术领域实现重要进展与创新。模型摒弃对抗训练范式,依托 LDM 在低维潜在空间建模手写文字分布,通过 “风格嵌入 + 文本编码” 双条件精准控制生成过程,配合轻量化 U-Net 架构与高效采样策略,实现高质量视觉效果、精准内容还原、真实风格复刻、高效生成效率四大核心优势,同时具备训练集外词汇生成、风格插值生成、合成数据增强等实用功能,适配手写文本识别、历史文档复原、字体设计、教育数据扩充等多种应用场景。大量对比实验与消融实验结果充分证明,WordStylist 在视觉质量、文本可读性、风格真实性、下游任务性能等关键指标上全面超越 GANwriting、SmartPatch 等主流方法,生成手写文字与真实手写体高度相似,合成数据能有效提升手写文本识别模型性能,为文档图像分析领域提供高效数据扩充方案,也为扩散模型在手写体、历史文档等小众生成任务中的应用提供了重要参考与实践范例。尽管模型仍存在新风格自适应能力不足、生成速度有待进一步提升、固定图像尺寸限制等局限性,但通过未来引入少样本风格迁移、轻量化扩散模型架构、动态尺寸生成机制等优化方向,可进一步拓展模型能力、提升实用性。总体而言,WordStylist 凭借创新的模型设计、优异的生成性能、丰富的实用功能,为风格化手写文字生成提供了全新、高效、可靠的解决方案,推动手写体生成技术从 GAN 时代迈向扩散模型时代,具有重要的学术价值与广阔的应用前景
编辑人:周诚杰