 夜雨聆风
夜雨聆风





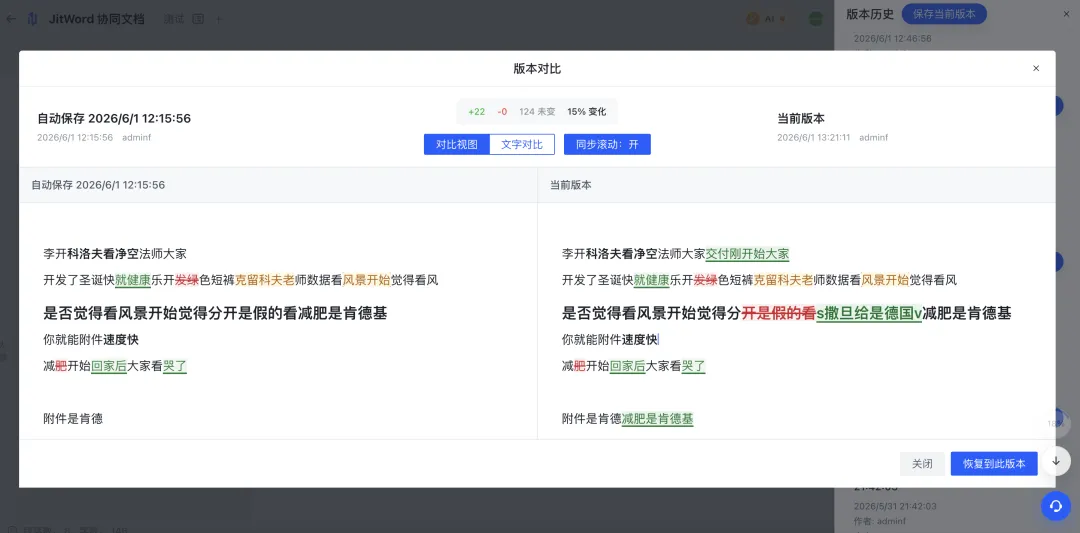
死磕Word修订模式+版本历史功能,我们终于实现了Web版高精“”
趣谈AI精选:《最系统的AI开发学习精品手册》
徐小夕
话不多说,先上链接:
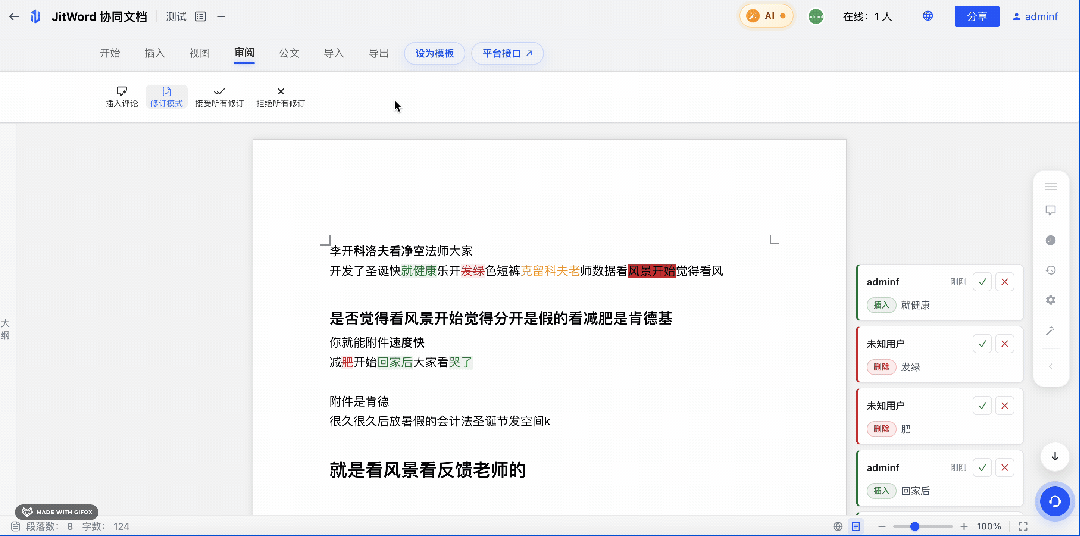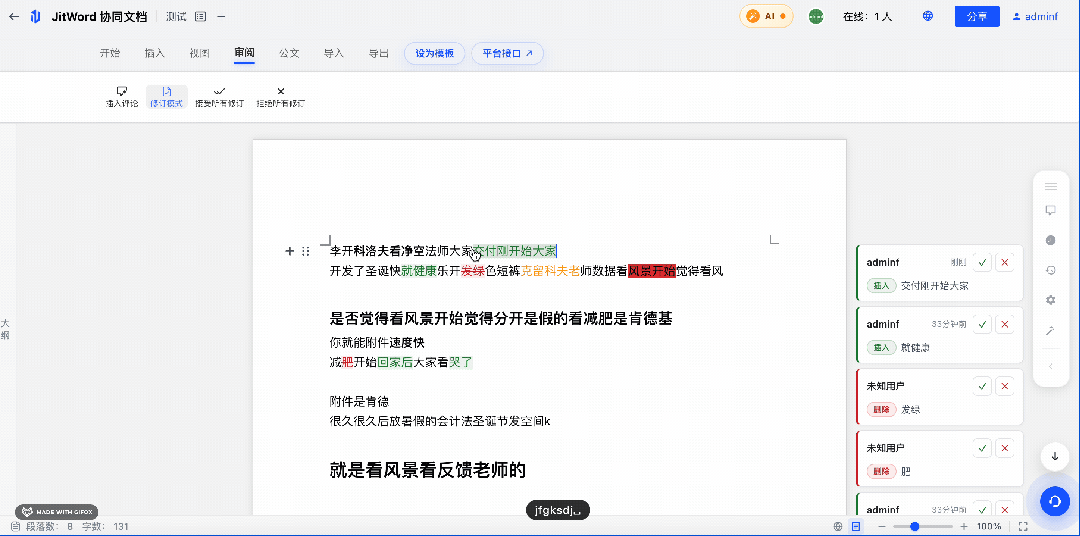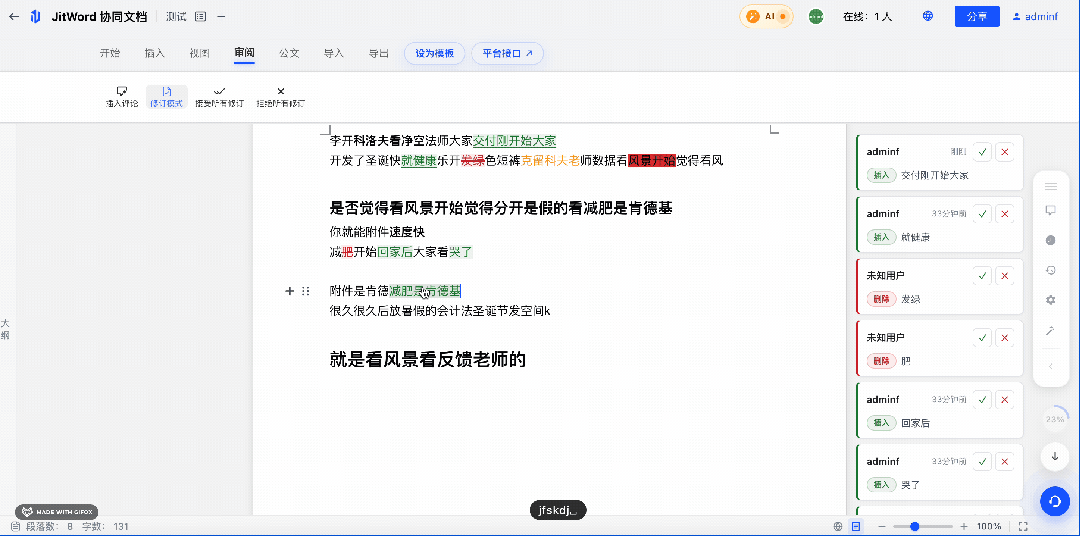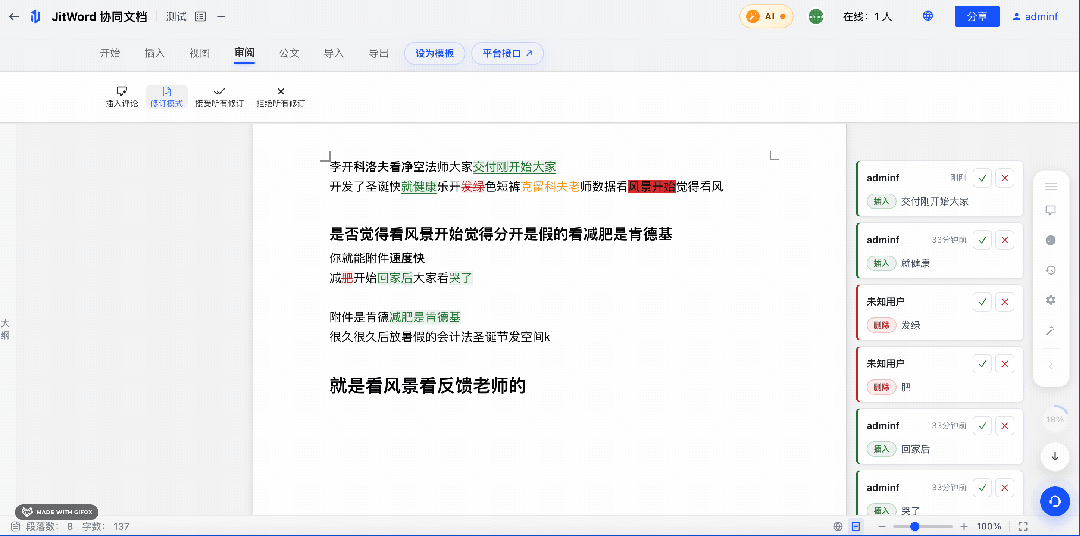
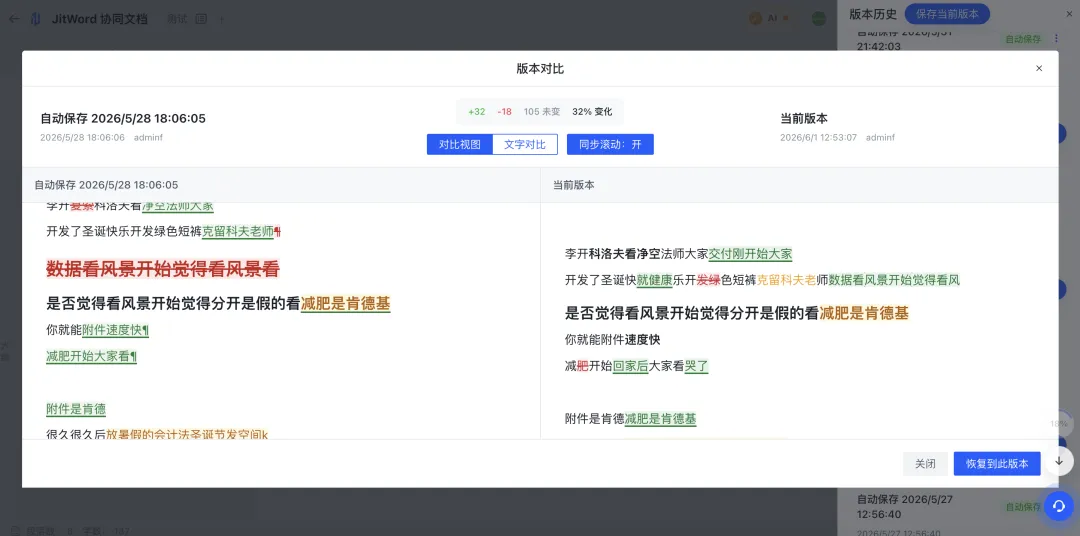

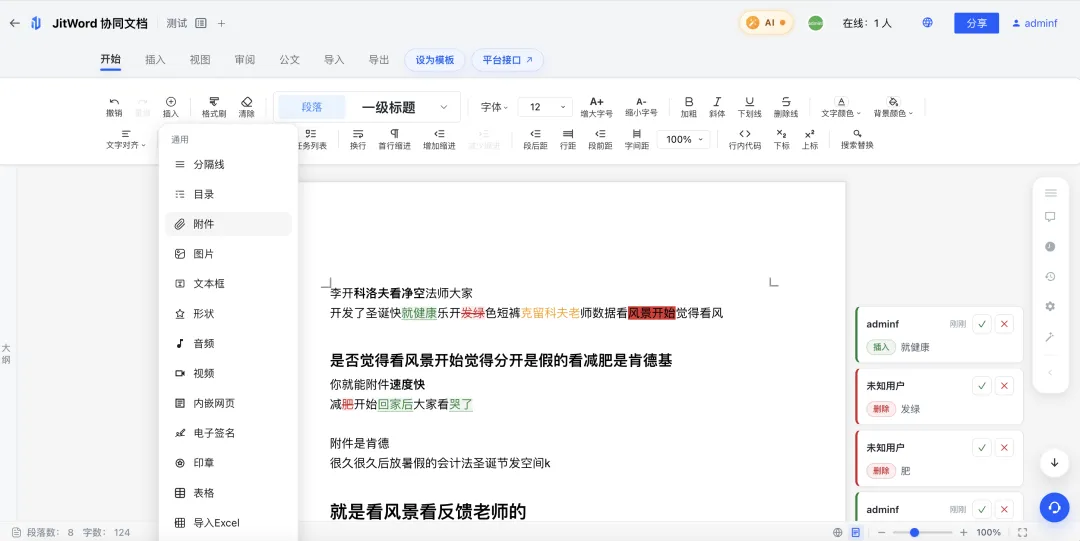
技术架构设计:JitWord 如何实现”毫秒级”版本对比?
编辑记录和版本对比高亮,听起来简单,实现起来却涉及协同编辑算法、数据结构、渲染引擎等多个技术难点。
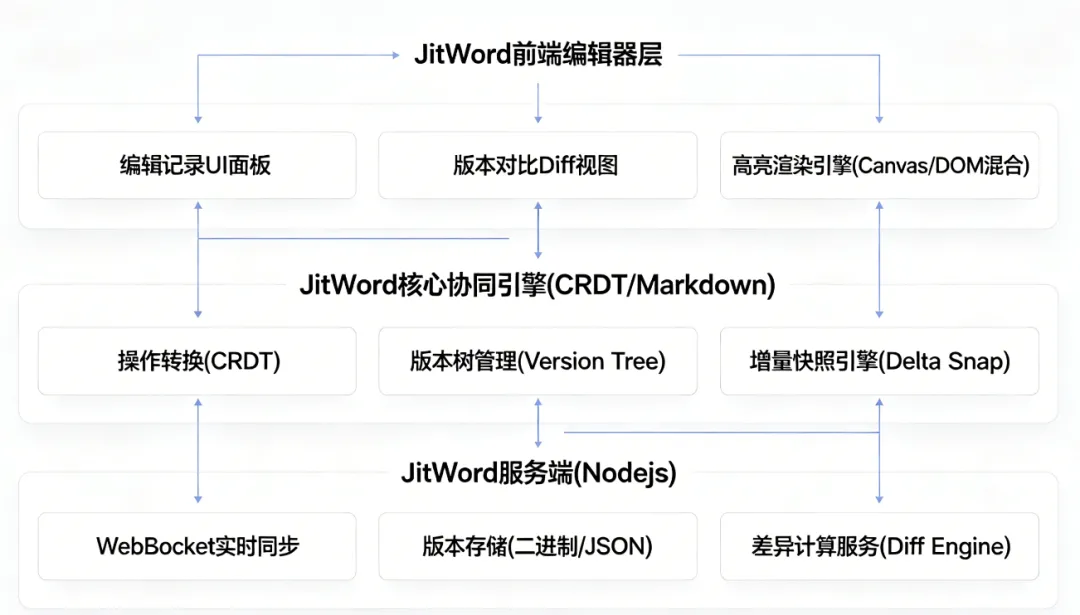
下面我从架构层面拆解 JitWord 的实现方案。
先聊聊协同方案
协同编辑的两大主流方案——OT 和 CRDT——已经争论了十几年。在决定 JitWord 的底层架构时,我们做了全面的技术评估,这里分享给大家参考:
|
|
|
|
|
|---|---|---|---|
| 一致性保证 |
|
|
|
| 离线支持 |
|
|
|
| 编辑记录追溯 |
|
|
实现编辑记录功能更简单、更完整 |
| 版本对比 Diff |
|
|
Diff 计算更直接、更准确 |
| 私有化部署 |
|
|
|
| 工程复杂度 |
|
|
|
最后我们得出的结论: 对于”编辑记录”和”版本对比”这两个需求,CRDT 的 Tombstone 机制 和 全局唯一 Item ID 是天然的最佳拍档。
编辑记录的实现方案
传统 OT 方案要实现编辑记录,需要额外维护一个操作日志:

而 JitWord 的 CRDT 方案中,编辑记录的数据结构和我们的文档数据结构天然适配,实现流程如下:
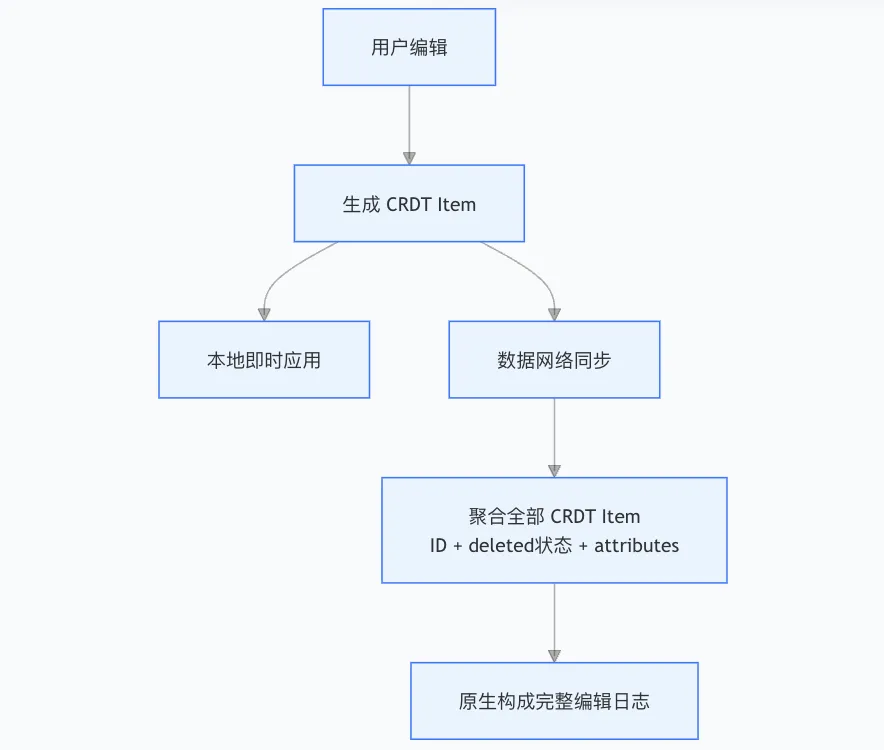
这种设计让”编辑记录”不是用户操作后计算出来的,而是协同编辑过程中的自然产物,性能开销极低。
版本管理实现方案:不只是线性历史
传统的”历史版本”是线性的:v1 → v2 → v3 → v4。
但真实的协同场景是分支化的:
-
用户 A 在 v3 基础上编辑,生成 v4
-
用户 B 也在 v3 基础上编辑,生成 v4′
-
两个版本需要合并
JitWord 采用 Version Tree(版本树) 结构管理文档历史,类似如下:
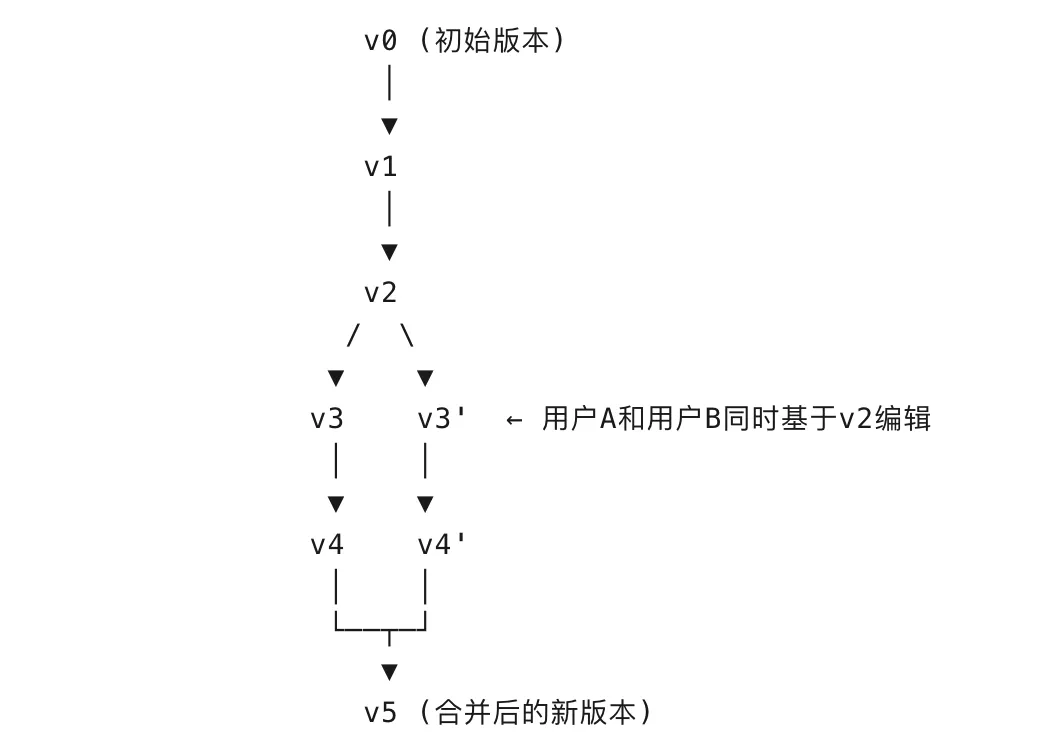
每个版本节点包含:
-
snapshot:该版本的完整文档快照(用于快速恢复)
-
parentId:父版本 ID
-
operations:从父版本到当前版本的增量操作序列
-
metadata:作者、时间、编辑摘要等
存储优化策略
为了控制存储成本,我们采用了混合存储策略:
-
每 N 个版本保存一个完整快照(默认每 10 个版本)
-
中间版本只保存增量 Operation 序列
-
需要恢复某个版本时,找到最近的快照 + 回放后续 Operation
Diff 引擎:毫秒级差异计算
版本对比的核心是 Diff 算法——计算两个文档版本之间的差异。
我们 JitWord 的 Diff 引擎采用 Myers’ Diff Algorithm 的优化版本,针对富文本场景做了深度定制:
标准 Myers 算法的问题:
-
基于行/字符级别的 LCS(最长公共子序列)
-
对富文本(带格式、图片、表格)支持差
-
时间复杂度 O(ND),大文档性能差
我们的优化方案如下:
|
|
|
|
|---|---|---|
| 结构化 Diff |
|
|
| 格式感知 |
|
|
| 语义合并 |
|
|
高亮渲染引擎:让差异”一眼可见”
Diff 计算完成后,需要在编辑器中以高亮形式呈现差异,方便用户一目了然地看到修改差异点。
我们在设计 JitWord 协同AI文档时, 考虑了 Canvas + DOM 混合渲染的方案:
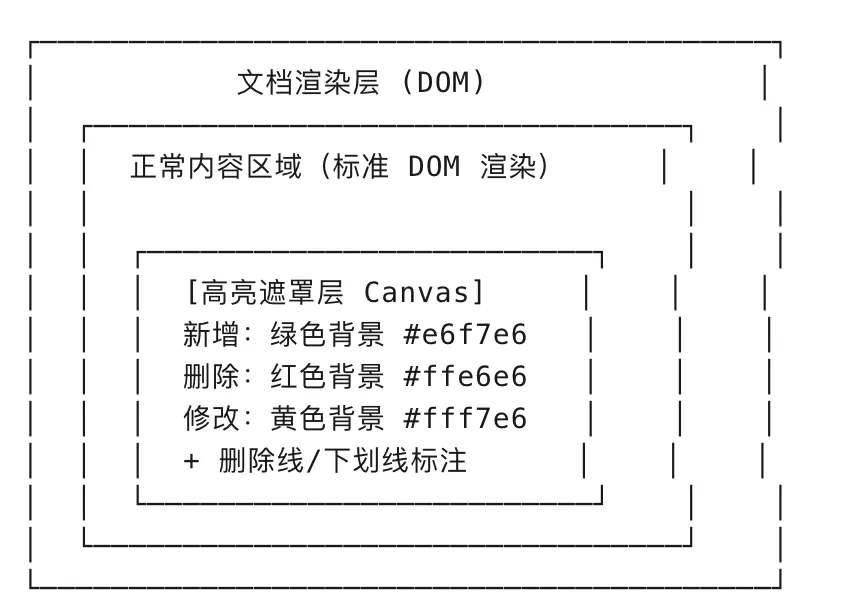
性能优化:大文档也能流畅对比
我们在真实场景下做了性能测试,数据如下:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
20ms |
|
|
|
|
|
|
75ms |
|
|
|
|
|
|
205ms |
|
|
|
|
|
|
600ms |
注:所有测试在 Chrome 浏览器、普通笔记本(i5-1240P)环境下进行。1MB 大文档的对比总耗时控制在 1 秒内,完全满足日常使用需求。
未来规划
下一个版本,我们将上线 JitWord 3.0 版本,从UI层和功能上,全面对标 Word 文档,让企业轻松拥有一套可扩展,高性能的web版协同文档解决方案。
JitKnow V2.0.0:从可视化知识库到企业级AI中台,开放API+数据分析重构知识管理边界