 夜雨聆风
夜雨聆风





从代码生成到基于OpenClaw的AI软件工厂架构升级
最近一段时间,Cursor、Devin、Windsurf这些AI编程工具火得不行,论坛和社交媒体上刷屏的都是“用AI一次性写完一个完整项目”的视频。但如果你真的带过团队,就会发现一个很残酷的现实:这些工具所展示的能力——从零开始生成一个新项目——在真实的研发工作里占比少得可怕。
说得直白一点,大多数 AI Agent 软件工厂的设计图看起来很漂亮,但它们实际上只适用于一种场景:从零开始开发一个新项目。这种情况在真实的研发工作中大概只占 10%。
真实的研发时间是怎么分布的?我根据自己和身边多个团队的实际经验,给出一个大致的比例:新项目开发占 10%~20%,功能迭代占 50%~60%,Bug修复占 20%~30%,紧急需求变更占 10%~20%。
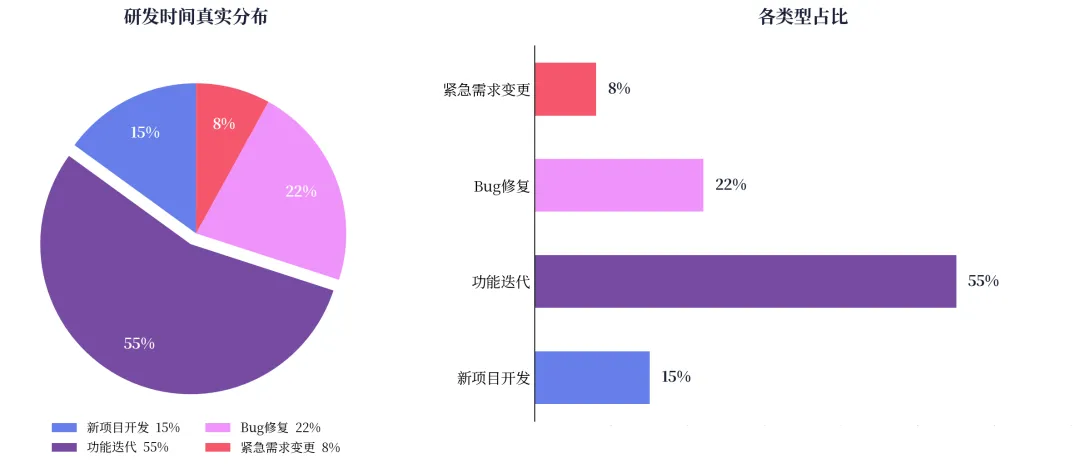
图 1:研发团队时间分布示意图
如果一套 AI Agent 体系只能解决新项目开发这个场景,那它的实际价值就很有限了。这就像你买了一台可以开开心心从零造车的机器人,结果发现工厂里 90% 的工作是维修和改造现有产品线——这台机器人再先进,也只能干着急。
所以我们决定在 OpenClaw 上做一件不一样的事情:不是搭一个“代码生成系统”,而是搭一个“项目生命周期系统”。
架构升级:从CTO Agent到研发操作系统
先说明一下 OpenClaw 是什么。OpenClaw 是一套基于多 Agent 协作的开源框架,它的核心理念是让不同专长领域的 AI Agent 像一个真实的研发团队一样协作工作。最初的设计很直观:用户接入 CTO Agent,CTO Agent 拆解任务,分发给各个领域 Agent,最后汇总产出。
这套架构对于新项目来说运转良好,但很快就撞到了块。当用户说“给微信商城加个优惠券功能”的时候,TO Agent 就蒙了。它不知道现有代码长什么样,不知道数据库结构是怎么回事,不知道业务边界在哪里,更不知道系统有哪些技术债务。如果这时候直接开始生成代码,那和一个刚入职不了解项目的程序员直接动手写代码没有什么区别。
所以我们在原有架构中加入了两个核心组件:Project Analyzer(项目分析器)和 Change Planner(变更规划器)。调整后的架构是这样的:

图 2:OpenClaw 研发操作系统架构示意
用户依然只和 CTO Agent 对话,但 CTO Agent 的背后不再是直接连接任务图和各个执行 Agent,而是先经过 Project Analyzer 理解现有项目,再通过 Change Planner 规划变更,最后才生成任务图分发给执行 Agent。这一层“缓冲”是整个体系能不能真正落地的关键。
Project Analyzer:让AI不再靠猜
Project Analyzer 的作用不是理解用户需求,而是理解现有系统。它做的第一件事是扫描代码仓库,从目录结构到源代码,从数据库 Schema 到 API 接口,全面地建立对项目的认知。这个过程输出一个完整的 Project Memory,包含几层信息。

图 3:Project Analyzer 工作流程示意
Code Graph:代码关系图
第一层是 Code Graph。假设这是一个微信商城项目,Project Analyzer 会扫描整个代码库,识别出所有的 Service、Controller、Model 等核心模块,然后建立它们之间的调用关系。比如 UserService 被 OrderService 调用,OrderService 依赖 PaymentService,这些关系会被自动记录下来。以后任何 Agent 在写代码前,都会先查这张图,而不是靠猜或者凑合来判断模块关系。
Dependency Graph:依赖关系图
第二层是 Dependency Graph。这层关注的是业务层面的依赖,而不是代码层面的调用。比如“订单”依赖“库存”,“库存”依赖“商品”,这种业务链路是理解系统行为的基础。当某个环节出现问题时,可以快速定位上游和下游的影响范围。
API Graph 和 Database Graph
还有 API Graph 和 Database Graph。前者记录所有接口的路由、参数、返回值结构,后者记录所有数据表的字段、索引、外键关系。四层图谱叠加在一起,就形成了一个完整的 Project Memory。这个 Memory 是持久化的,随着项目迭代不断更新,所有 Agent 的决策都基于这个共享的认知底座。
一个真实的例子
说回才才“增加优惠券功能”的场景。如果没有 Project Analyzer,CTO Agent 可能会直接创建一个新的 CouponService。但有了 Project Analyzer 之后,CTO Agent 会先查询 Knowledge Graph,发现项目中已经存在一个 PromotionService(营销服务)。这时候它会自动判断:优惠券应该归属营销域,应该扩展 PromotionService 而不是新建一个独立的 CouponService。
这个看似简单的决策,在真实项目中意义重大。如果每次新功能都新建一个独立服务,架构会迅速腐化,服务之间的边界会越来越模糊,不久之后整个项目就会变成一团乱麻。Project Analyzer 就是专门用来防止这种事情发生的。
场景二:已有项目的功能迭代
功能迭代是研发工作里占比最大的部分,也是最能体现一套体系成熟度的地方。它的流程和新项目开发完全不同。
新项目的流程是:需求 → 规划 → 架构 → 拆分任务 → 开发 → 测试 → 上线。每一步都是从头开始,没有历史包袱。但功能迭代必须先进行“影响分析”——这个新功能会触及哪些现有模块,需要改动哪些接口,是否会破坏现有功能。
在 OpenClaw 体系中,当用户提出一个新功能需求时,CTO Agent 会先把需求交给 Project Analyzer,让它基于 Project Memory 进行影响分析。分析结果会明确告诉你:需要修改哪些服务、新增哪些接口、数据库需要做哪些变更。然后才生成任务图,分发给各个执行 Agent。
这个流程跟经验丰富的技术经理做的事情其实是一样的:先理解现状,再规划变更,最后才动手。只是现在这件事由 AI 来完成,而且它对项目的理解比大多数人类新手更全面。
场景三:Bug修复的正确姿势
Bug 修复是所有场景里最复杂的。不是因为代码难写,而是因为你需要先找到问题的根因,再评估修复的影响范围,最后才能动手。直接修复是很危险的,因为你可能修好了一个 Bug,同时引入了三个新 Bug。
我们在 OpenClaw 中为 Bug 修复设计了一套独立的 Incident Workflow,和需求开发完全分离。Bug 的来源通常有四种:监控报警、测试发现、用户反馈、日志异常。无论哪种来源,进入系统后都会被交给 Incident Agent 处理。

图 4:Bug 修复工作流示意
Incident Agent 会自动收集相关信息:链路追踪日志、服务指标、最近的代码提交记录、配置变更、第三方接口状态。然后自动分析根因,生成一份完整的 Root Cause 报告。
但关键的一步是“影响分析”。修复之前,系统会自动评估:这个问题会影响哪些相关功能?修复后是否会破坏现有的业务链路?需要做多大范围的回归测试?只有这些都清楚了,才会进入实际的代码修改阶段。修改完成后还会自动触发回归测试,确保修复没有引入新问题。
整个流程是:Root Cause → 影响分析 → 修复方案 → 代码变更 → 回归测试 → 部署。每一步都有明确的输入和输出,不会出现“看着像修好了其实没有”的情况。
场景四:需求变更的“救赎”
需求变更是很多团队最痛苦的事情,没有之一。举个典型的例子:原来的需求是“积分抵扣”,开发到一半的时候,老板突然说“改成优惠券体系”。传统做法是接受现实,把已经写好的代码丢掉一部分,重新开始。这个过程浪费不说,还很容易引入新的 Bug。
图 5:Change Planner 变更影响分析示意
我们专门设计了 Change Planner 来处理这种场景。它的工作方式是:同时接收“旧需求”和“新需求”,然后基于 Project Memory 分析两者之间的差异,自动生成一份 Impact Report。
报告会明确告诉你:哪些模块受影响、哪些接口需要删除、哪些接口需要修改、哪些接口需要新增。这时候用户可以根据这份报告做出明确的决策:是继续执行变更,还是取消。这比传统的“老板说改就改”要理性得多。
更重要的是,Change Planner 能够识别出“可复用的部分”。比如“积分抵扣”和“优惠券体系”都涉及订单结算环节的改动,那么已经完成的订单模块改造工作可以大部分保留。只有与积分直接相关的部分才需要回退和重写。这种精确的变更控制能大幅减少浪费。
Project State Engine:整个体系的核心
前面说了很多具体场景和组件,但如果只能挑一个最重要的东西,我会说是 Project State Engine——项目状态引擎。它是整个体系的底层基础,所有 Agent 的决策都依赖于它。
Project State Engine 维护的信息包括:当前的需求列表和状态、当前的架构和模块关系、数据库 Schema 和变更历史、代码库的当前状态、部署状态和环境信息、当前未关闭的 Bug 和异常、所有进行中的任务及其进度。
这意味着 CTO Agent 不需要问“项目现在开发到哪了”,因为 Project State Engine 已经知道。它也不需要问“最近改了什么”,因为所有的变更都被记录在案。更不需要问“这次修改会影响什么”,因为项目状态引擎 + Project Memory 可以给出精确的答案。
换句话说,它让整个系统始终知道三件事:项目现在是什么状态,为什么会变成这样,这次修改会影响什么。一旦这三件事解决了,新项目开发、功能迭代、Bug修复、需求变更,其实都只是同一个状态机上的不同工作流。
四条流水线:真正的研发操作系统
前面说的所有场景,最终汇聚成四条并行的流水线,它们都建立在 Project State Engine 这个统一的底座之上。

图 6:四条流水线架构总览
新项目流水线
这是最基础的一条,流程为:创意 → PRD → 架构设计 → 代码开发 → 部署上线。从零开始搭建一个全新的项目,每一步都由 Agent 自动完成,但人在关键节点可以干预和审批。完成后,项目的完整状态会被写入 Project State Engine,作为后续所有操作的基础。
功能迭代流水线
流程为:需求输入 → 影响分析 → 任务拆分 → 代码开发 → 部署上线。它和新项目流水线的关键区别在于第一步“影响分析”。这一步基于 Project Memory 和 Dependency Graph,确保新功能的加入不会破坏现有的架构和功能。
Bug 处理流水线
流程为:事件触发 → 根因分析 → 修复方案 → 代码变更 → 回归测试 → 部署。整个过程由 Incident Agent 主导,强调的是“先诊断再开刀”。从事件触发到代码修复之间,必须经过完整的诊断和影响评估。
需求变更流水线
流程为:变更申请 → 影响分析 → 审批确认 → 任务拆分 → 代码开发 → 部署。它和功能迭代的区别在于“审批确认”环节——因为变更可能涉及已有功能的回退,风险更大,需要人类确认后才能继续。
四条流水线并行运行,共享同一个 Project State Engine。无论哪条流水线产生的变更,都会实时反映到项目状态中。这样,当一个 Bug 正在修复的时候,如果有一个新功能需求进来,系统能立刻知道当前的全局状态,从而做出正确的决策。
CTO Agent 的真正职责
在这套体系中,用户永远只跟一个 CTO Agent 交流。但 CTO Agent 的核心工作不是生成代码,而是维护项目状态、协调工作流、控制变更风险。代码生成反而只是整个流程中最简单的一部分。
这就像一个真正的 CTO:他不会每天坐在那里写代码,他的主要工作是确保团队知道项目的全局状态,确保每个变更都经过充分评估,确保架构不会因为一次随意的修改而腐化。代码是工程师写的,但方向是 CTO 把握的。
基于 OpenClaw 搭建的这套体系,本质上是把这种“CTO 级别的判断力”编码到了系统里。它不是一个“多 Agent 聊天系统”,而是一个真正的研发操作系统——一个能够管理项目全生命周期的 DevOS。
我们相信,AI 编程的未来不是“用 AI 写更多的代码”,而是“用 AI 做更好的决策”。代码生成是最容易解决的部分,真正难的是让系统始终知道项目的状态、理解变更的影响、维护架构的健康。这三件事才是一个研发操作系统的核心价值。