 夜雨聆风
夜雨聆风





用龙虾(Openclaw)实现一个群聊识图记账机器人
用龙虾(Openclaw)实现一个群聊识图记账机器人

我发现一个超完美的职业规划:程序员35岁被毕业,花1年时间高考,读5年医学院,40多岁拿证当老中医。还有年龄优势,患者看外表就会很信任!
开个玩笑,回归正题。前段时间,运营同学提了个需求——想实现一个群聊识图记账机器人。需求不复杂,但挺实在:
-
把所有运营拉进一个群,微信群或钉钉群都行; -
在群里 @机器人,发一张手机截图,再带上账户名、账户ID,机器人就能自动把图片里的提款信息识别出来,记到在线文档(比如飞书表格); -
记账时,能按时间等规则过滤掉一些无效记录; -
另外有个注意点:之前用 WorkBuddy 直接识图,发现 token 消耗很快,希望能降低用量,毕竟这关系到成本嘛。
图片各种各样,比如这样的:
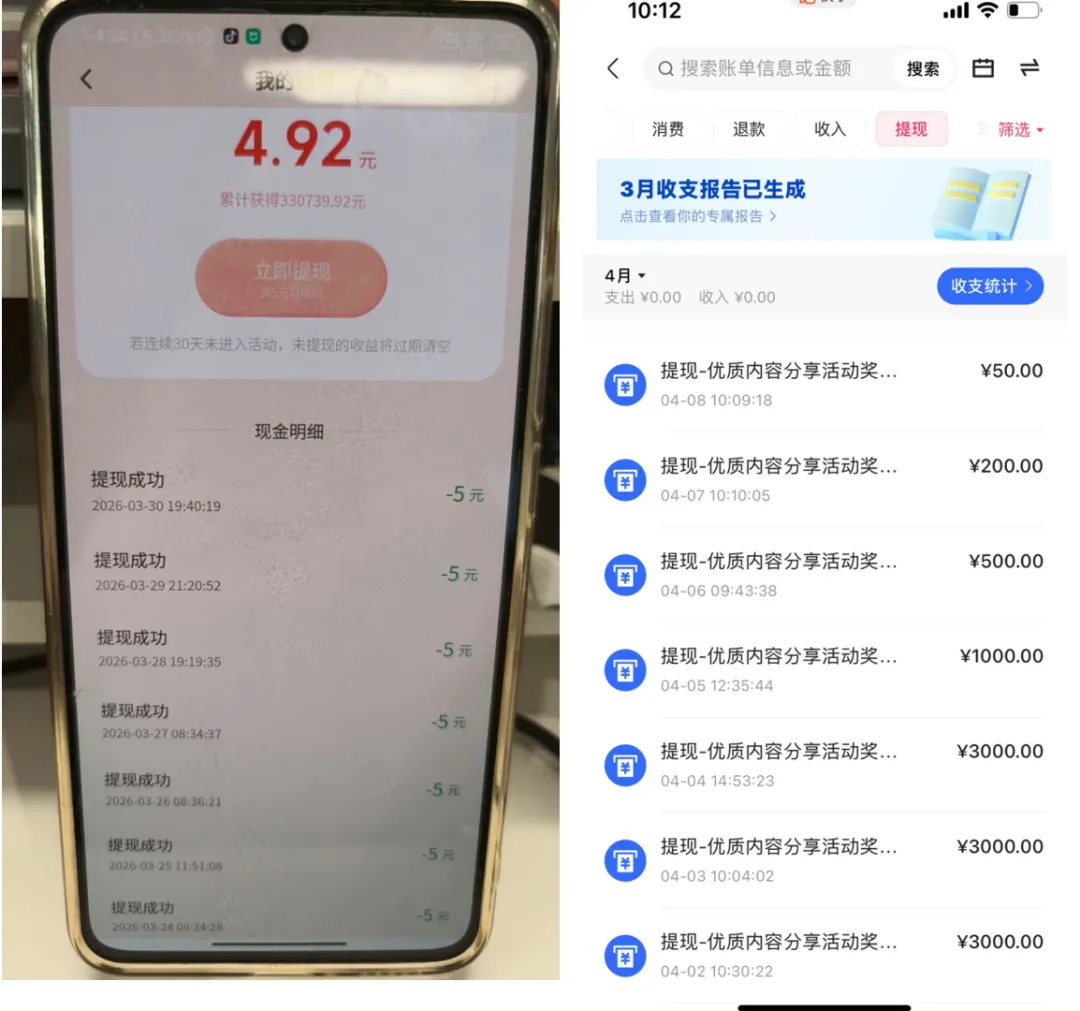
一、技术选型:为什么不用 Dify,而用 WorkBuddy + 钉钉
我们当然可以像《业级知识库与智能客服系统搭建指南(基于DeepSeek-R1:14B)》一文中提及的办法一样,用 Dify或者n8n 定义一套工作流,再部署 Dify-on-WeChat 作为微信机器人。然而,这个方法实在是有点费时费力。
考虑到最近龙虾(OpenClaw)比较火,就打算尝试用龙虾来实现一下相关功能。龙虾也不想用原生的 OpenClaw 了,哪个方便用哪个。我试用了一圈市面上的工具:
- 腾讯 Qclaw
每一个聊天都是一个不同的会话; - WorkBuddy
所有聊天共用一个会话; - 网易 LosterAI
介于两者之间,可以配置会话,但发图和文字有 bug,会丢图;
因此决定使用 WorkBuddy。又由于微信没法把龙虾机器人拉进群里(微信生态的限制),因此最终选择钉钉群。
二、方案架构:本地 OCR + 大模型纠错 + 飞书落库
针对该需求,我大致画了个方案:
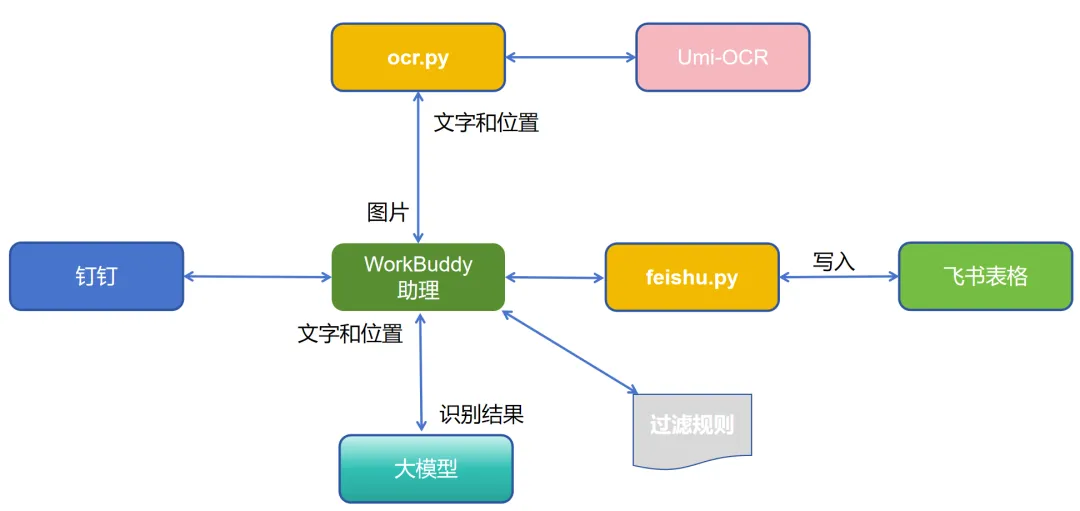
主要的思路如下:
- 本地部署 Umi-OCR
对图片进行 OCR 识别,图片不需要大模型直接识别,可以大量节约 token; - 脚本封装
ocr.py封装 Umi-OCR 的 OCR 操作;feishu.py封装飞书表格的写入操作。WorkBuddy 每次接收到记账命令时,分别调用这两个脚本,把能力固定化; - AI 大模型兜底
在使用时,AI 大模型根据 OCR 识别结果(文本、位置)进行最后的记账记录识别、结果过滤规则匹配,最终得到记账记录。原则是 AI 尽量处理模糊的数据,不跟 OCR 抢活; - 过滤规则人类语言化
方便运营随时修改。规则类似这样:
# 1、只要 3月26日-4月1日 的记录;# 2、不要"收入"开头的记录;# 3、需要"优质内容分享活动奖励"的记录;# 4、对于"提现成功"的记录,例如:"-5元",表示账单金额是5元,这种记录也是合法的提现账单,需要写入文档;三、环境搭建:安装 Umi-OCR
既然确定了方案,就可以指导 WorkBuddy 干活了。
首先,安装 Umi-OCR,推荐使用 Rapid 版。速度更快、体积更小(约 98MB),适合日常快速使用。没有 WorkBuddy 的话,需要自己去 https://github.com/hiroi-sora/Uni-OCR/releases 下载并安装;有了 WorkBuddy,直接提示它干活就行了。

安装完成后,Umi-OCR 会在本地启动 HTTP 服务,默认地址是:
http://localhost:1529/api/ocr四、核心脚本一:ocr.py
指示 WorkBuddy 编写 ocr.py,要求很简单:
-
调用 Umi-OCR 接口 http://localhost:1529/api/ocr,获取原始图片 OCR 结果; -
执行 ocr.py <截图路径>,返回 OCR 原始结果(JSON)。
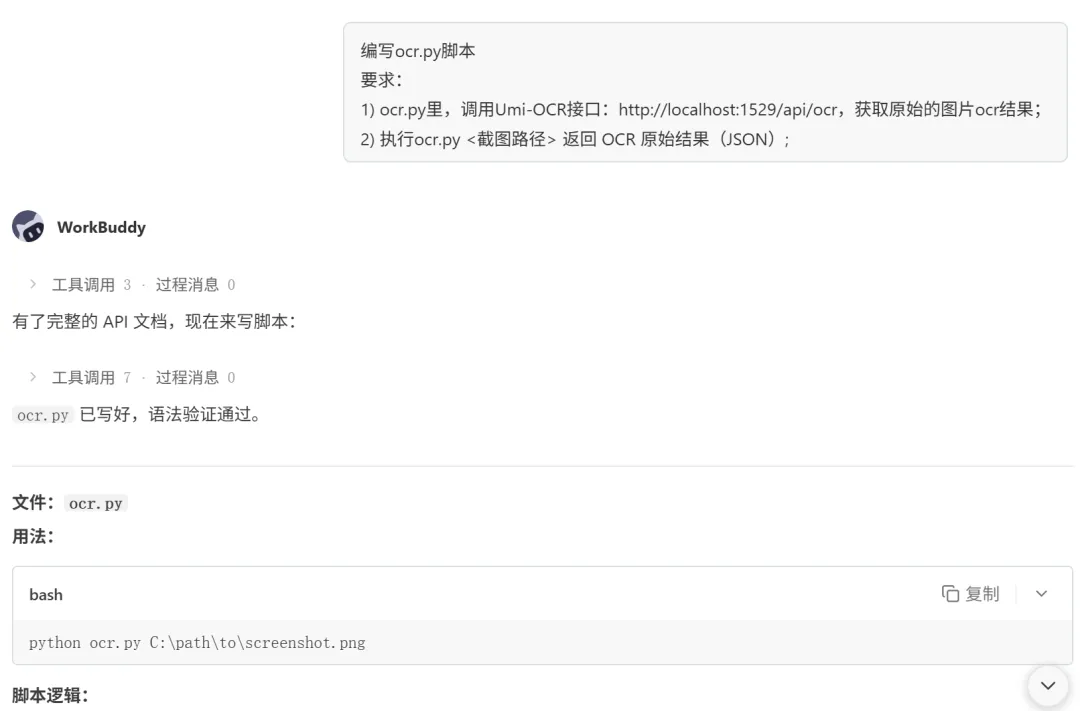
脚本逻辑不复杂,但有个关键点:Umi-OCR 的返回,都只是类似如下的文本和位置信息:
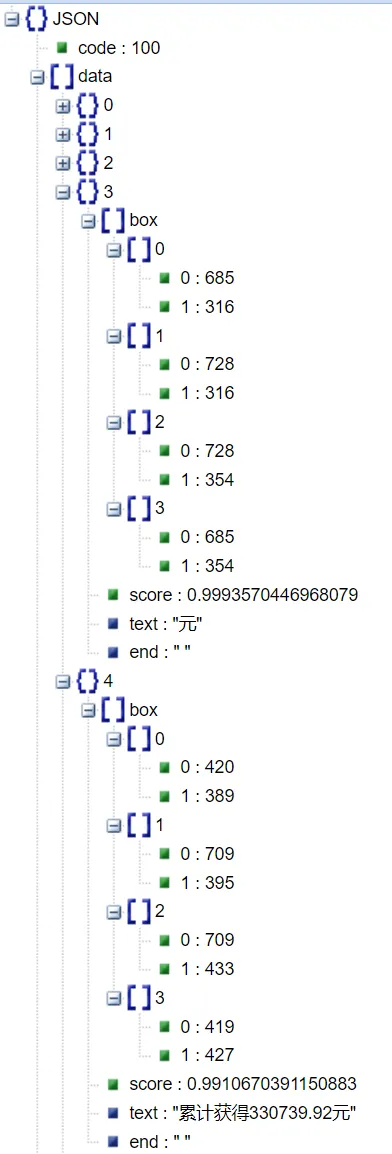
如果要用传统程序把这些零散文本整理为结构化的记账记录,工作量很大,效果也不好。这时大模型的优势就体现出来了——它最擅长处理这种”模糊结构化”的事情。把原始的 OCR 结果交给它就行。
五、核心脚本二:feishu.py
5.1 飞书开放平台配置
在写脚本之前,先申请飞书开放平台权限。到 https://open.feishu.cn/app/cli_a9463d4d64fb5cd1/baseinfo 获取 App ID 和 App Secret。

拿到凭证后,两步走获取表格的token:
-
用
AppID + AppSecret换取tenant_access_token:curl --location 'https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal' \--header 'Content-Type: application/json' \-d '{"app_id":"cli_xxxxxxxxxx","app_secret":"BdWxxxxxxxxxx"}' -
用
tenant_access_token去获取表格的SPREADSHEET_TOKEN。
其实,这个获取表格token的活,让WorkBuddy自己去获取就行,但是程序员暂时还是习惯性太勤快。
5.2 脚本编写
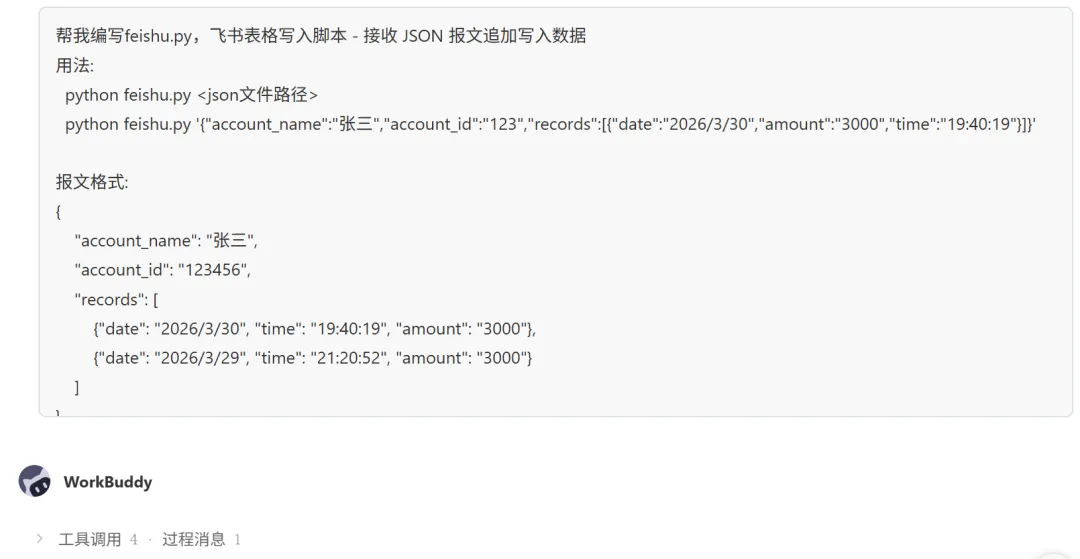
指示 WorkBuddy 编写 feishu.py,飞书表格写入脚本:
-
接收 JSON 报文,追加写入数据; -
用法: python feishu.py <json文件路径>或python feishu.py '{"account_name":"张三","account_id":"123","records":[{"date":"2026/3/30","amount":"3000","time":"19:40:19"}]}'; -
表头固定为:日期 | 姓名 | 快手ID | 提现金额 | 具体时间; -
每一行颜色不一样,使用交替颜色,通过记录在本地状态文件中实现。
六、过滤规则:filt.md
指引 WorkBuddy 编写过滤规则文件 filt.md,写入如下内容:
# 1、只要3月26日-4月1日的记录;# 2、不要"收入"开头的记录;# 3、需要"优质内容分享活动奖励"的记录;# 4、对于"提现成功"的记录,例如:"-5元",表示账单金额是5元,这种记录也是合法的提现账单,需要写入文档;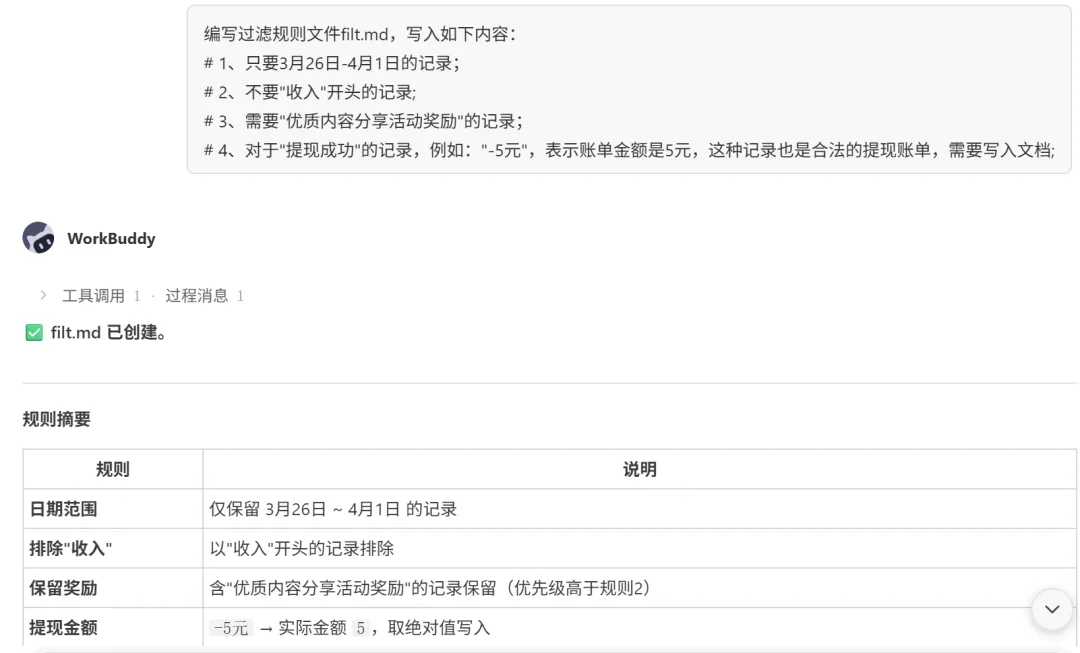
七、钉钉机器人集成
7.1 获取应用凭证
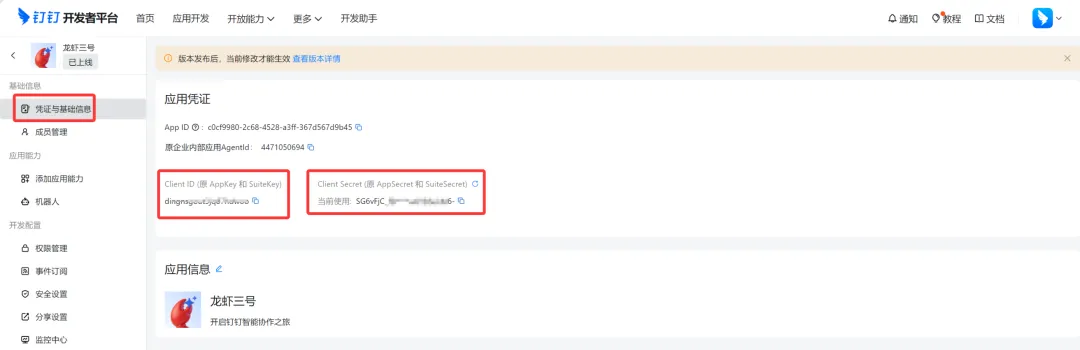
根据WorkBuddy助理设置中钉钉机器人的配置指南,登录钉钉开发者后台,一步步完成机器人的创建、发布。最后获取钉钉机器人的应用凭证,包括 Client ID 和 Client Secret。
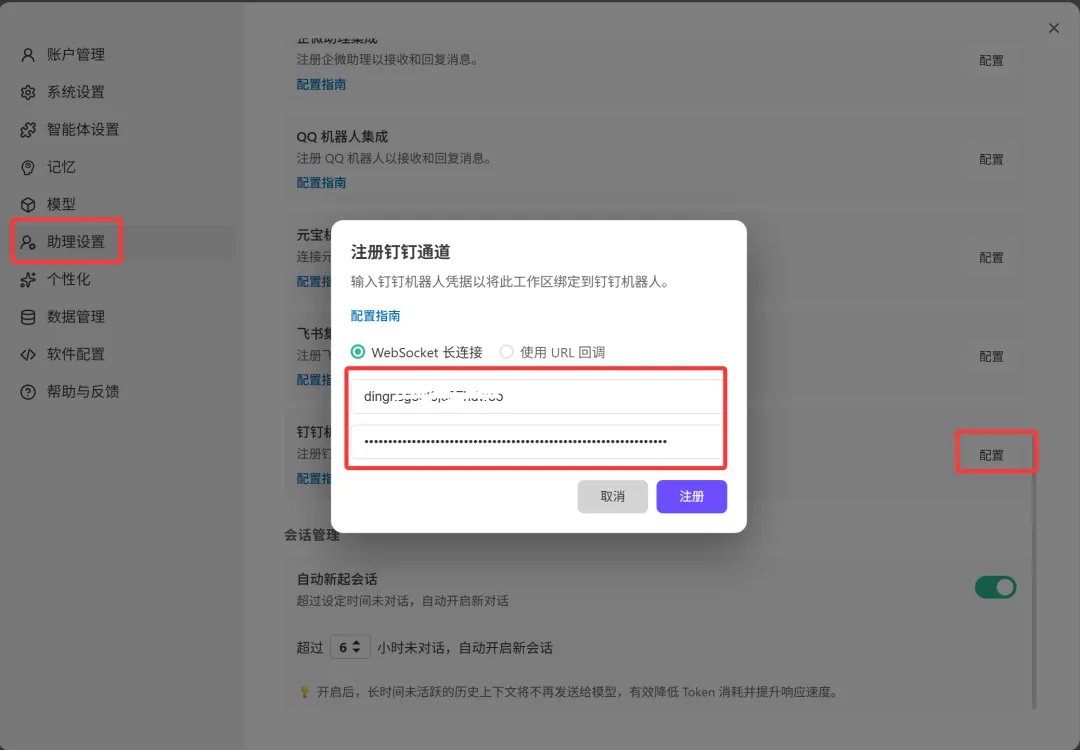
7.2 注册钉钉通道
在 WorkBuddy 的助理设置中,注册钉钉通道的配置,选择 WebSocket 长连接模式。
7.3 完整工作流程
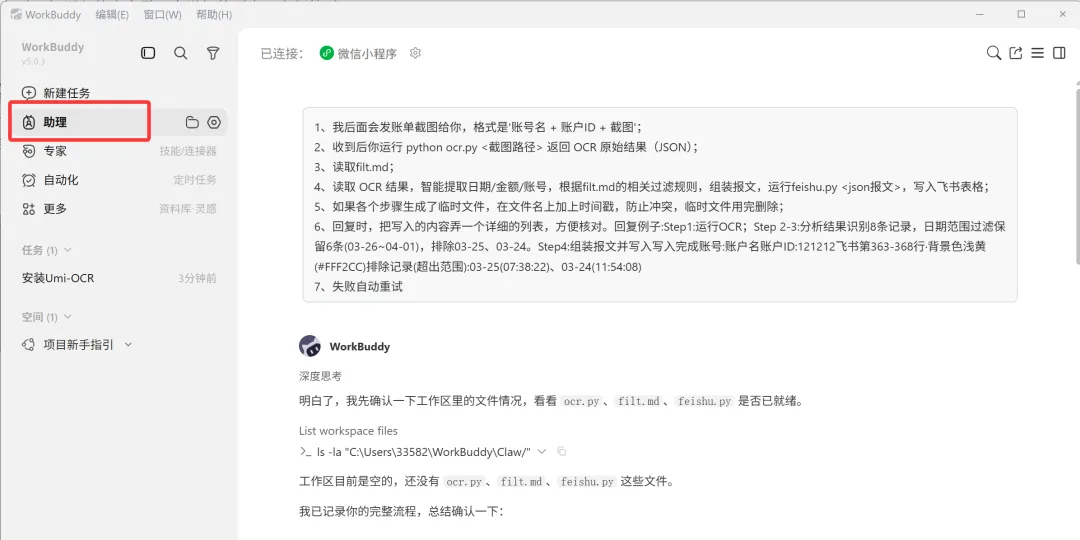
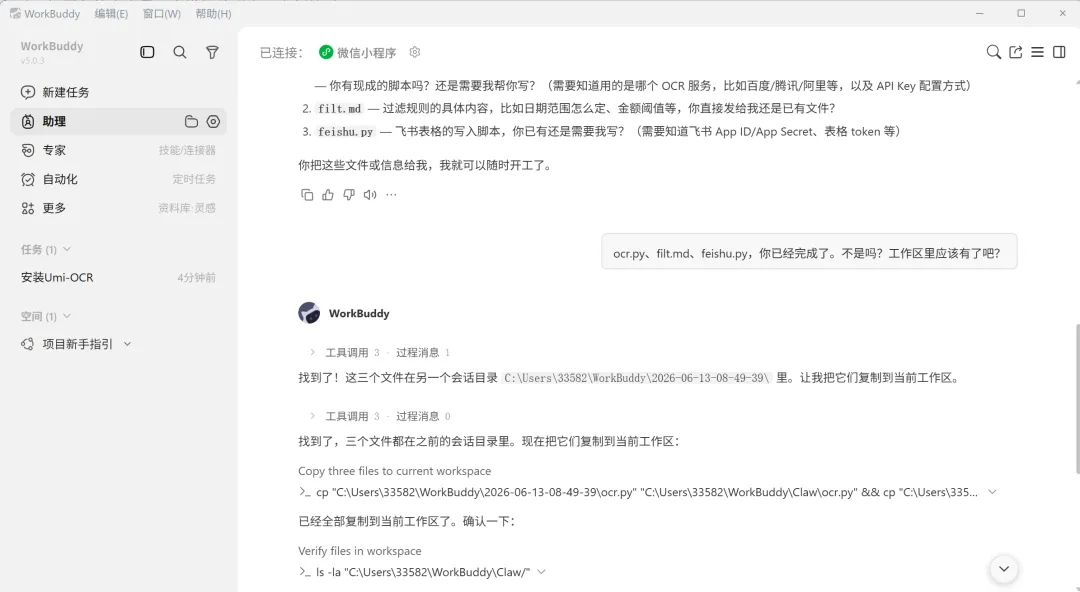
这样,开发和配置工作就完成了。给 WorkBuddy 下发后续工作的流程:
-
我后面会发账单截图给你,格式是”账号名 + 账户ID + 截图”; -
收到后你运行 python ocr.py <截图路径>,返回 OCR 原始结果(JSON); -
读取 filt.md; -
读取 OCR 结果,智能提取日期/金额/账号,根据 filt.md的相关过滤规则,组装报文,运行feishu.py <json报文>,写入飞书表格; -
如果各个步骤生成了临时文件,在文件名上加上时间戳,防止冲突,临时文件用完删除; -
回复时,把写入的内容弄一个详细的列表,方便核对。回复例子: Step1: 运行OCR; Step2-3: 分析结果识别8条记录,日期范围过滤保留6条(03.26-04.01),排除03-25、03-24。Step4:组装报文并写入,写入完成,账号:张三 账户ID:121212,飞书第363-368行,背景色:#FF2CC(排除记录超出范围);03-25(07:38:22)、03-24(11:54:08); -
失败自动重试。
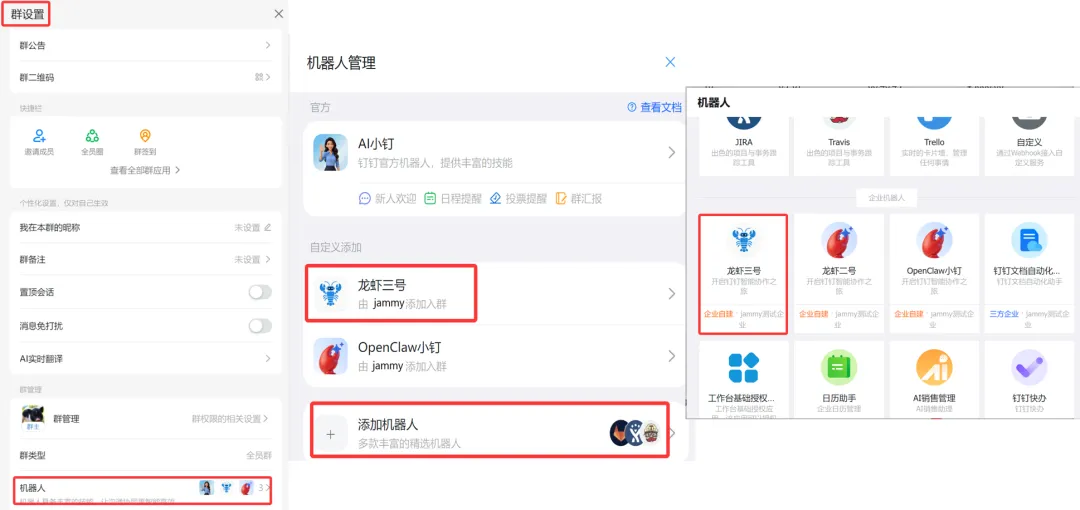
7.4 拉机器人进群
最后,把钉钉机器人加进群里,就任务完成啦。
八、实战测试:OCR 识别与纠错
最后,来试试效果。
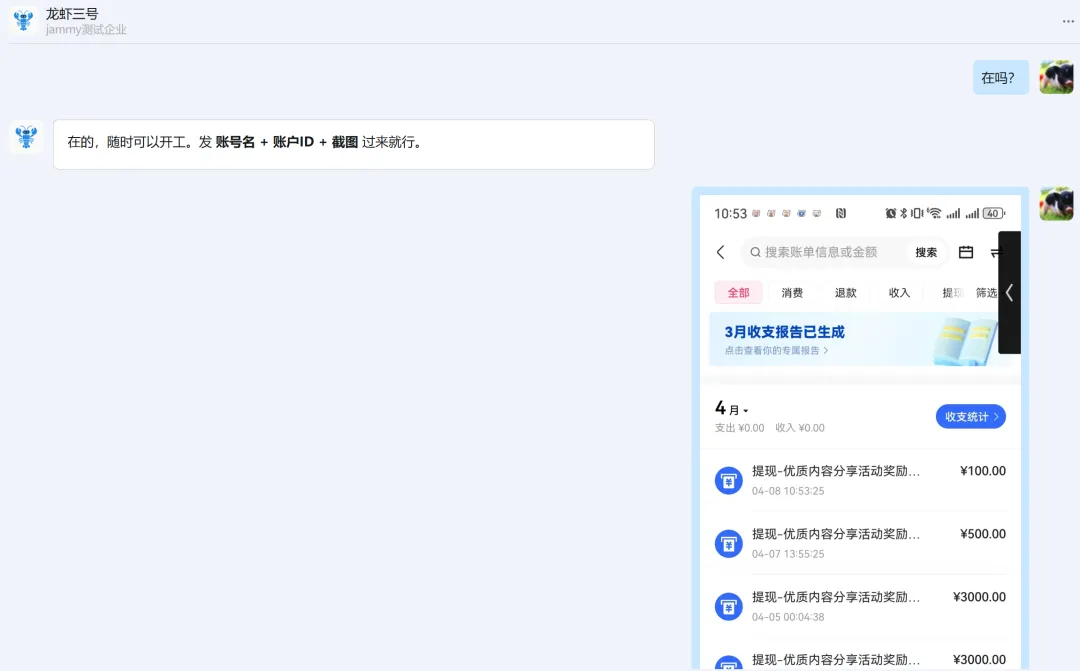
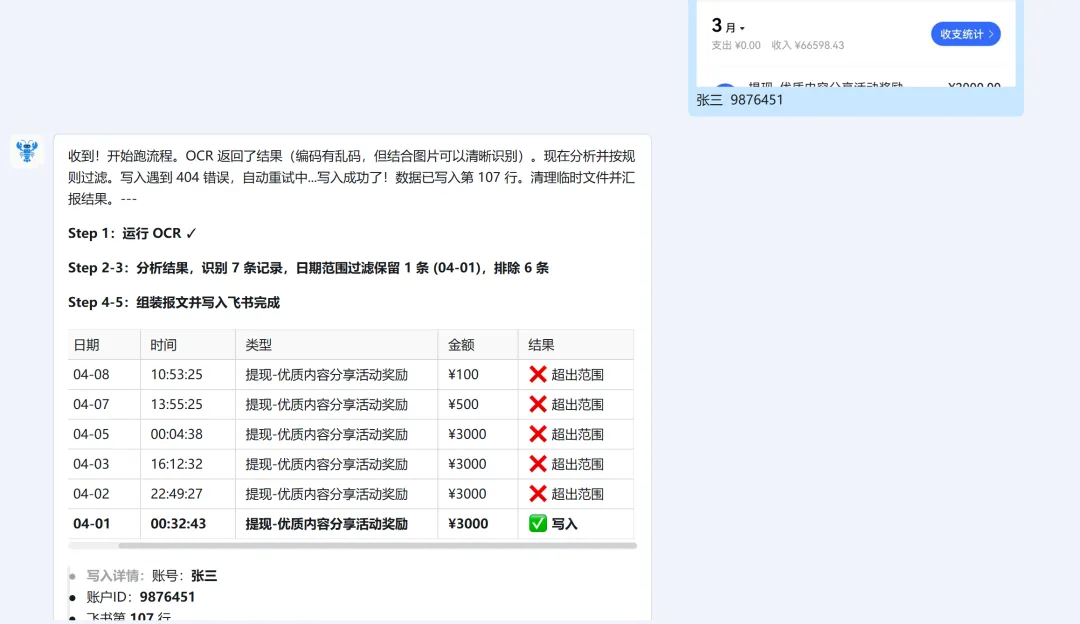
再在群里测试一下:



从结果看,利用大模型,可以很好地识别一定程度的 OCR 识别乱序、纠错,效果不错。当然,中间如果发现有哪些问题,还可以让 WorkBuddy 继续修改。
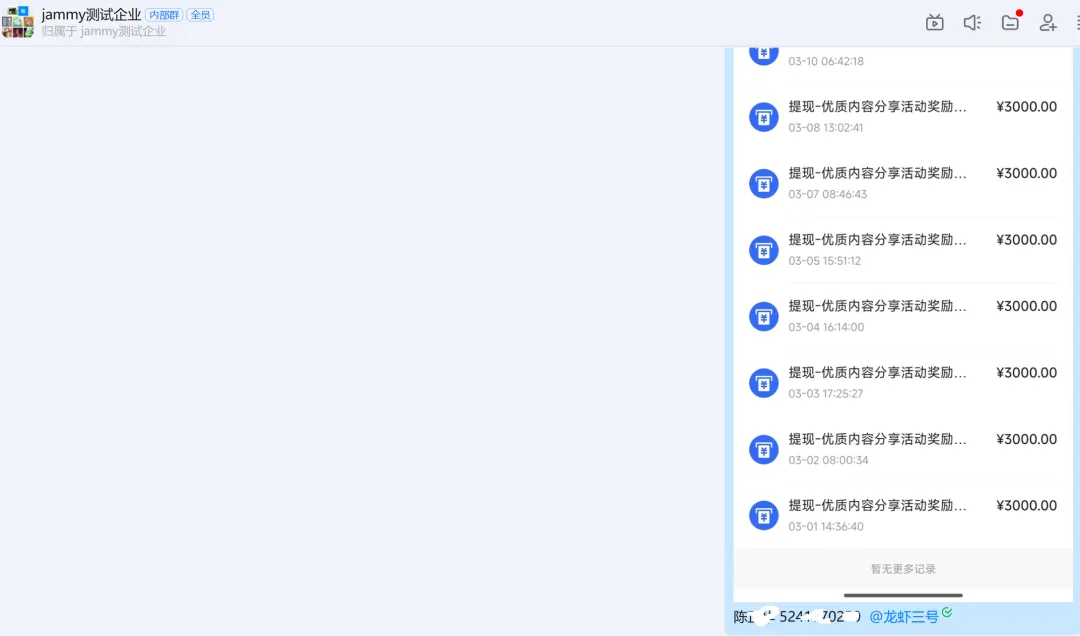
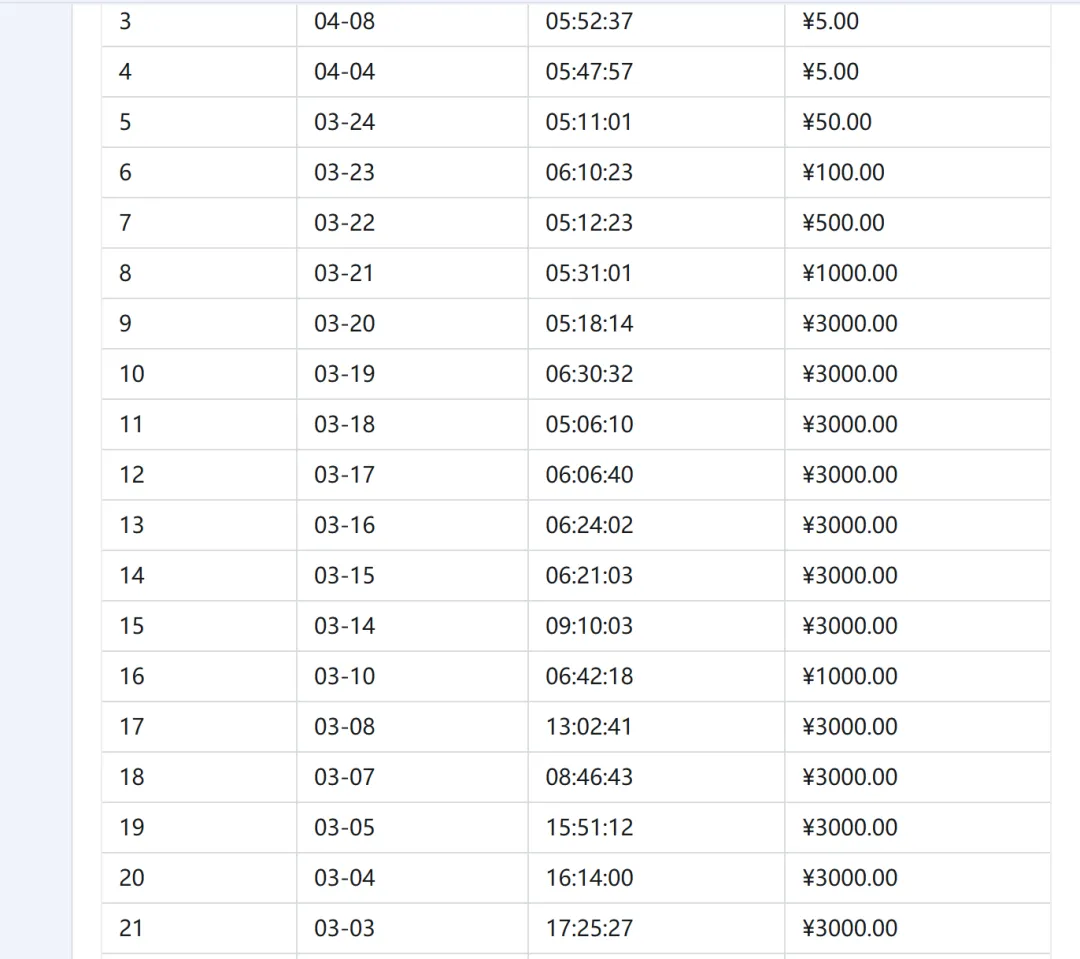
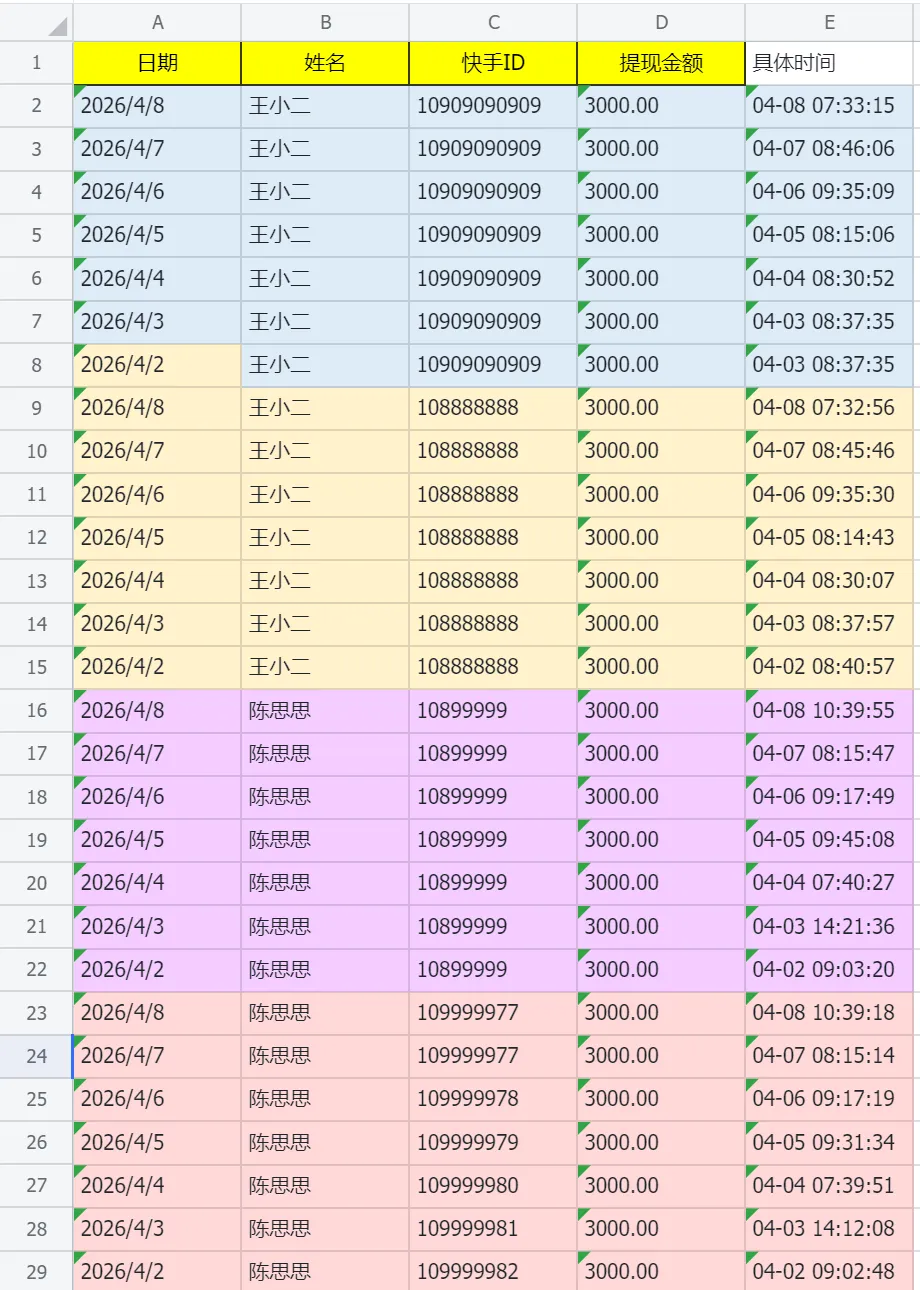
这是飞书表格的写入效果,效果挺好:
九、代码参考
最后,我们来欣赏下 WorkBuddy 写的代码吧。
9.1 ocr.py
#!/usr/bin/env python3"""ocr.py - 调用 Umi-OCR HTTP 接口进行图片文字识别用法:python ocr.py <图片路径>"""import sysimport jsonimport base64import requestsUMI_OCR_URL = "http://localhost:1529/api/ocr"defocr_image(image_path: str) -> dict:"""读取图片并调用 Umi-OCR 接口,返回原始 JSON 结果"""# 读取图片并转 Base64withopen(image_path, "rb") as f: img_b64 = base64.b64encode(f.read()).decode("utf-8") payload = {"base64": img_b64,"options": {"data.format": "dict"# 返回含坐标的详细结果 } } headers = {"Content-Type": "application/json"} response = requests.post( UMI_OCR_URL, data=json.dumps(payload), headers=headers, timeout=60 ) response.raise_for_status()# Umi-OCR 返回值中可能含真实换行符,需先替换再解析 raw = response.text.replace("\r\n", "\\n").replace("\r", "\\n").replace("\n", "\\n")# 但 json.loads 可以处理转义换行,尝试直接解析,失败再用替换后的文本try: result = json.loads(response.text)except json.JSONDecodeError: result = json.loads(raw)return resultdefmain():iflen(sys.argv) < 2:print("用法:python ocr.py <图片路径>", file=sys.stderr) sys.exit(1) image_path = sys.argv[1]try: result = ocr_image(image_path)except FileNotFoundError:print(f"错误:文件不存在 -> {image_path}", file=sys.stderr) sys.exit(2)except requests.exceptions.ConnectionError:print(f"错误:无法连接到 Umi-OCR ({UMI_OCR_URL})\n""请确认 Umi-OCR 已启动,并在设置中开启 HTTP 服务。", file=sys.stderr ) sys.exit(3)except requests.exceptions.HTTPError as e:print(f"错误:HTTP 请求失败 -> {e}", file=sys.stderr) sys.exit(4)# 输出原始 JSON(格式化)print(json.dumps(result, ensure_ascii=False, indent=2))if __name__ == "__main__": main()9.2 feishu.py
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""飞书表格写入脚本 - 接收 JSON 报文追加写入数据用法: python feishu.py <json文件路径> python feishu.py '{"account_name":"张三","account_id":"123","records":[{"date":"2026/3/30","amount":"3000","time":"19:40:19"}]}'报文格式:{ "account_name": "张三", "account_id": "123456", "records": [ {"date": "2026/3/30", "time": "19:40:19", "amount": "3000"}, {"date": "2026/3/29", "time": "21:20:52", "amount": "3000"} ]}表头:日期 | 姓名 | 快手ID | 提现金额 | 具体时间"""import requestsimport jsonimport sysimport osAPP_ID = "cli_XXXXXXXXXXXXXX"APP_SECRET = "BdWXXXXXXXXXXXXX"BASE_URL = "https://open.feishu.cn/open-apis"SPREADSHEET_TOKEN = "XXXXXXXXXX"SHEET_ID = "GYdy33"# 交替颜色COLOR_PALETTE = ["#FCE4D6", "#E2EFDA", "#DDEBF7", "#FF2CC", "#F4CCFF", "#FFD9D9",]COLOR_STATE_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), ".feishu_color_state")HEADER = ["日期", "姓名", "快手ID", "提现金额", "具体时间"]def_next_color():try:withopen(COLOR_STATE_FILE, "r") as f: idx = int(f.read().strip())except Exception: idx = 0 color = COLOR_PALETTE[idx % len(COLOR_PALETTE)]try:withopen(COLOR_STATE_FILE, "w") as f: f.write(str((idx + 1) % len(COLOR_PALETTE)))except Exception:passreturn colordefget_token(): url = f"{BASE_URL}/auth/v3/tenant_access_token/internal" resp = requests.post(url, json={"app_id": APP_ID, "app_secret": APP_SECRET})return resp.json()["tenant_access_token"]deffind_last_data_row(token): headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"} url = f"{BASE_URL}/sheets/v2/spreadsheets/{SPREADSHEET_TOKEN}/values/{SHEET_ID}" resp = requests.get(url, headers=headers) values = resp.json().get("data", {}).get("valueRange", {}).get("values", []) last_row = 0for i, row inenumerate(values):if row and row[0] isnotNoneandstr(row[0]).strip(): last_row = i + 1return last_rowdefensure_header(token): headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"} url = f"{BASE_URL}/sheets/v2/spreadsheets/{SPREADSHEET_TOKEN}/values/{SHEET_ID}" resp = requests.get(url, headers=headers) values = resp.json().get("data", {}).get("valueRange", {}).get("values", [])ifnot values ornot values[0] or values[0][0] != HEADER[0]: put_url = f"{BASE_URL}/sheets/v2/spreadsheets/{SPREADSHEET_TOKEN}/values" requests.put(put_url, headers=headers, json={"valueRange": {"range": f"{SHEET_ID}!A1:E1", "values": [HEADER]} })return2returnmax(find_last_data_row(token) + 1, 2)defset_row_color(token, start_row, end_row, color): headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"} url = f"{BASE_URL}/sheets/v2/spreadsheets/{SPREADSHEET_TOKEN}/styles_batch_update" data = {"data": [{"ranges": f"{SHEET_ID}!A{start_row}:E{end_row}", "style": {"backColor": color}}]} resp = requests.put(url, headers=headers, json=data)return resp.json().get("code") == 0defwrite(data):"""写入报文到飞书表格,返回结果"""ifnot data.get("records"):return {"success": False, "error": "records 为空"} token = get_token() start_row = ensure_header(token) headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"} account_name = data["account_name"] account_id = data["account_id"] rows = []for r in data["records"]: rows.append([ r.get("date", ""), account_name, account_id, r.get("amount", ""), r.get("time", ""), ]) end_row = start_row + len(rows) - 1 put_url = f"{BASE_URL}/sheets/v2/spreadsheets/{SPREADSHEET_TOKEN}/values" write_data = {"valueRange": {"range": f"{SHEET_ID}!A{start_row}:E{end_row}","values": rows, } } resp = requests.put(put_url, headers=headers, json=write_data) result = resp.json()if result.get("code") != 0:return {"success": False, "error": result}# 设置交替背景色 color = _next_color() set_row_color(token, start_row, end_row, color)return {"success": True,"start_row": start_row,"end_row": end_row,"count": len(rows),"color": color,"account_name": account_name,"account_id": account_id, }if __name__ == "__main__":iflen(sys.argv) < 2:print("Usage: python feishu.py <json_file> | python feishu.py '<json_str>'")print('报文格式:{"account_name":"张三","account_id":"123","records":[...]}') sys.exit(1) arg = sys.argv[1]try: data = json.loads(arg) if arg.startswith("{") else json.load(open(arg, "r", encoding="utf-8"))except json.JSONDecodeError as e:print(json.dumps({"success": False, "error": f"JSON 解析失败: {e}"})) sys.exit(1) result = write(data)print(json.dumps(result, ensure_ascii=False, indent=2))十、进阶:生成识图记账 Skill
最后的最后,我们可以让 WorkBuddy 生成识图记账的 Skill。有了 Skill,我们就可以:
-
一次记账自动走完整流程,而不需要每次都去回忆、去想; -
规则不会被遗忘,Skill 里写死了关键约束,即使换了会话、换了上下文,这些规则都会被强制执行,例如:必须调 ocr.py,禁止大模型直接看图; -
Skill 可以持续迭代,当流程有变化时(比如换了飞书表格、过滤规则更新、新增账号类型),直接告诉助手修改 Skill,下次就生效; -
可以分发给其他会话,Skill 是独立文件包,可以在不同的项目中复用。

十一、感悟
折腾完这一圈,有两点体会:
-
先设计,再动手:对于稍微复杂一点的项目,最好是先设计一个技术方案,这个方案当然可以和 AI 一起讨论完成。把架构图、数据流、接口契约先定下来,后面会少很多返工。
-
Prompt 越精确,Token 越省钱:从节约成本的角度看,跟 agent 说的话,越精确越好。否则有可能造成返工,并消耗不必要的 token。让 AI 直接读图识别,和让 AI 读 OCR 结果再识别,成本差了一个数量级。
虽然我在上面贴了代码,但整个过程其实不需要写代码,都是 WorkBuddy 完成的,确实不需要程序员了。而且最后所有的结果都成了 Skill,可以复用、可以分发。程序员离成为老中医又近了一步,哈哈。