 夜雨聆风
夜雨聆风





AI Agent 开始改造开发文档
一句话总结:AI Agent 最实用的落点之一,不是替你写应用,而是把沉睡在文档和仓库里的知识变成可查询、可组合、可自动更新的数据层。
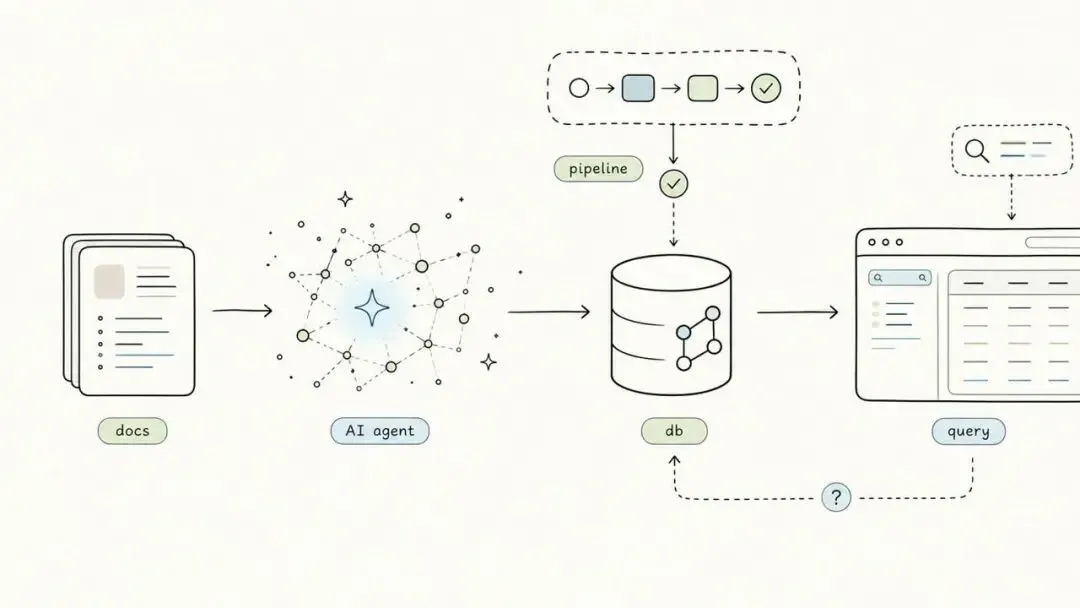
Simon Willison 做了一个很小但很有代表性的实验:把 MDN 的浏览器兼容性数据转换成 SQLite 数据库,再通过 GitHub 托管,让浏览器端工具可以直接查询。
这件事本身不复杂,却很能说明 AI Agent 在开发者工具里的一个长期方向:
它不是只在编辑器里补全代码,而是在把知识资产重新整理成机器可用的形态。
过去的问题:文档对人友好,对工具不够友好
开发者每天都在查文档。
浏览器兼容性、API 变更、运行时限制、框架版本差异,这些信息通常分散在页面、仓库、JSON 文件、issue 和 release note 里。
人可以慢慢读,工具却很难稳定使用。
当 AI Agent 要帮你判断“这个 Web API 能不能在目标浏览器里用”“某个特性是否需要 fallback”“这个实现会不会影响旧设备”,它需要的不是一篇漂亮网页,而是可查询、结构化、版本化的数据。
这就是把文档转成数据库的价值。
这类工作为什么适合 Agent
在这个实验里,有两个环节值得注意。
第一,Claude Code 生成了把浏览器兼容性数据转换为 SQLite 的脚本。
第二,Codex Desktop 生成了 GitHub Actions workflow,用来构建数据库并推送到一个单独分支,方便通过 GitHub CDN 访问。
这不是“AI 写了一个炫技应用”。它更像一种新的工程杂活处理方式:
-
读懂已有开源数据结构; -
写转换脚本; -
设计自动构建流程; -
处理托管和 CORS 这类部署细节; -
最后产出一个其他工具可以直接消费的数据资产。
这正是很多团队缺人做、但做完很有复利的工作。
真正的价值是知识层的可编程化
当文档变成数据库,它就不再只是“查资料”。
它可以进入更多工作流:
-
在 PR 检查里提示兼容性风险; -
在设计系统里标注某个 CSS 特性的支持边界; -
在低代码或 AI 生成页面时自动约束可用能力; -
在浏览器端用 Datasette Lite 直接探索数据; -
被 MCP 或其他工具接口包装,成为 Agent 的外部知识源。
这类能力会让开发者工具从“回答问题”,进一步走向“约束生成”。
对产品团队的启发
很多公司内部也有类似的知识资产:API 文档、埋点字典、客服知识库、权限矩阵、合规清单、设计规范、历史事故复盘。
它们看起来像文档,实际上应该变成工具能读的数据层。
最务实的做法不是先上一个宏大的知识管理平台,而是选一个高频问题,做一个小型可查询数据库:
-
数据从哪里来; -
多久更新一次; -
用什么脚本转换; -
如何暴露给内部 Agent; -
输出结果由谁负责校验。
只要跑通一个闭环,后续就可以复制到更多知识域。
结尾
AI Agent 的生产力,不只来自模型本身,也来自它能调用什么样的知识底座。
把文档变成可查询的数据,是很小的一步,却可能是很多团队真正用好 Agent 的第一步。
参考资料:Simon Willison — simonw/browser-compat-db