夜雨聆风
夜雨聆风
前言
2026年初,OpenClaw以一种近乎“野蛮生长”的姿态席卷了开发者社区。这个由奥地利开发者Peter Steinberger创建的开源AI Agent框架,从最初的周末黑客项目“Clawdbot”,经历了与Anthropic的商标纠纷、两次更名,最终以“OpenClaw”之名在短短两个月内斩获超过24万GitHub Star,成为2026年开源领域最受瞩目的项目之一。彭博社用“cult-like status”(近乎狂热的追捧)来描述它在中国市场的扩张速度——帽子、安装派对、云托管方案和各种山寨品层出不穷。
但大多数团队对OpenClaw的使用还停留在“聊天机器人”阶段——接入一个消息渠道,配一个LLM,回答几个问题。这远远没有触及它的能力边界。从架构本质上看,OpenClaw不是一个ChatGPT的外壳,而是一个本地优先的Agent运行时,具备会话管理、工具调度、多Agent编排和持久化记忆等完整能力。本文将聚焦OpenClaw在研发团队中的高级玩法,从多Agent协同、自定义Skill开发、自动化工作流编排到安全加固,结合实际场景给出一套可落地的实践路径。
目录
一、OpenClaw核心架构速览
二、高级玩法一:多Agent协同架构
三、高级玩法二:自定义Skill开发与治理
四、高级玩法三:自动化工作流编排
五、高级玩法四:安全加固与沙箱隔离
六、研发团队落地实践路径
七、总结
一、OpenClaw核心架构速览
在深入高级玩法之前,有必要先厘清OpenClaw的架构本质。很多人误以为它只是“LLM加了个消息转发层”,这种理解会严重限制你对它的使用方式。OpenClaw的核心是一个始终运行的Gateway进程,它不仅仅做消息转发,更承担了会话路由、Agent生命周期管理、工具权限调度和事件总线的全部职责。
Gateway默认监听18789端口,通过WebSocket协议与外部客户端、Agent节点和消息渠道进行全双工通信。当一条消息从WhatsApp、Slack或Telegram进入时,Gateway首先根据Bindings规则确定目标Agent,然后在该Agent的Session上下文中调用配置的LLM(支持Anthropic Claude、OpenAI GPT系列、DeepSeek以及通过Ollama/vLLM运行的本地模型),按需执行工具或Skill调用,最后将响应结果沿原消息渠道返回。
此外,OpenClaw还提供了一个独立的Canvas服务(默认端口18793),这是一个Agent驱动的可视化工作空间。Canvas与Gateway进程分离,即使Canvas崩溃也不会影响Gateway的正常运行,这种隔离设计体现了其在架构可靠性上的考量。
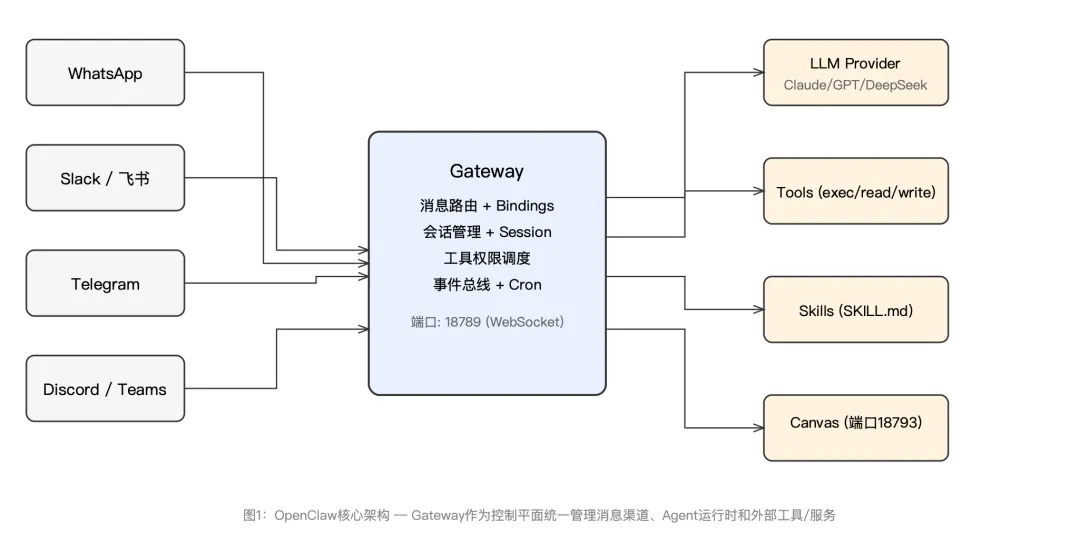
理解这个架构后,你会意识到Gateway不只是一个“消息中转站”,它是整个系统的信任边界。所有进出系统的数据、所有工具调用的权限判定、所有Agent之间的隔离策略,都以Gateway为锚点。后面要讲的所有高级玩法,本质上都是在这个信任边界内外做文章。
二、高级玩法一:多Agent协同架构
单Agent场景下,OpenClaw就是一个增强版的AI助手。但当你的研发团队需要处理不同职责——比如一个Agent负责代码审查,一个负责文档生成,一个负责CI/CD监控,一个负责安全扫描——单Agent模式就捉襟见肘了。所有Skill挤在一个系统提示词里,上下文窗口被迅速消耗,权限边界也无法细分。
OpenClaw在2026年2月的版本(2026.2.17)中引入了确定性子Agent派生和结构化Agent间通信机制,使多Agent协同成为一等公民。其核心设计思路非常清晰:每个Agent拥有完全独立的三大件——Workspace(包含SOUL.md人格设定、AGENTS.md行为指令、USER.md用户画像,以及本地Skill目录)、agentDir(认证配置、模型注册、Per-Agent设置)和Session存储(聊天历史和路由状态)。
多Agent路由的配置通过openclaw.json中的agents.list和bindings字段实现。bindings决定了哪个Channel的消息路由到哪个Agent,支持按Channel类型、AccountId、Peer ID甚至Discord Guild ID进行精细化路由。这意味着你可以让同一个Gateway上的不同Agent各自“守住”不同的渠道入口。
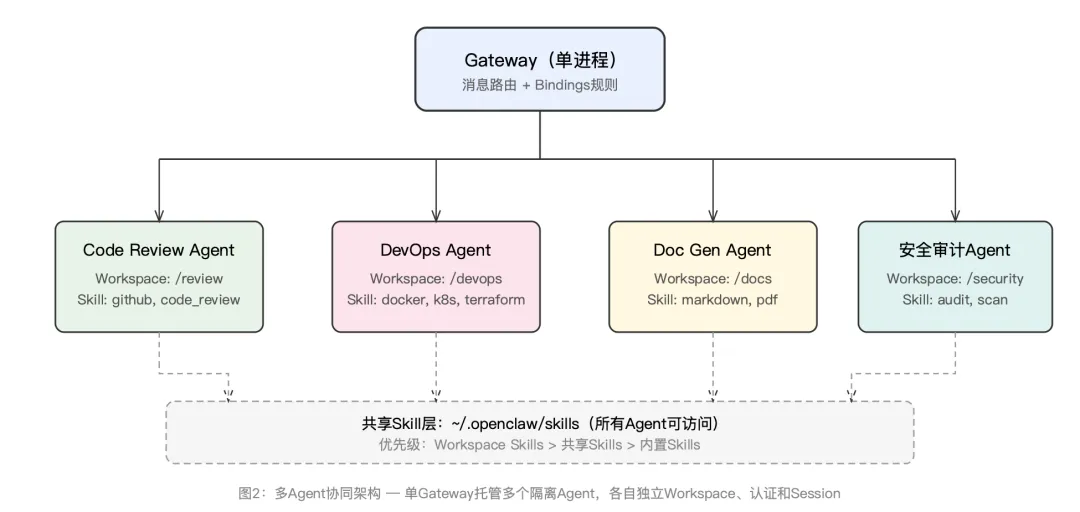
在实际研发团队中,推荐的做法是按职责划分Agent,而非按人划分。比如:Code Review Agent绑定到GitHub Webhook渠道,DevOps Agent绑定到Slack的#ops频道,文档Agent绑定到飞书的技术文档群。每个Agent只加载自己需要的Skill,这既降低了系统提示词的Token开销(每个Skill在系统提示词中占用约97字符加上描述长度),也遵循了最小权限原则。
需要特别注意的是:不同Agent之间的认证配置(auth-profiles.json)是完全隔离的。这是OpenClaw的设计意图——绝不能跨Agent复用agentDir目录,否则会导致认证冲突和Session混乱。如果确实有共享凭据的需求,正确的方式是将auth-profiles.json手动复制到目标Agent的agentDir下,并做好版本同步。
对于更复杂的场景,可以参考学术界提出的“黑板架构”(Blackboard Architecture):多个Agent通过共享的数据存储(比如一个网络可访问的文件或数据库)进行间接通信。OpenClaw可以通过自定义Tool来读写这个共享存储,而不需要Agent之间直接发送消息。这种松耦合设计在实践中更稳定。
三、高级玩法二:自定义Skill开发与治理
OpenClaw的Skill系统是其扩展能力的核心所在。每个Skill本质上是一个包含SKILL.md文件的目录,SKILL.md中用YAML frontmatter定义元数据(名称、描述、依赖的系统工具和环境变量),用Markdown描述Agent应如何使用该Skill的行为指令。Gateway在会话启动时会快照当前所有“合格”的Skill列表,并在后续Turn中复用这个快照,只有在新会话或触发Skill Watcher热重载时才会刷新。
截至2026年3月,ClawHub(OpenClaw的官方Skill注册中心)上已有超过5400个社区贡献的Skill,覆盖了从GitHub操作、Slack消息、Docker部署到智能家居控制的各种场景。但社区Skill的安全性一直是个严峻的隐患——2026年2月,安全研究人员在ClawHub上审计了2857个Skill,发现其中341个存在恶意行为,手法包括提示注入、工具投毒、隐蔽数据外泄和恶意脚本下载。虽然ClawHub已接入VirusTotal扫描,但安全审查的覆盖面仍然有限。
因此,对于研发团队而言,自建Skill + 白名单管控是唯一可靠的策略。具体分三步走:
第一步,创建Skill目录结构。每个Skill需要一个独立目录,内含一个SKILL.md文件,可以附带辅助脚本、参考文档或模板:
mkdir-p ~/.openclaw/workspace/skills/team-code-reviewtouch ~/.openclaw/workspace/skills/team-code-review/SKILL.md# 可选:放入团队编码规范等参考文件cp coding-standards.md ~/.openclaw/workspace/skills/team-code-review/第二步,编写SKILL.md。YAML frontmatter声明Skill的名称、描述和依赖项,Markdown正文定义Agent的行为逻辑:
---name: team-code-reviewdescription: 基于团队编码规范的自动化代码审查,支持PR级和文件级Reviewmetadata: openclaw: requires: bins: - git - gh env: - GITHUB_TOKEN primaryEnv: GITHUB_TOKEN---# 使用场景当用户要求Review代码、审查PR或检查代码质量时,使用此Skill。# 执行步骤1. 通过gh CLI获取指定PR的diff内容2. 按照coding-standards.md中的团队规范逐项检查3. 生成结构化Review报告:问题分类(Critical/Warning/Info)+ 行号 + 修改建议4. 如发现安全相关问题(SQL注入、硬编码密钥等),自动标记为Critical5. 将报告摘要通过message工具推送到#code-review频道# 约束- 不自动合并或关闭PR,只提供Review意见- 单次Review的diff行数超过500行时,提示用户拆分PR第三步,启用白名单模式。在openclaw.json中,通过allowBundled配置项只允许指定的内置Skill加载,同时通过extraDirs引入团队共享的Skill目录:
{ "skills":{ "allowBundled":["github","docker","memory","web_search"], "load":{ "extraDirs":["/shared/team-skills"] } }}这里有个容易被忽视的默认行为:OpenClaw的内置Skill是“有工具就激活”的。也就是说,只要你的系统上装了git,内置的GitHub Skill就会自动加载到Agent的系统提示词中。对个人用户来说这是便利,但在团队环境中意味着Agent可能加载了你完全不知道的Skill。白名单模式从根本上解决了这个问题。
另外值得一提的是,OpenClaw也支持“让Agent帮你创建Skill”的能力——通过内置的advanced-skill-creator Skill,你可以用自然语言描述需求,让Agent自动生成Skill目录结构和SKILL.md文件。但自动生成的Skill通常过于“乐观”,缺少边界条件处理和错误容错,拿来做初始框架还行,上线前务必人工Review和收紧。
四、高级玩法三:自动化工作流编排
OpenClaw从“聊天机器人”变成“基础设施”的关键拐点,是它的Cron调度 + Message推送机制。这两个能力组合在一起,使Agent可以在无人值守的情况下执行定时任务,并将结果主动推送到指定的消息渠道。这和传统的CI/CD系统发通知不同——OpenClaw的任务执行本身就是Agent驱动的,它可以在执行过程中进行判断、分支和自适应调整。
典型的工作流模式遵循一个四层结构:触发 → 编排 → 执行 → 投递。
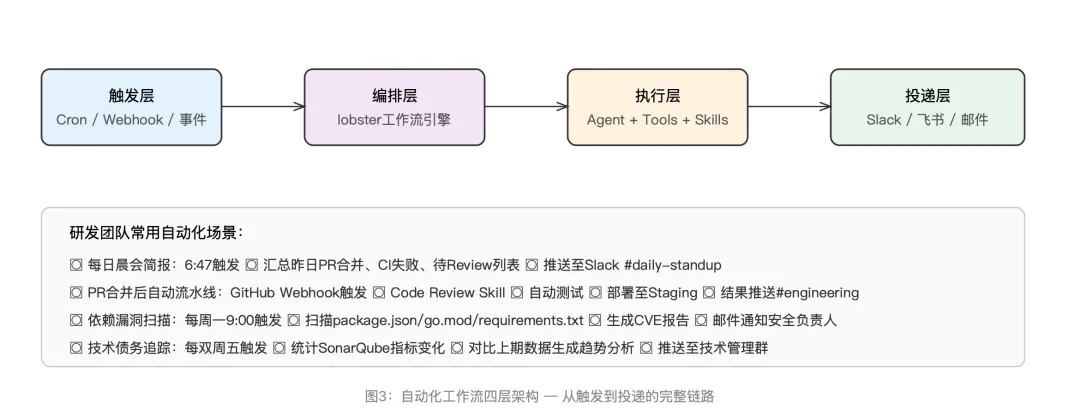
其中,lobster是OpenClaw内置的轻量级工作流引擎,支持定义多步骤流程,每一步可以嵌入LLM推理(通过llm_task工具)。如果你不需要复杂的工作流编排,单独使用Cron + 自然语言指令就足够覆盖大部分场景了。
有一个社区广受好评的实践是“每日晨会简报”:每天早上固定时间自动触发,Agent汇总过去24小时的GitHub活动(PR状态、Issue变更、CI结果)、团队日历中的今日安排、以及邮件中需要跟进的事项,生成一份结构化简报推送到团队频道。这一个自动化就替代了开发者每天早上打开五六个应用逐个检查的习惯。
不过这里有一个实战中反复验证的经验教训:不要让自动化工作流直接操作生产环境。OpenClaw的exec工具可以执行任意Shell命令,如果Agent配置了过高的权限,一次提示注入或Skill逻辑错误就可能导致灾难性后果。正确的做法是,自动化工作流中凡涉及写操作(部署、数据库变更、配置修改),一律通过Human-in-the-Loop机制插入人工审批节点——Agent准备好操作指令和影响评估,推送给负责人确认后再执行。
五、高级玩法四:安全加固与沙箱隔离
OpenClaw的安全问题不是“理论上可能发生”,而是“已经在发生”。Pillar Security团队搭建的蜜罐实验显示,暴露在公网上的Gateway在数分钟内就会遭到针对性的协议层攻击——攻击者甚至跳过了提示注入这种“文明”手法,直接通过WebSocket API在TCP 18789端口上发送JSON-RPC载荷来执行工具调用和读取文件。安全研究员Mav Levin发现了一个“一键RCE”漏洞(CVE-2026-25253),恶意链接通过WebSocket握手就能泄露Token并执行任意Shell命令。
对研发团队而言,安全加固至少要覆盖四个层面:
网络隔离:Gateway默认必须绑定到loopback地址(配置gateway.bind: “loopback”),远程访问通过SSH隧道或Tailscale Serve实现。绝不要将18789端口直接暴露到公网——即使你配置了认证,协议层漏洞也可能被绕过。如果使用反向代理,建议参考Cloudflare WAF规则进行请求头校验。
工具分级管控:OpenClaw的25个内置工具按风险等级明确分为三档。高风险的exec、database、email只在充分评估后启用,并限定只有特定Agent可以调用;中风险的write、github、slack按需开启,配合审计日志监控使用频率;低风险的read、search、web_search、memory可以默认开启。在agents.list中可以为每个Agent配置独立的tools字段来拒绝特定工具。
Docker沙箱:对于不受信任的社区Skill或需要高权限操作的Agent,应启用Docker沙箱模式。沙箱限制了Agent的文件系统访问范围、网络连通性和系统调用能力。沙箱内的Agent无法触及宿主机上的敏感文件(如SSH密钥、其他Agent的凭据),即使Skill中存在恶意代码,影响也被限制在容器边界内。代价是某些需要网络访问的Skill可能无法正常工作——但这恰恰是安全设计的目的:强制你显式声明Agent需要什么能力。
多Gateway分层部署:当团队的Agent数量增长到一定规模后,单Gateway的“所有Agent共享一个进程和一套环境变量”模式会变成安全负债——你的代码审查Agent和客户咨询Agent共享同一份API Key,一个被攻破意味着全部泄露。正确的做法是按信任等级将Agent拆分到独立的Gateway进程中:
# 研发工具Gateway(内部信任度高)OPENCLAW_CONFIG_PATH=~/.openclaw/devtools/openclaw.json \OPENCLAW_STATE_DIR=~/.openclaw/devtools/state \openclaw start# 对外服务Gateway(信任度低,严格沙箱)OPENCLAW_CONFIG_PATH=~/.openclaw/public/openclaw.json \OPENCLAW_STATE_DIR=~/.openclaw/public/state \openclaw start每个Gateway拥有独立的配置文件、独立的密钥集合和独立的状态目录。即使某个低信任度的Gateway被攻破,攻击者拿到的也只是该层级的密钥,无法横向移动到其他Gateway。
最后,OpenClaw提供了内置的安全审计工具:openclaw security audit(只读扫描配置和文件权限)、openclaw security audit --deep(加入运行中Gateway的WebSocket探测)和openclaw security audit --fix(自动修复可安全修复的问题,如收紧文件权限、切换groupPolicy为白名单模式)。建议将--deep审计纳入团队的定期安全巡检流程,至少每两周执行一次。
六、研发团队落地实践路径
有了上面的技术储备,下面给出一条经过验证的渐进式落地路径。核心原则是先跑通、再扩展、最后收紧——不要试图一步到位地搭建完美架构。
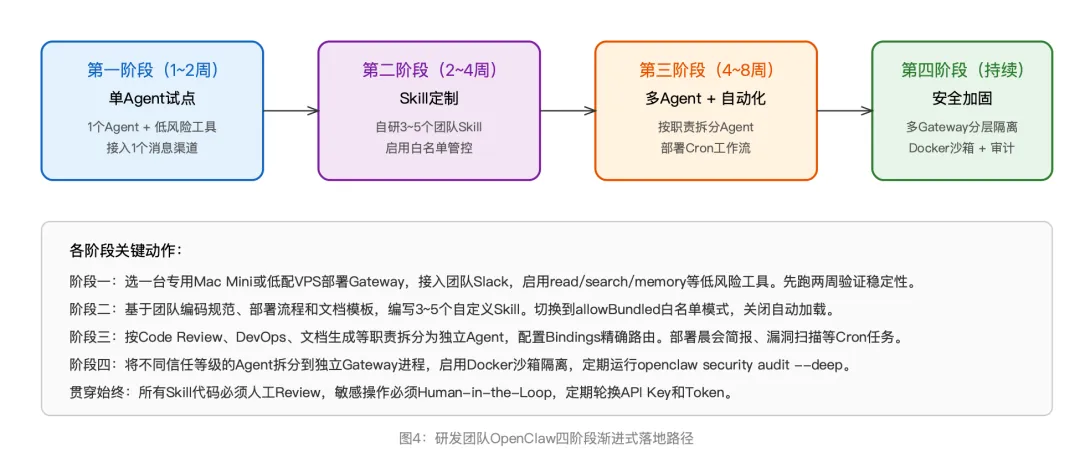
关于部署环境的选择,实际经验告诉我们:起步务必用专用机器,不要在日常开发机上跑Gateway。原因很直白——OpenClaw需要系统级的文件读写和命令执行权限,如果Gateway跑在你的工作笔记本上,一个Skill漏洞就可能触及SSH密钥、源代码仓库和个人数据。推荐的起步配置是一台Mac Mini(隐私优先、本地访问简单)或一台低配云服务器($12/月的DigitalOcean一键部署方案自带容器级隔离和安全默认配置)。
关于模型选择,团队场景下建议优先使用Anthropic Claude(特别是Claude Sonnet系列,在工具调用和长上下文推理上表现稳定),OpenAI的GPT-5.4快速模式也已在最新版本中获得原生支持。如果有数据合规要求不允许调用外部API,可以通过Ollama或vLLM插件接入本地部署的开源模型,但工具调用的准确性会有所下降,需要在Skill设计中做好容错处理。
七、总结
OpenClaw的本质不是一个聊天机器人,而是一个本地优先的Agent运行时。理解这一点,才能跳出“接个Slack机器人回答问题”的初级阶段,进入真正的工程化应用。
对研发团队而言,它的高级玩法可以归纳为四个方向:用多Agent协同解决职责分离和权限隔离问题,用自定义Skill + 白名单管控实现团队知识的可控沉淀,用Cron + lobster工作流取代重复性人工操作,用多Gateway分层部署和Docker沙箱建立安全纵深防御。
但也必须清醒地认识到,OpenClaw目前仍处于极速迭代期。创始人Peter Steinberger已于2026年2月加入OpenAI,项目移交给了独立的开源基金会管理。社区活跃度极高但治理尚不成熟,Skill供应链攻击、提示注入和凭据泄露都是已经被实际利用的威胁。中国政府在2026年3月已限制政府机关和国企在办公电脑上运行OpenClaw,这不是过度反应,而是对其系统级权限访问模式的合理警惕。
在享受OpenClaw带来的自动化红利时,牢记一个原则:永远不要让Agent拥有超出其职责范围的权限。先小范围试点、再逐步扩展、持续收紧安全边界——这才是研发团队落地AI Agent的正确姿势。
2026年是AI Agent从实验走向工程的一年。OpenClaw给了研发团队一个足够好的起点,但路还很长,走稳比走快更重要。
作者简介:TechVision大咖圈,专注于企业级技术架构与CTO/CIO决策支持,持续输出一线工程实践经验。欢迎关注同名微信公众号和CSDN博客。