 夜雨聆风
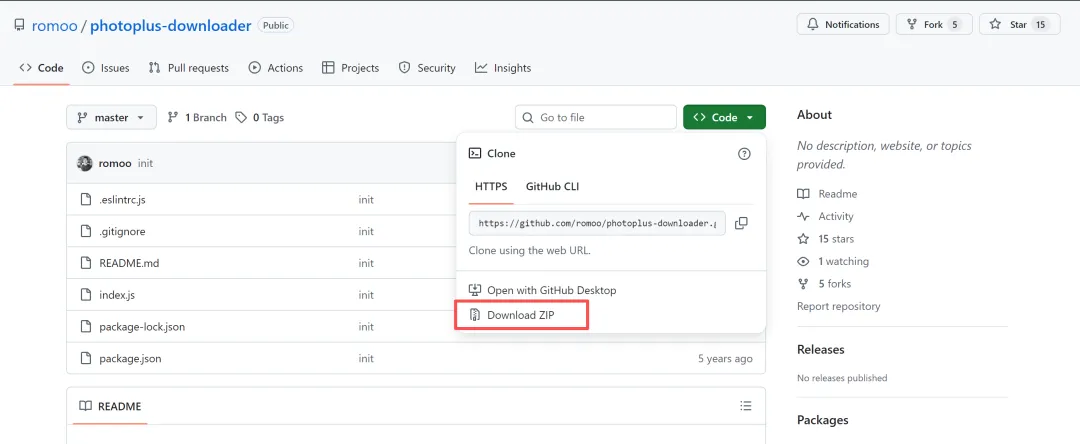
夜雨聆风选择code按钮下的download zip
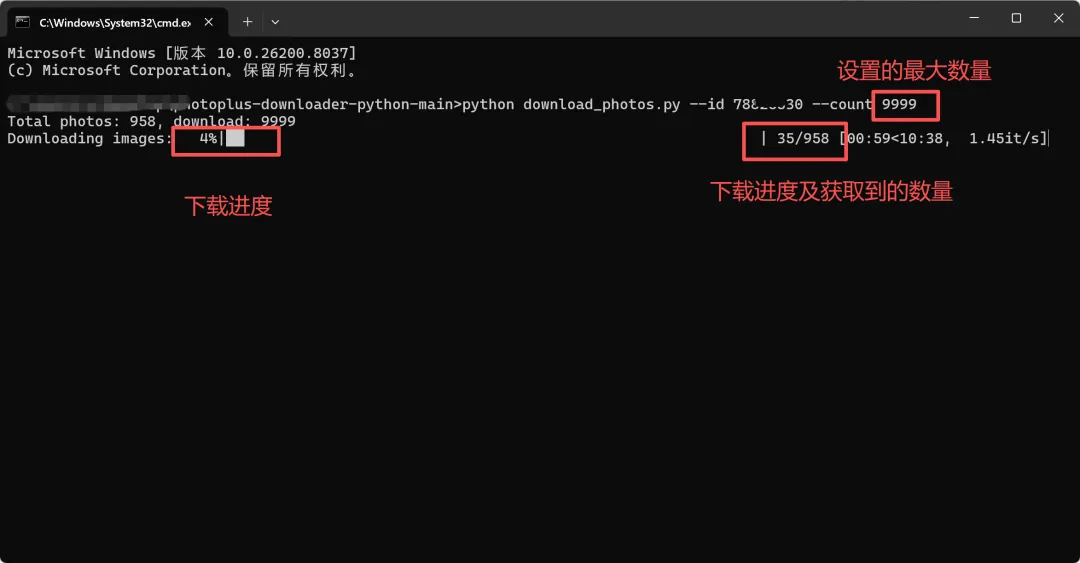
之后输入执行的代码:
python download_photos.py --id 12345678 --count 9999
import osimport hashlibimport requestsimport argparseimport timeimport refrom tqdm import tqdmfrom concurrent.futures import ThreadPoolExecutor, as_completedSALT = 'laxiaoheiwu'COUNT = 9999def obj_key_sort(obj):sorted_keys = sorted(obj.keys())new_obj = []for key in sorted_keys:if obj[key] is not None:value = str(obj[key])new_obj.append(f"{key}={value}")return '&'.join(new_obj)def sanitize_filename(filename):return re.sub(r'[<>:"/\\|?*]', '_', filename)def download_image(url, dir):filename = url.split('/')[-1].split('#')[0].split('?')[0]filename = sanitize_filename(filename)image_path = os.path.join(dir, filename)if os.path.exists(image_path):returnresponse = requests.get(url, stream=True)if response.status_code == 200:with open(image_path, 'wb') as file:for chunk in response.iter_content(1024):file.write(chunk)def download_all_images(list, dir):with ThreadPoolExecutor(max_workers=10) as executor:futures = []for item in list:url = f"https:{item['origin_img']}"futures.append(executor.submit(download_image, url, dir))for future in tqdm(as_completed(futures), total=len(futures), desc="Downloading images"):future.result()def get_all_images(id, count):t = int(time.time() * 1000) # Current timestamp in millisecondsdir = f"./dist/{id}"data = {"activityNo": id,"isNew": False,"count": count,"page": 1,"ppSign": "live","picUpIndex": "","_t": t}data_sort = obj_key_sort(data)sign = hashlib.md5((data_sort + SALT).encode()).hexdigest()params = {**data,"_s": sign,"ppSign": "live","picUpIndex": "",}response = requests.get('https://photoplus网址/pic/pics', params=params)result = response.json()['result']print(f"Total photos: {result['pics_total']}, download: {count}")os.makedirs(dir, exist_ok=True)download_all_images(result['pics_array'], dir)if __name__ == "__main__":parser = argparse.ArgumentParser(description="Download photos from PhotoPlus")parser.add_argument("--id", type=int, help="PhotoPlus ID (e.g., 87654321)", required=True)parser.add_argument("--count", type=int, default=COUNT, help="Number of photos to download")args = parser.parse_args()if args.id:get_all_images(args.id, args.count)else:print("Wrong ID")
脚本仅用于个人合法用途,请勿滥用。
如果遇到下载失败,可能是相册已过期或 ID 不正确。
感谢原作者的无私分享,此备份只为方便日后查阅。
