 夜雨聆风
夜雨聆风NVIDIA 说它是 OpenClaw 最强搭档,但你现在就能免费用上
GTC 2026 上,NVIDIA 发布了 Nemotron 3 Super。
官方说法是 OpenClaw 搭配部署最佳模型之一,PinchBench 这个专门测 OpenClaw AI 代理性能的基准测试里,它拿了 85.6%,同级开源模型里最高。
听起来很猛。然后你看到参数规模——1200 亿。
然后这件事就跟你没关系了。
120B 的模型,就算用了再聪明的架构优化,要在本地电脑上跑起来,对绝大多数人来说基本不现实。发布会上的东西,看个热闹,散了。
但有一个路子,很多人不知道。

先说说这个模型为什么值得关注,不只是参数大。
Nemotron 3 Super 用的是混合 Mamba-Transformer 加 MoE 的架构。MoE 是 Mixture of Experts,就是模型里有很多"专家模块",每次推理只调用其中一部分,不是把 1200 亿参数全跑一遍。
实际推理时只激活 120 亿参数。所以它的速度比你想象的快得多。
NVIDIA 给了一组数据:8k 输入、16k 输出的场景下,推理吞吐量是 GPT-OSS-120B 的 2.2 倍,是 Qwen3.5-122B 的 7.5 倍。还支持最高 100 万 Token 的上下文窗口,这对 OpenClaw 这类需要长上下文记忆的 Agent 来说很关键——很多 Agent 任务跑到一半就因为上下文装不下而出问题,这个窗口基本能解决这类麻烦。
而且完全开源,NVIDIA Open License,模型权重、数据集、训练方法都公开,不是那种"开源"但商用要付费的。

好,回到你怎么用这件事。
现在通过 OpenRouter 可以拿到 Nemotron 3 Super 的免费 API,不需要任何本地硬件,什么配置的电脑都行。
OpenRouter 是一个整合多家模型的 API 平台,一个 Key 可以切换 OpenAI、Anthropic、Google、NVIDIA 等一堆厂商的模型。
免费版有几个限制先说清楚:每天最多 50 次调用,每分钟最多 20 次请求,失败的请求也算进额度,高峰期可能排队。另外免费版的输入输出会被记录用来优化服务,所以别把私人信息或者敏感内容发进去,正式生产环境也不适合用免费版。
在这个边界内,够用了。
具体怎么操作,步骤非常少。
进入 OpenRouter 的 Nemotron 3 Super 页面,想直接聊天的话点 Chat,登录账号就能开始,支持 Google 账号快速登录,没有账号免费注册一个。
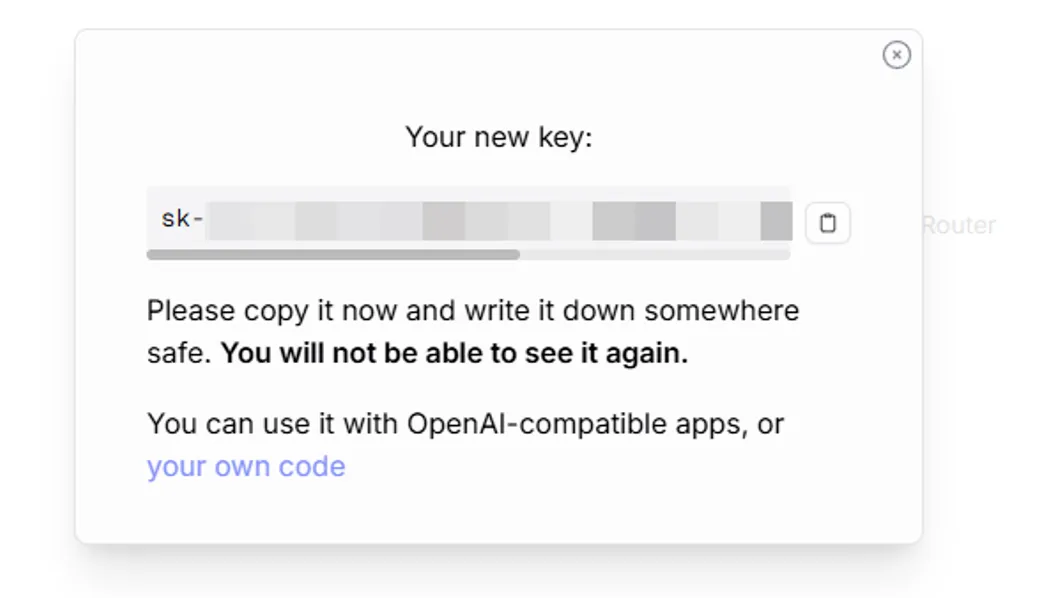
想拿 API Key 的话,登录之后进 API Keys 页面,点 Create,填个名字,其他不用管,点确认就拿到 Key 了。
拿到 Key 之后,在 OpenClaw 或者其他 LLM 工具里选 OpenRouter,填进去,模型选 Nemotron 3 Super(free),完事。
整个流程五分钟以内。
说实话,我之前也没太当回事。
120B 的发布会模型,第一反应就是跟普通人没关系,看个新闻就过去了。直到看到 OpenRouter 有免费版,试了一下,才意识到这个模型在 Agent 任务上确实不是在吹。
上下文特别长的任务,以前换别的模型经常跑到一半掉链子,这个跑下来稳多了。
所以这篇主要是想说:发布会上的东西,不是每次都离你很远。有时候找对路子,免费的也能用上最新的。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
