 夜雨聆风
夜雨聆风字数 2583,阅读大约需 12 分钟
OpenClaw-RL 回收每个智能体系统都在浪费的东西:下一状态信号。而且它是在您还在对话时就完成的。
TLDR(太长不看版)
• 每个智能体交互都会产生下一状态信号。每个现有系统都在浪费它。OpenClaw-RL 将其回收为实时训练数据。 • 完全异步架构:智能体在后台学习的同时继续提供服务。零中断。 • 两种方法(Binary RL + On-Policy Distillation)结合,在 16 步内将个性化分数从 0.17 提升到 0.81。 • 适用于个人智能体和通用智能体(终端、GUI、SWE、工具调用)。开源项目,普林斯顿大学。

事实是这样的:您部署的每个 AI 智能体都已经坐拥一座训练数据的金矿。每一个交互。用户回复、工具执行结果、终端输出、GUI 状态变化。所有这些数据都在那里,它们丰富、结构化、且免费。
然而每个单一系统都在丢弃它。
用户说"不,我指的是另一个文件"。这是一个训练信号。测试套件在智能体代码编辑后返回一个堆栈跟踪。训练信号。终端输出了一个退出码。训练信号。所有这些,都被当作仅仅是"下一个操作的上下文"而丢弃。没有转换成梯度。没有用来更新权重。只是……被消费后遗忘。
普林斯顿的一个团队刚刚发布了一篇论文,让这种浪费变得无法忽视。OpenClaw-RL。而且与大多数用新缩写重新包装现有想法的论文不同,这篇论文真正发现了整个智能体 RL 社区一直在忽视的一些根本性问题。
到底什么是"下一状态信号"?
很简单。在智能体执行动作 后,会发生一些事情。用户回复了。工具返回了输出。GUI 发生了转换。那个"一些事情"就是下一个状态 。在标准的 LLM 强化学习中,这个信号要么被完全忽略,要么被压缩为长轨迹末端的最终结果奖励。
OpenClaw-RL 认为这个信号携带两种可回收的明确信息。首先,评估信号:动作有效吗?用户重新查询意味着不满意。通过测试意味着成功。PRM 可以将这些逐轮转换为标量奖励。其次,指令信号:动作应该如何不同?当用户写道"你应该先检查文件",这不仅仅是一个差评。它告诉您哪些 token 应该改变以及如何改变。标量奖励无法捕捉这些。您需要更丰富的东西。
说实话,评估部分并非全新。PRM 在数学推理中已被研究了一段时间。但将它们作为实时、在线的过程奖励,同时应用于异构交互流(对话、终端、GUI、SWE 任务、工具调用)?这不是通常的"我们在固定数据集上训练"的故事。这次,是实时的。
使其工作的架构
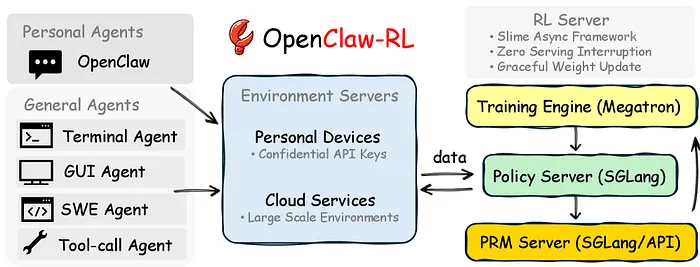
OpenClaw-RL 构建在 slime 异步框架之上,它将所有内容解耦。四个独立循环,零阻塞依赖运行:

模型在您下一次请求时提供服务,而 PRM 评判您之前的响应,训练器从两个交互之前应用梯度更新。没有组件等待另一个。对于个人智能体,您的设备通过机密 API 连接。对于规模化通用智能体,数百个并行环境在云服务上运行。
哦!它还将每个 API 请求分类为"主线"轮次(可训练:实际响应和工具执行)与"辅助"轮次(不可训练:记忆组织、辅助查询)。所以它确切地知道要学习什么。
Binary RL:粗糙但可靠的信号
PRM 根据下一状态反馈评估每个智能体响应。用户看起来满意吗?工具调用成功了吗?评判者评分:+1(好)、-1(差)或 0(中立)。通过多数投票进行多次独立评估以确保稳健性。
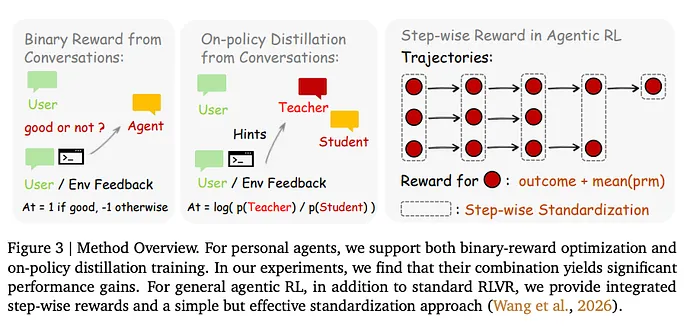
这些标量奖励输入到具有不对称界限的 PPO 风格裁剪代理损失函数。标准做法,成熟的优化。Binary RL 接受每个评分的轮次,可与任何下一状态信号配合使用,包括简洁的反应,并提供广泛的梯度覆盖。
但问题是:它很粗糙。每个序列一个标量。当用户说"你应该在编辑前先检查文件",Binary RL 给您一个 -1。就这样。关于要改变什么以及如何改变的所有方向信息?丢失了。
后见之明引导的 On-Policy Distillation:秘密武器
这就是 OpenClaw-RL 真正聪明的地方。OPD 回收了 Binary RL 丢弃的指令信息,而且它不需要单独的、更强的教师模型。
四个步骤。
1. 第一步:评判者从下一状态信号中提取简洁的"提示"(1 到 3 句可操作的纠正)。 2. 第二步:质量过滤;只有具有明确、可提取纠正方向的轮次才能通过。 3. 第三步:提示被附加到原始提示词,创建"增强的教师上下文";如果用户一开始就给出纠正,模型会看到的内容。 4. 第四步:策略模型在此增强上下文下查询,"教师"(提示增强)和"学生"(原始)分布之间的每个 token 对数概率差距成为优势信号。
这是漂亮的自蒸馏设计。没有外部教师。没有预收集的反馈对。模型使用对话中已有的后见之明来教自己。一些 token 被强化,其他被抑制。每个 token 的方向指导;比单个标量丰富得多。
但等等。OPD 很挑剔。它只在存在明确纠正方向的轮次上训练。样本稀疏。这就是为什么您需要两种方法同时运行。
组合方法改变了数字
数字不说谎。从 0.17 的基线个性化分数开始:
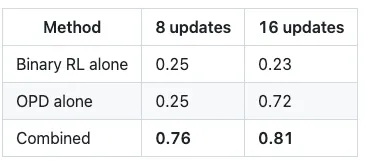
我们认真的吗?单独的 Binary RL 在 16 步后实际上会退化。单独的 OPD 显示延迟收益(稀疏样本,记住?)但最终会艰难攀升。但组合起来?仅 8 次更新后就达到 0.76。从 0.17。
具体来说:一个使用 OpenClaw 做作业的学生只需要 36 次问题解决交互,智能体就学会了停止听起来像 AI(不再有"粗体"格式,不再有机械的逐步说明)。一个批改作业的老师只需要 24 次交互,智能体就开始写更友好、更具体的反馈。学生场景从 0.17 跳到 0.76。老师从 0.22 到 0.90。
不仅仅是个人智能体
相同的基础设施处理跨终端、GUI、SWE 和工具调用设置的通用智能体 RL,具有大规模并行化(终端 128 个环境、GUI/SWE 64 个、工具调用 32 个)。不同设置使用不同模型:终端使用 Qwen3-8B、GUI 使用 Qwen3VL-8B-Thinking、SWE 使用 Qwen3-32B。
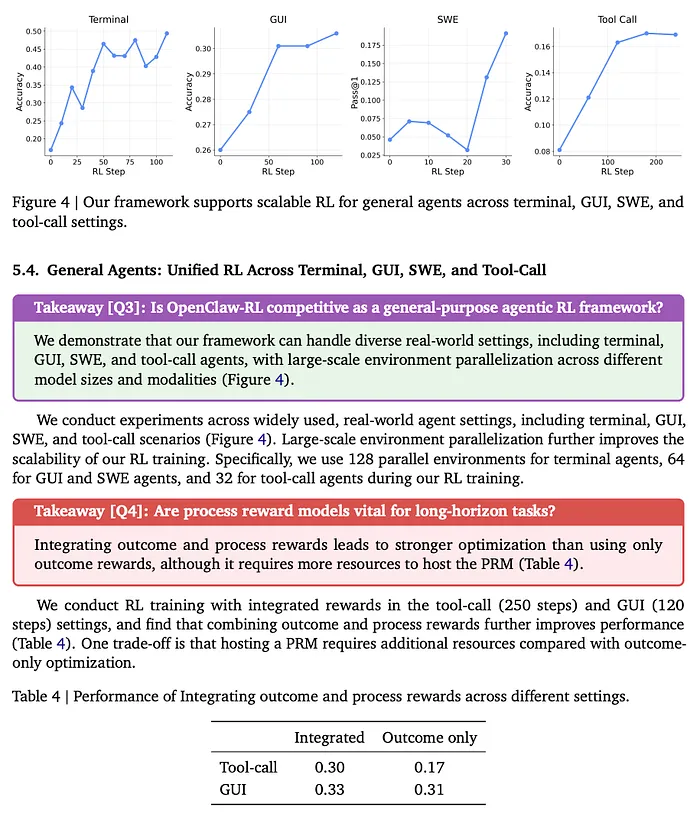
对于通用智能体,他们将过程奖励与结果奖励整合。工具调用的结果:整合奖励 0.30 vs 仅结果奖励 0.17。光是添加逐步 PRM 信号就带来了 76% 的提升。绝对数字不算惊人,但方向性证据很明确:过程奖励对长周期智能体任务很重要,而 OpenClaw-RL 使其在规模化上变得实用。
为什么这真的很重要
现在每个智能体框架都通过记忆文件、系统提示词和技能库来适应。基础模型权重从不改变。OpenClaw-RL 改变权重。在您使用它的同时。不中断服务。
整个堆栈(策略模型、评判者、训练器)在您自己的基础设施上运行。没有第三方 API 调用。您的对话数据保留在本地。一切都实时记录到 JSONL 以实现完全可观测性。
这是第一个在相同循环中统一个人智能体个性化和通用智能体训练的系统,从相同的下一状态信号,跨异构交互类型。对话、终端、GUI、代码仓库、工具调用;它们都只是具有不同转换函数的不同 MDP。训练信号是通用的。
通过使用而改进的智能体不再是研究原型。它是开源的,是异步的,运行在您的硬件上,并从您已经在生成和丢弃的数据中学习。
但如果您在构建智能体系统而没有回收下一状态信号用于训练,您就在放弃最自然、最丰富、信息量最大的监督源。OpenClaw-RL 刚刚向您展示了如何捡起它。
