 夜雨聆风
夜雨聆风用 Git 对 OpenClaw 进行配置管理
使用 OpenClaw,不是"装上能聊天就完事",而是把每一次配置和变化都纳入可追踪、可回滚、可复盘的系统演进过程。
很多人第一次折腾 OpenClaw,最关心的往往是两件事:
怎么安装? 怎么接飞书,远程驱动这只龙虾来干活?
但如果你想把 OpenClaw 用成一个能长期维护、能持续迭代的 AI 助手系统,还有第三个问题更重要:
每完成一步配置,系统里到底改了什么?
如果这件事看不清,后面就很容易陷入一种非常熟悉的状态:
现在好像能跑了,不知道它为什么能跑 不知道我安装一个 skill,会不会影响其他的 skill 让龙虾做了一个新的配置,但是不知道它具体改了什么 有没有后悔药,让 OpenClaw 退回到上次一次好用的龙虾
这篇教程,我来给大家演示一个,从一开始就把 OpenClaw 的核心目录 .openclaw 当成了一个 Git 管理的配置仓库。
这样每往前走一步,我都能回答四个问题:
我刚刚做了什么操作? 哪些文件被改了? 这些变化在 Git 里怎么体现? 这一轮值不值得单独 commit 固化下来?
这篇文章,就按这条线来完整复盘。
先说结论:学习 OpenClaw 的最好方法,不是"配完"能用就行,而是"边配边看",掌握龙虾最底层的配置原理
很多工具的接入教程都喜欢写成一条直线:
第一步装 第二步配 第三步连 第四步用
看起来很顺,但有个问题:
你知道怎么操作,却不一定知道系统发生了什么。
而 OpenClaw 恰恰不是那种"一次性装机软件"。 它更像一套会持续演进的本地 AI 系统。你后面大概率还会继续:
换模型 加技能 接更多渠道 改工作区 增加自动任务 累积会话、日志和运行状态
所以最稳的办法,不是指望"一次性全配对",而是从一开始就养成一种工程化习惯:
每做完一个关键动作,就用 Git 看一眼系统到底变了什么。
这也是我这次整套配置过程最核心的方法论。
一、先建立一个正确认知:.openclaw 不是缓存目录,而是你的助手系统根目录
OpenClaw 在 Windows 下的核心目录通常在:
C:\Users\你的用户名\.openclaw图 1:配置从 .openclaw 目录展开
别把它理解成普通软件的缓存目录,它是 OpenClaw 的系统根目录。后面你做的大多数配置,都会逐步通过文件和目录,落进这里,比如:
openclaw.json:主配置文件agents/:各个 agent 的模型、会话、配置workspace/:长期工作的工作区logs/:配置与运行日志tasks/:后台任务运行状态canvas/:一些前端/可视化资源
这张图真正有价值的地方,不只是"进了某个目录",而是它提醒你:
从这一刻开始,你面对的不是一个聊天窗口,而是一套有目录结构、有配置文件、有运行状态的本地 AI 系统。
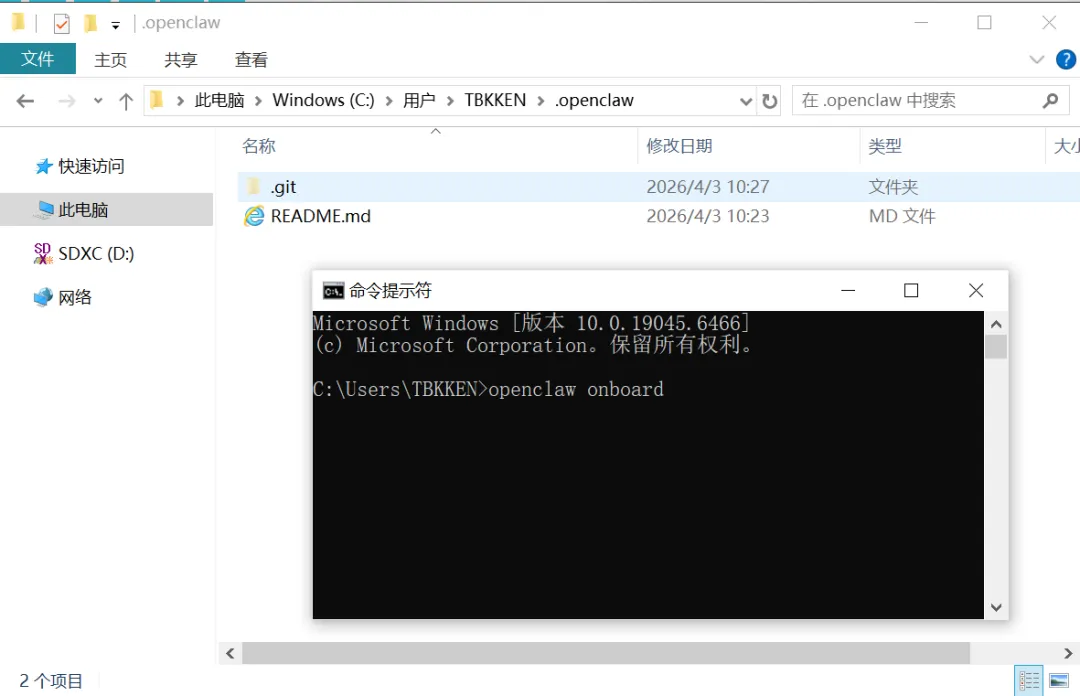
而既然是系统,就值得被版本管理,下面,事不宜迟,我们直接开干,在输入 openclaw onboard 之前,记得先输入 git 六件套。
git inittouch README.mdgit add .git commit -m "初始化项目,请多多指教"git remote add origin https://gitee.com/你的用户名/openclaw.gitgit push -u origin main这一阶段,Git 应该关注什么?
这一步重点是能够将 README.md 文件提交上去就OK了,从现在开始,你就不是"凭感觉配置",而是"按系统去管理" OpenClaw。
二、为什么我要先接 Git,而不是先把所有向导一路点完
因为 OpenClaw 的很多"配置动作",本质上都不是纯界面操作,而是对本地文件树的真实写入。
也就是说,所谓:
接入渠道 设置模型 启用技能 打开 hooks 生成工作区
在底层都会表现成:
文件新增 文件改写 日志写入 运行状态生成
如果这时没有 Git,你对系统变化的感知会非常模糊。
你只会觉得:
刚才好像配了点东西 现在似乎多了点文件 但具体哪里变了,说不清
而如果先把 .openclaw 纳入 Git,后面的每一步都会变得特别清楚:
哪些是你手改的 哪些是 OpenClaw 自动生成的 哪些属于长期配置 哪些其实只是运行态副产物
所以我越来越觉得:
Git 在这里不是最后做备份,而是整个配置过程里最重要的观察工具。
三、前戏已经做足,开始配置龙虾
如图1所示,在cmd命令窗口,输入 openclaw onboard ,开始配置龙虾。
图 2:选择 Yes,锁住2配置文件,开始配置
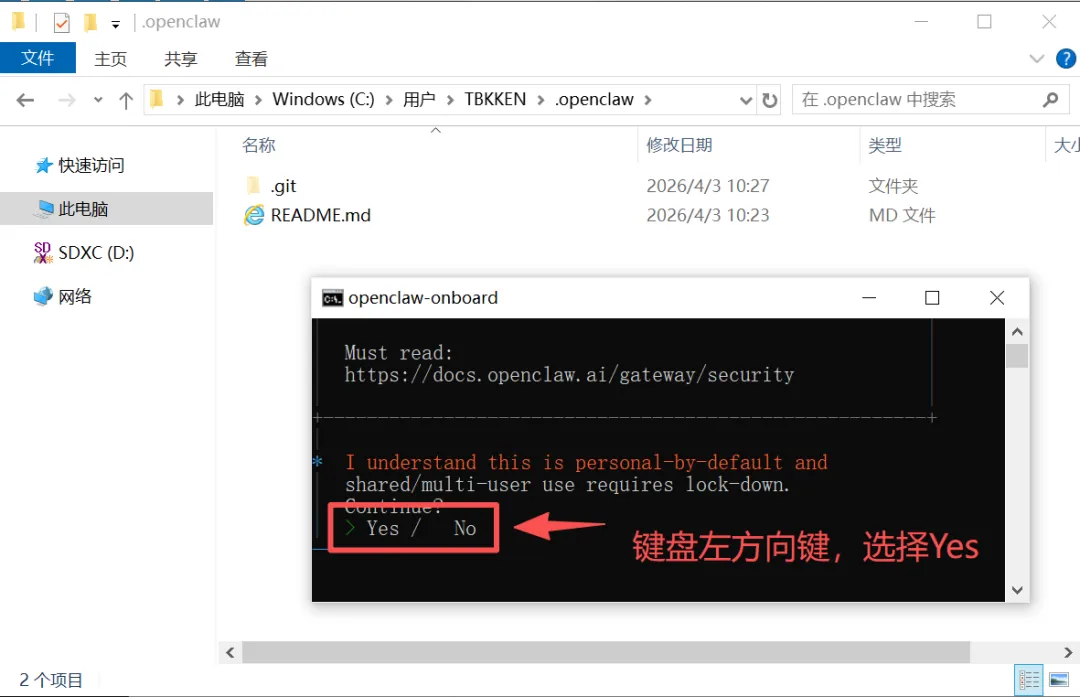
图 3:QuickStart,快速开始
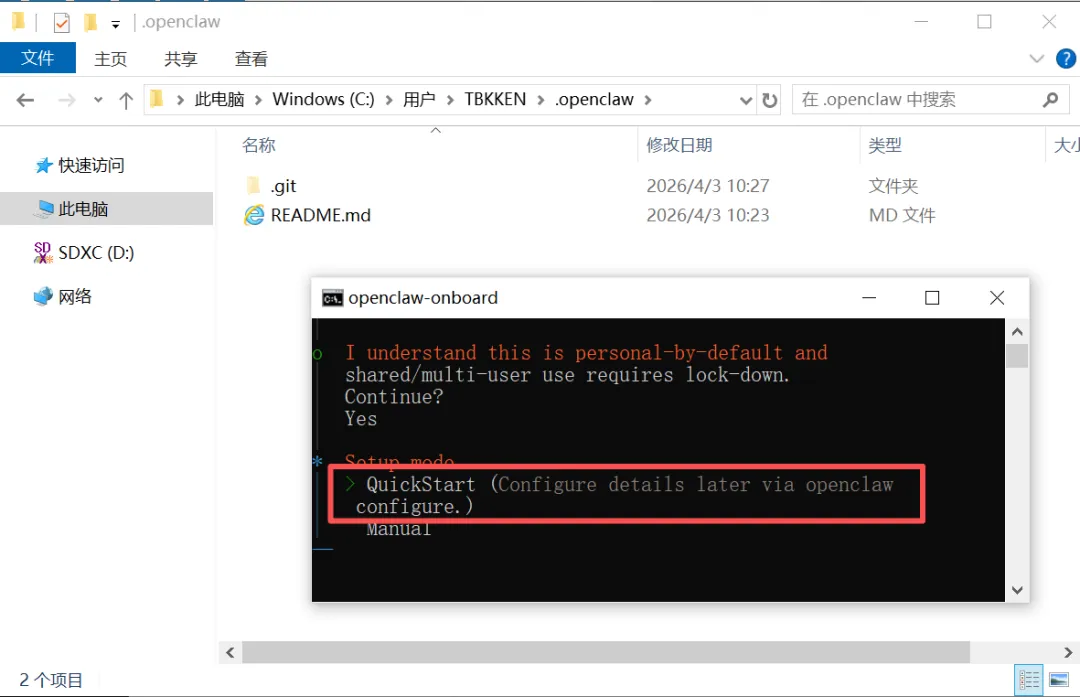
图 4:开始选择模型
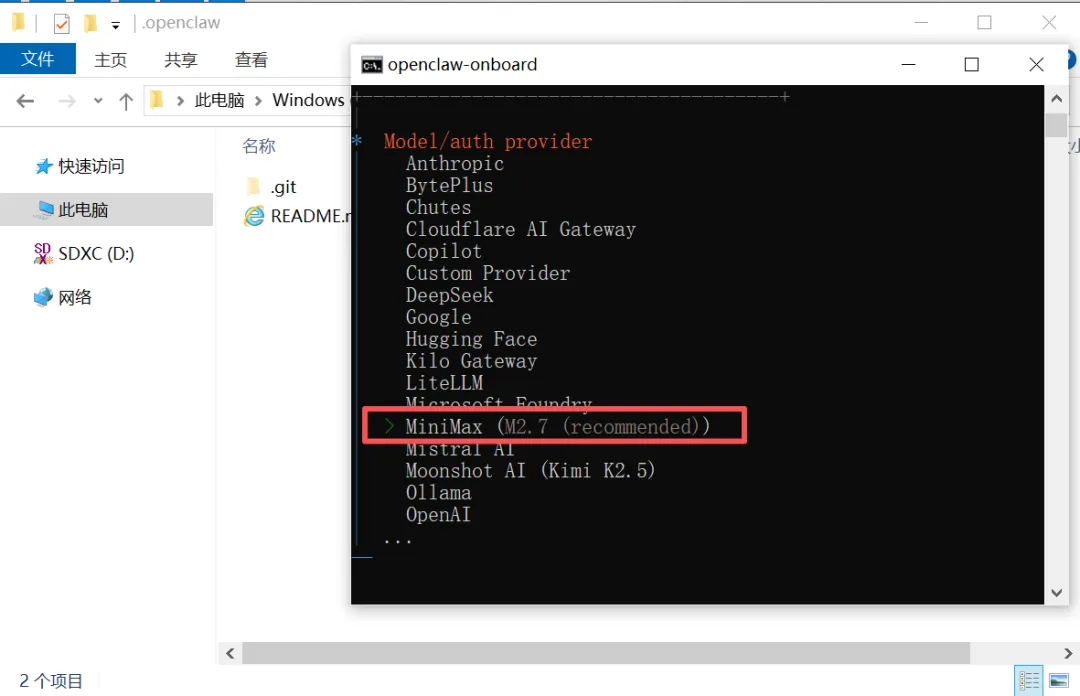
我这里购买的是 MiniMax 的 Code Plan,所以选择MiniMax,大家按照自己购买的服务选择即可。
图 5:使用 API Key 方式调用大模型
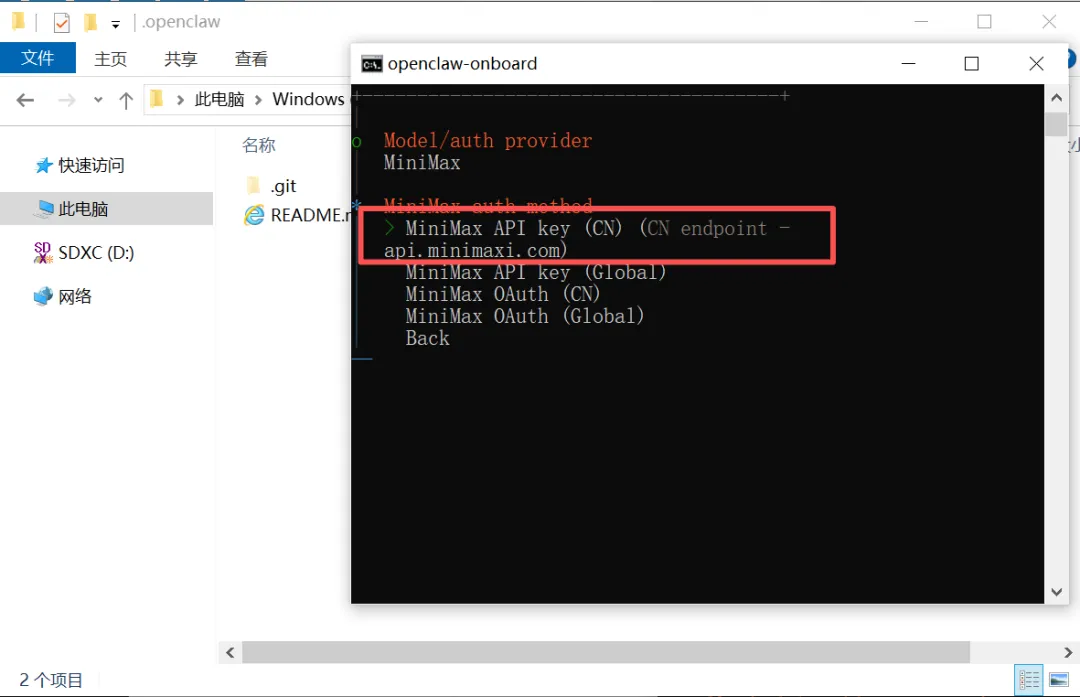
图 6:输入API Key
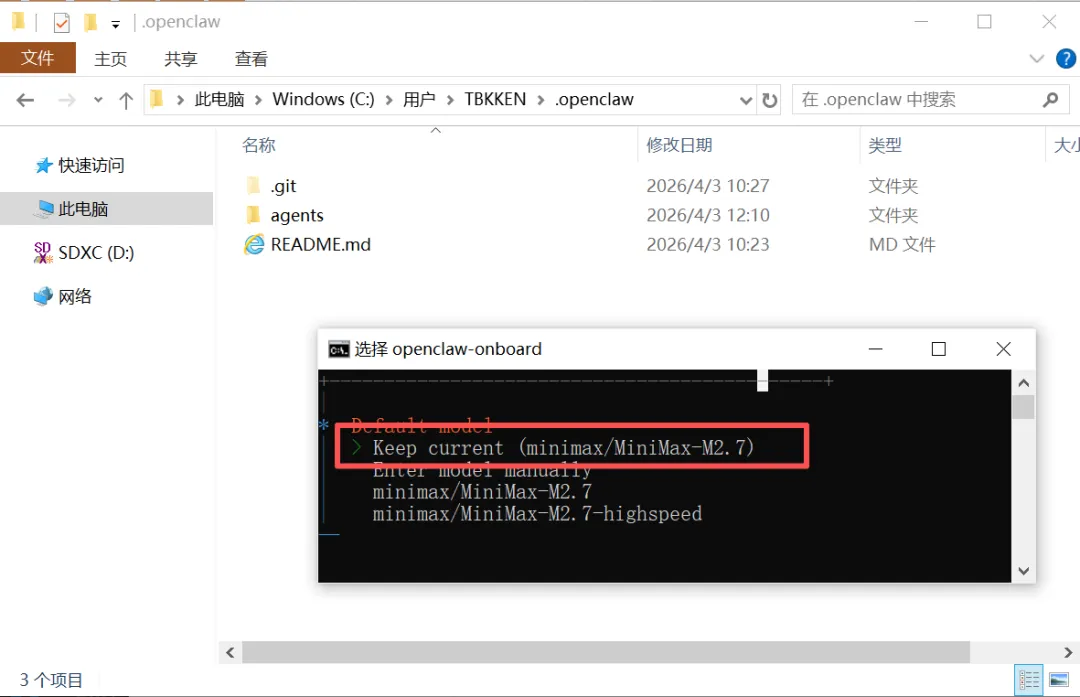
图 7:选择大模型,当然用最新的
配置完了之后,我们的 Git 应该用上了,来看看模型配置完了之后,系统的配置文件,做出了什么改变。
而这部分在截图里,有一个非常明确的落点:
图 8:用 git 查看,模型做了哪些文件修改
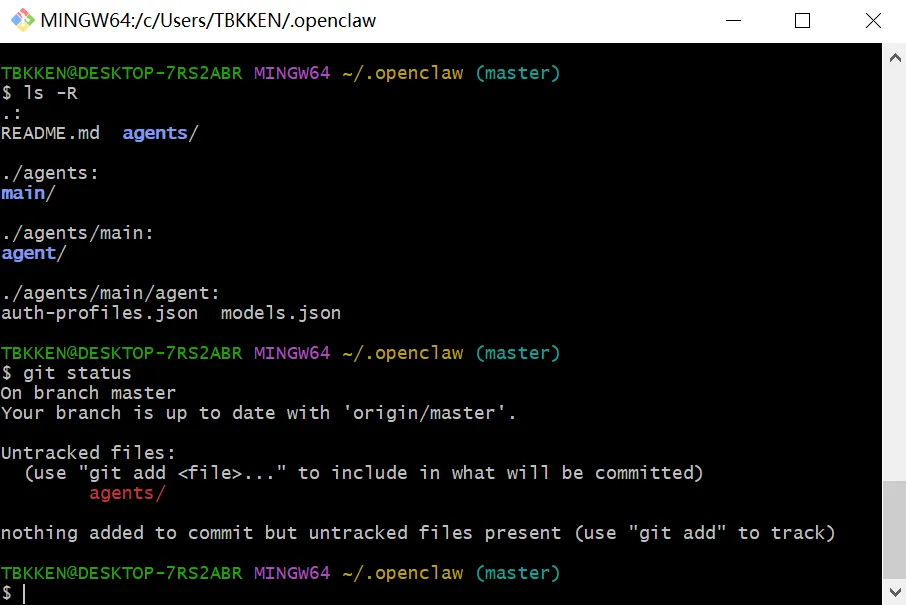
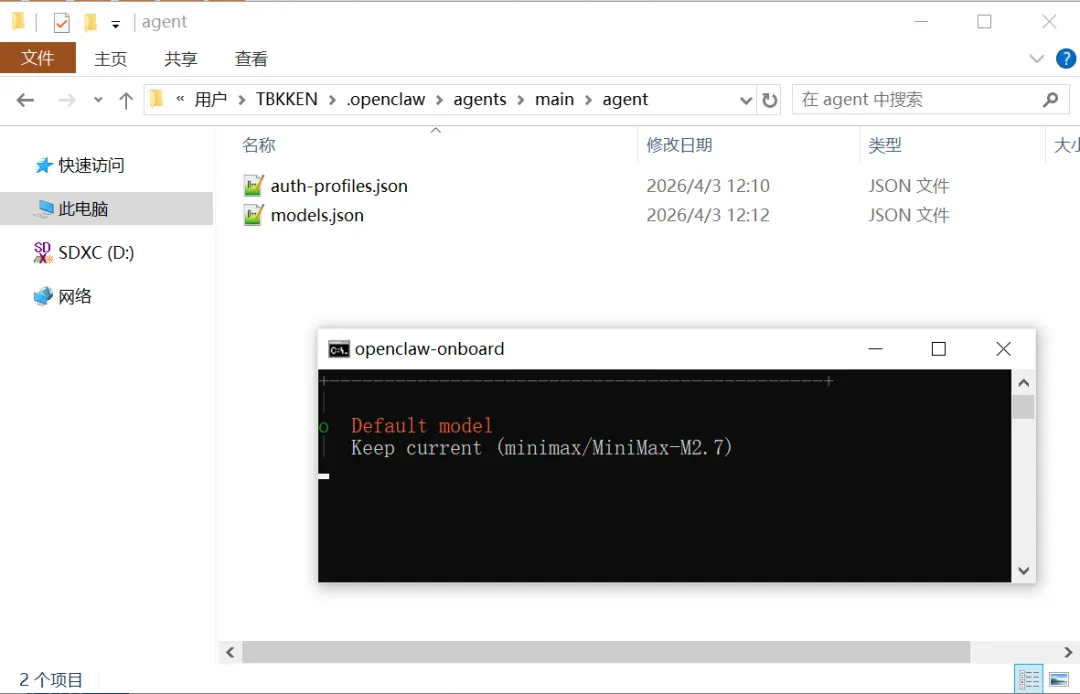
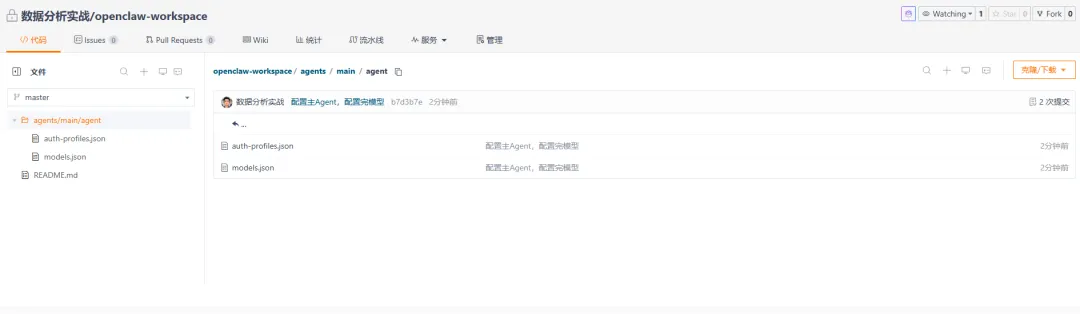
可以看到,新增了一个 agents 目录,里面多了一个 main 的智能体,这个就是龙虾的核心智能体,是不能删除的。
智能体 agent 是通过目录的形式,在 agents 目录下体现和维护的,main 目录下面,还有一个 agent 的目录,用来维护 llm 的信息。
auth-profiles.json --就是 llm 的 api-key 保存地方models.json -- 就是 llm 的模型保存的地方图 9:agents/main/agent/auth-profiles.json 文件
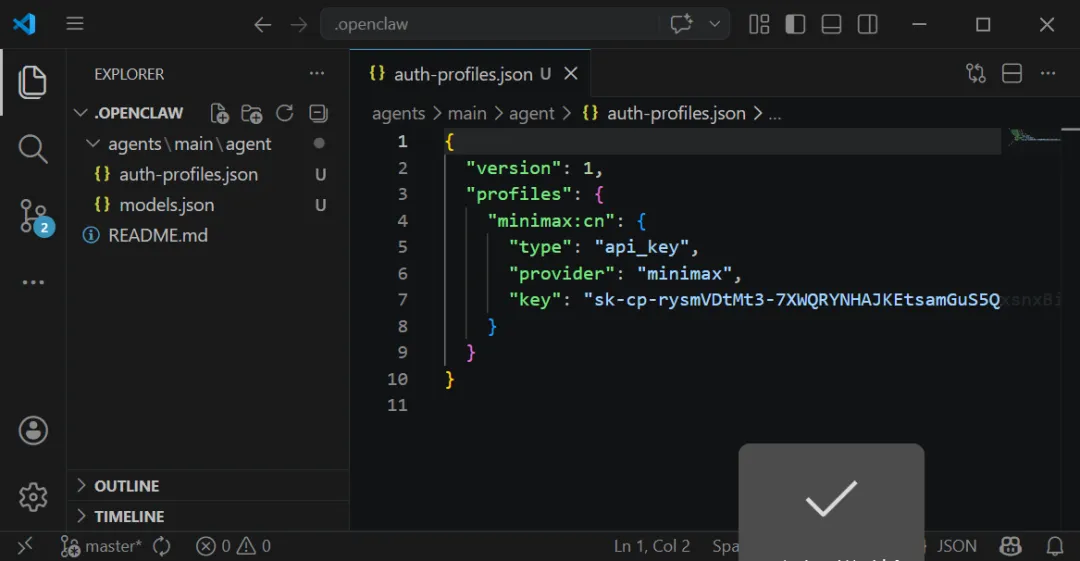
图 10:agents/main/agent/models.json 文件
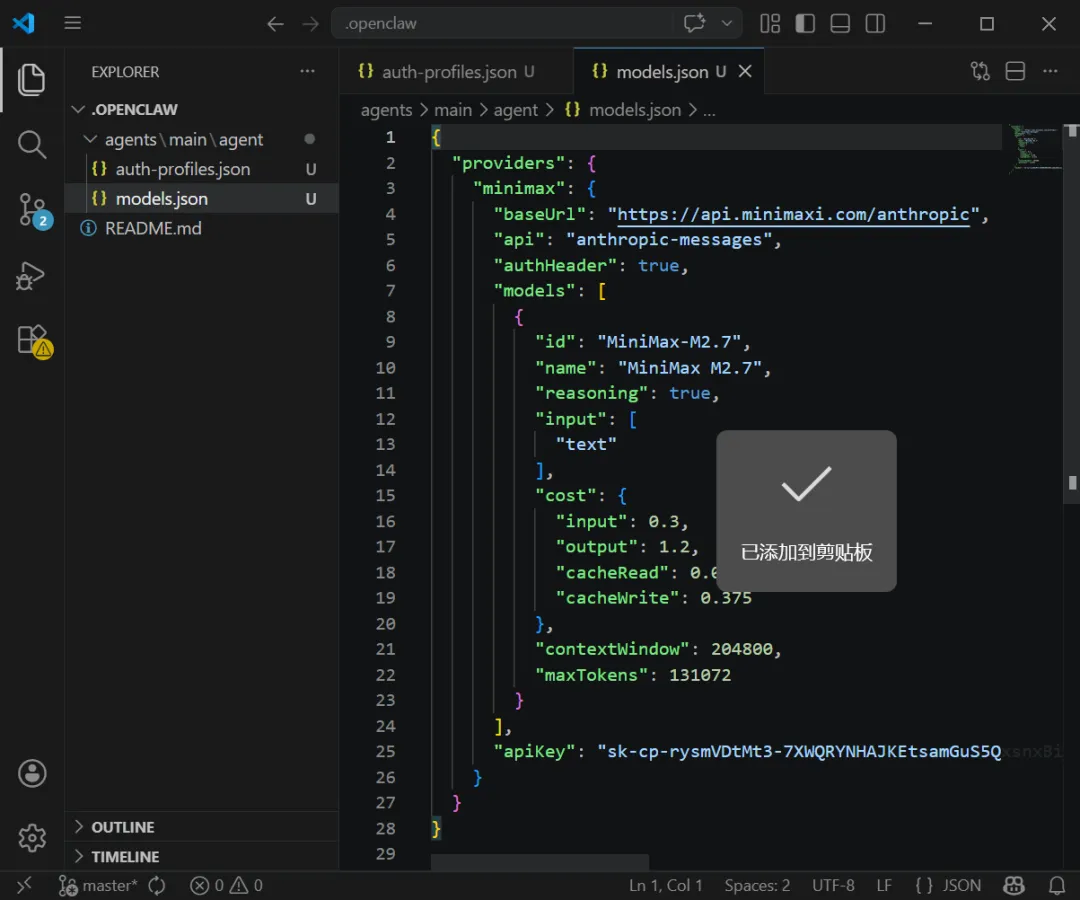
从截图能看出来,这里已经不是只填一个模型名,而是在定义一整套 provider 信息,包括:
baseUrlauthHeaderapiKeymodelscontextWindowmaxTokens
换句话说,models.json 本质上在回答这些问题:
OpenClaw 去哪里请求模型? 它怎么鉴权? 默认用哪个模型? 上下文窗口有多大? 单次输出准备放多大?
这类文件为什么一定要纳入 Git?
因为它几乎一定会反复调整。后面你很可能还会继续:
换模型提供商 加备用 provider 改默认模型 调上下文窗口 调 token 上限
所以只要动了 models.json,我都建议把它视为一次真实配置演进,而不是"顺手改一下"。
图 11:将新增的和修改的文件,一把提交到 git 上
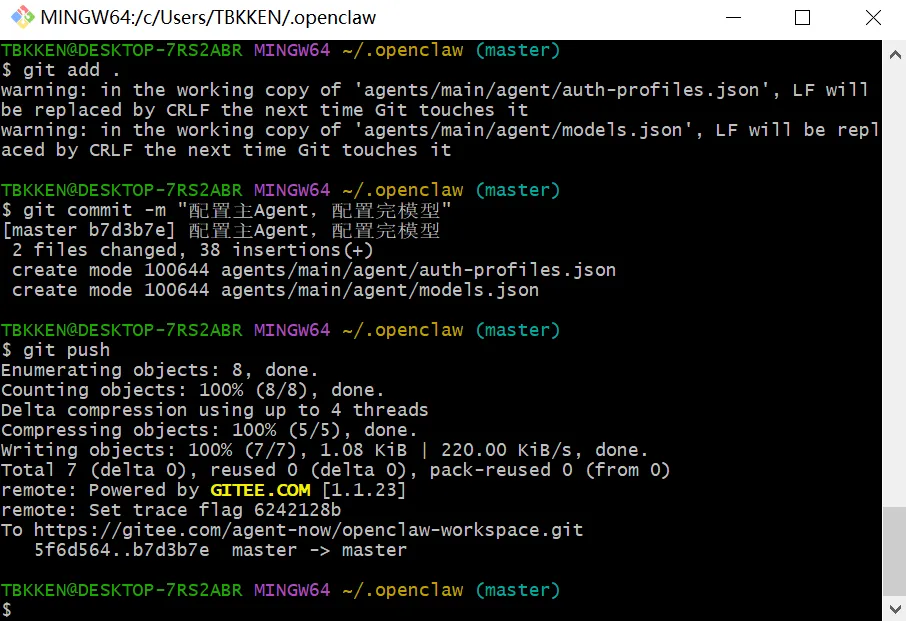
图 12:在 Gitee 上,你可以一目了然,看到这次提交的变化点
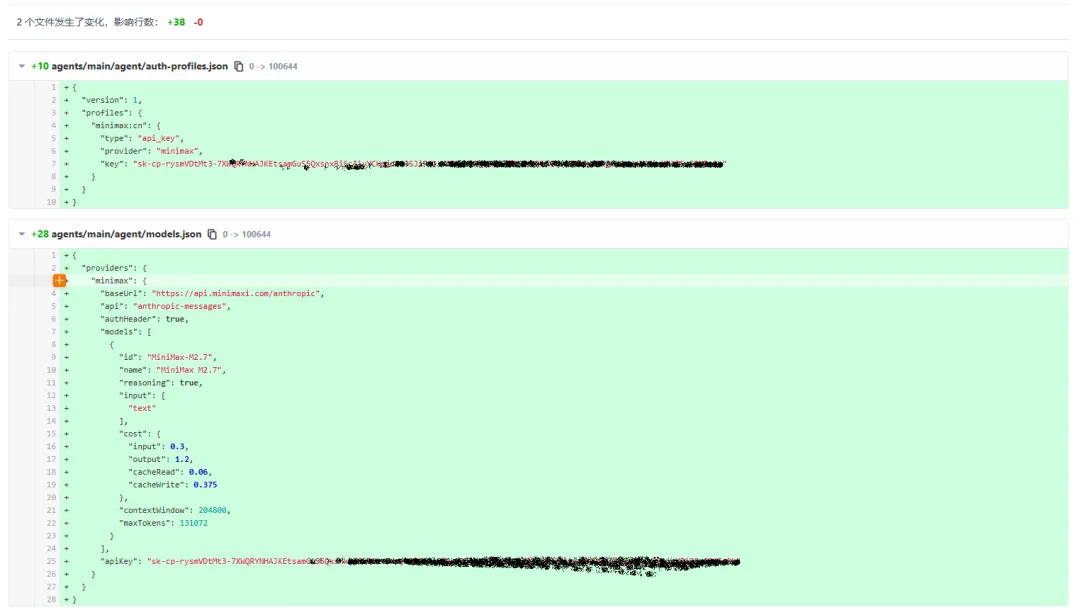
这就是 Git 的强悍之处,每次文件内容的增加和删除,都会一一记录。
这一阶段的小结
如果说 OpenClaw 的"人格"和"能力边界"一部分来自工作区,那另一部分就来自模型层,而 models.json,就是最该被认真追踪的那类高价值配置。
四、真正进入接入阶段后,OpenClaw 开始从"静态目录"变成"活系统"
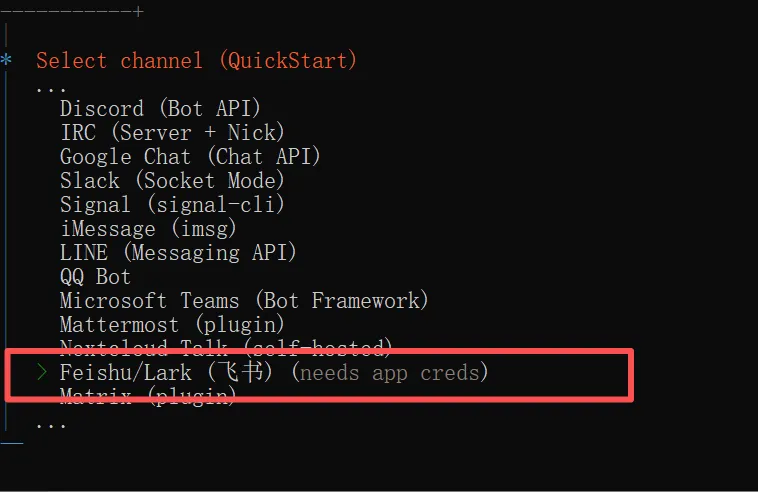
接下来, openclaw onboard 流程,走到了 Feishu 接入。
图 13:Channel 选择飞书接入
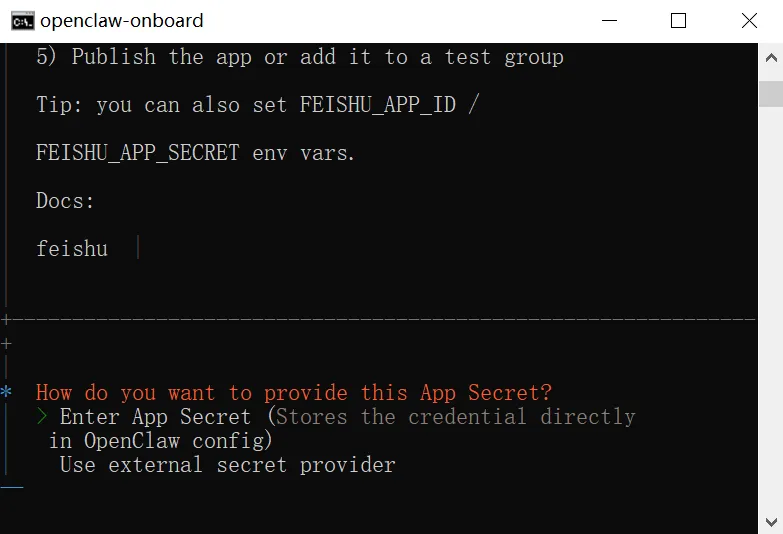
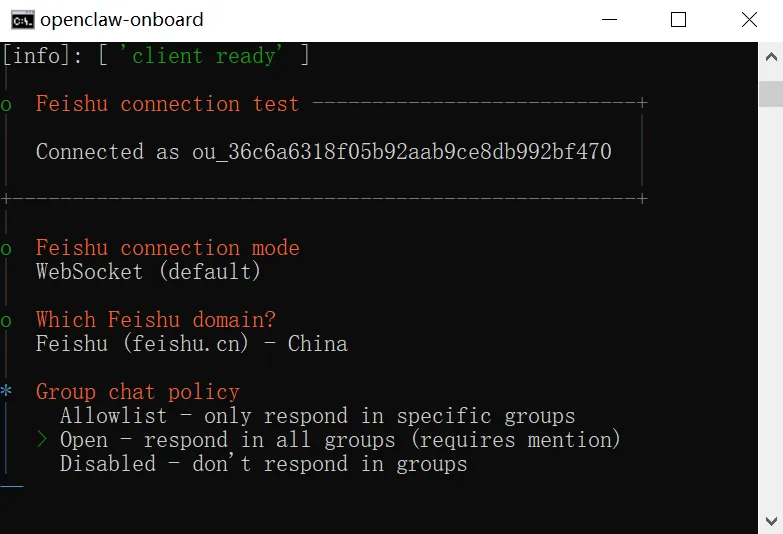
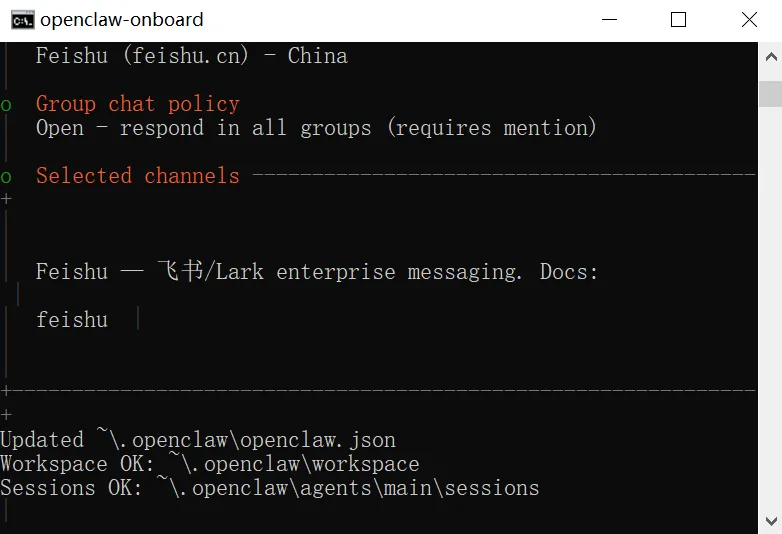
可以看到,配置完飞书后,以下文件做了修改:
~\.openclaw\openclaw.json -- openclaw 的核心配置文件~\.openclaw\workspace -- 新建了工作目录~\.openclaw\agents\main\sessions -- main agent 的会话记录~\.openclaw\agents\main\agent\models.json -- 这个配置也修改了~\logs -- 增加了一个日志目录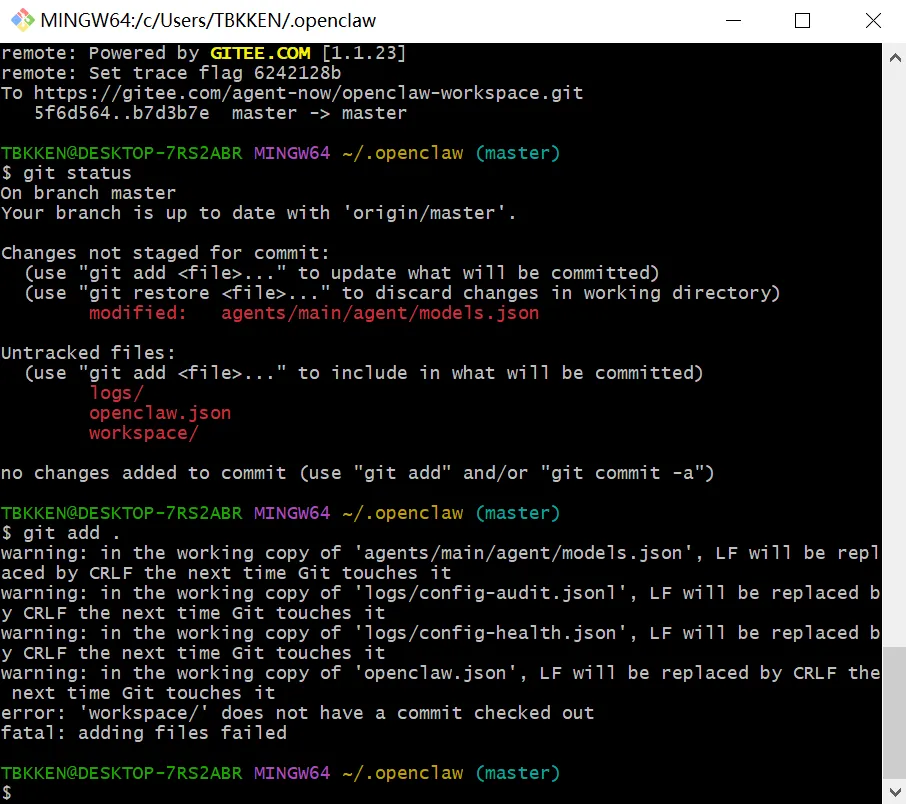
这里我们需要一个点,当我们提交 workspace 目录的时候,发现 openclaw 也是用 git 来管理 workspace 目录的,英雄所见略同啊。
这里,我们新增一个 .gitignor 文件,将 workspace 目录剔除,使用另外的项目来管理它。
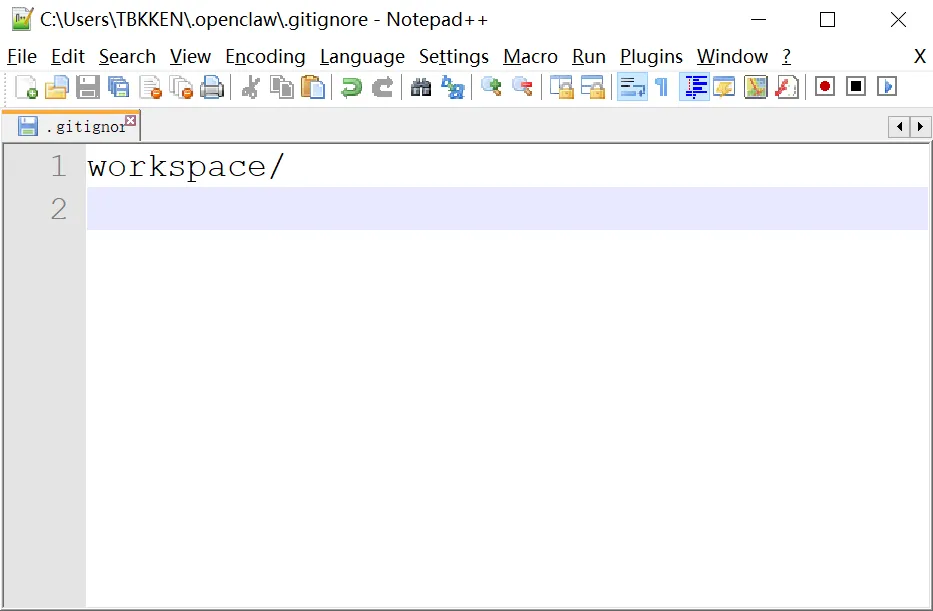
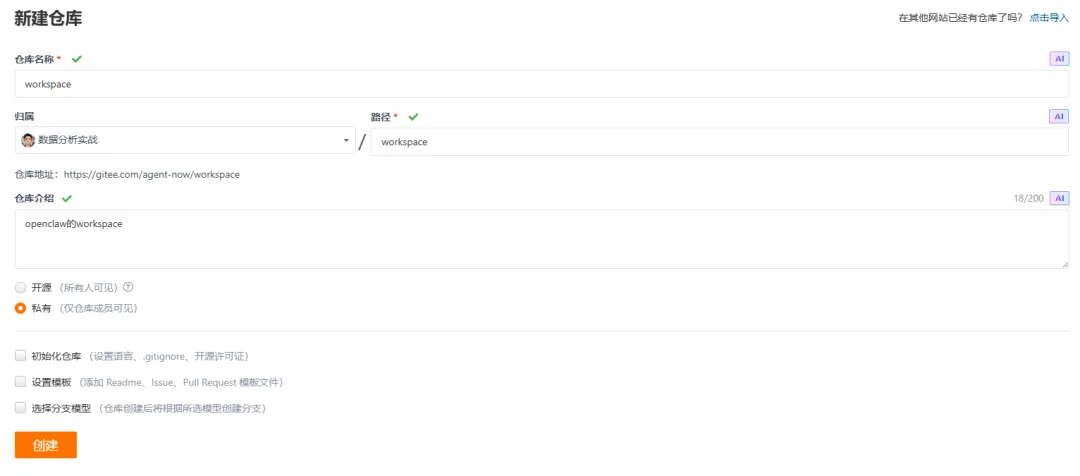
然后,新建一个workspace的新项目,再将它的文件,同步到 gitee。
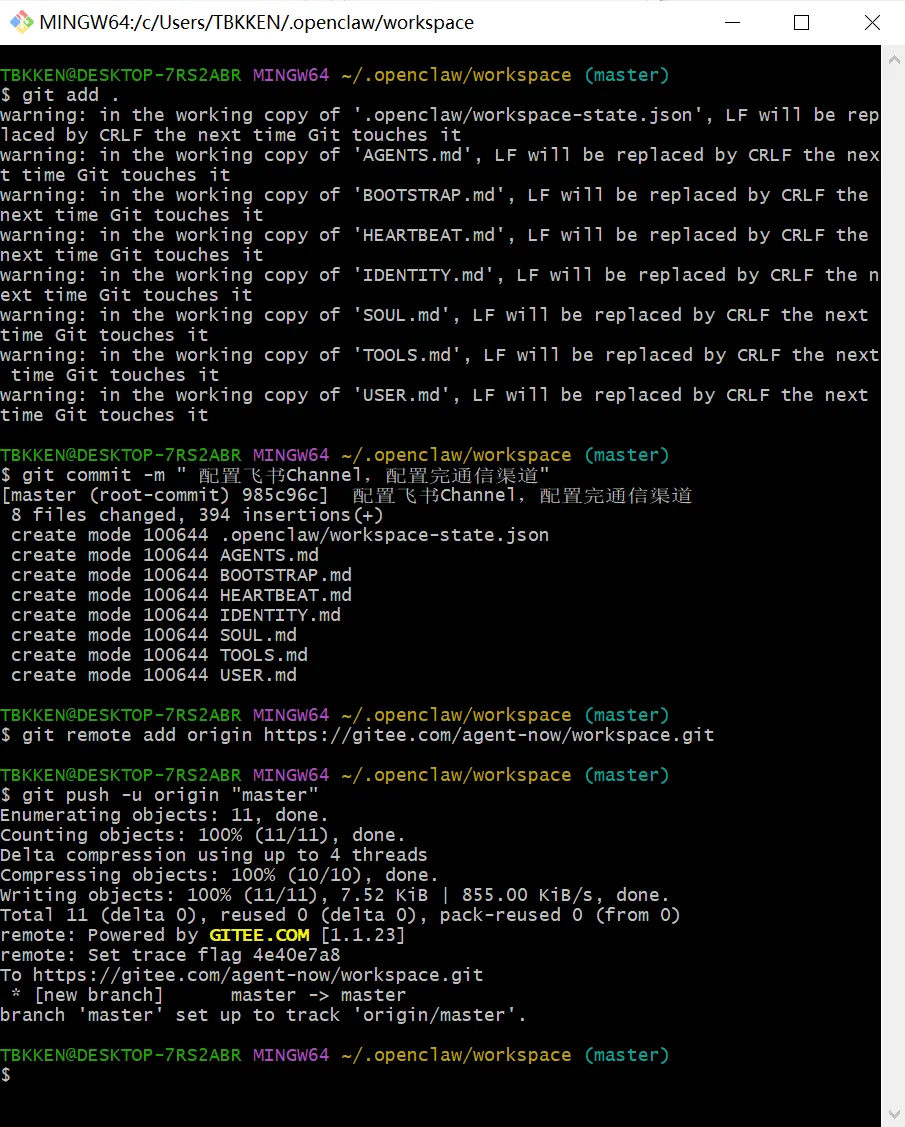
我们来通过 gitee 上面文件的变更,来学习配置完飞书之后,openclaw 发生了什么变化。
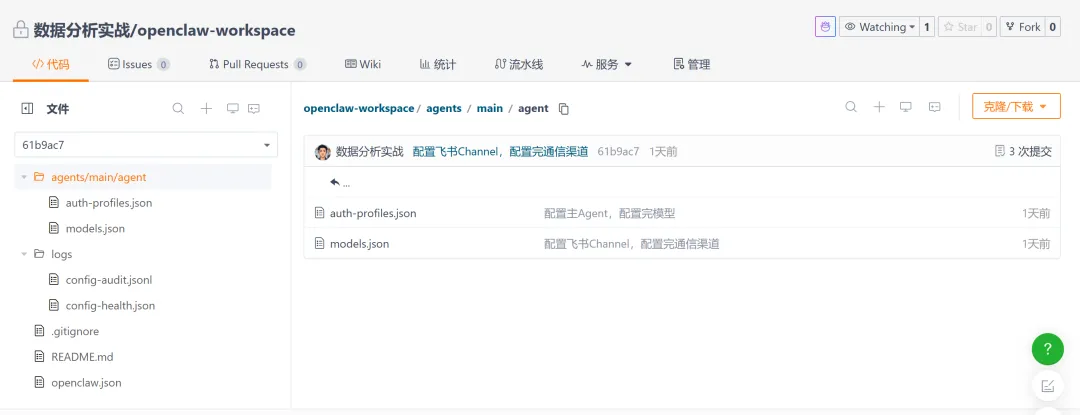
核心变化点,应该是这个,在 openclaw.json 中,增加了飞书的配置:
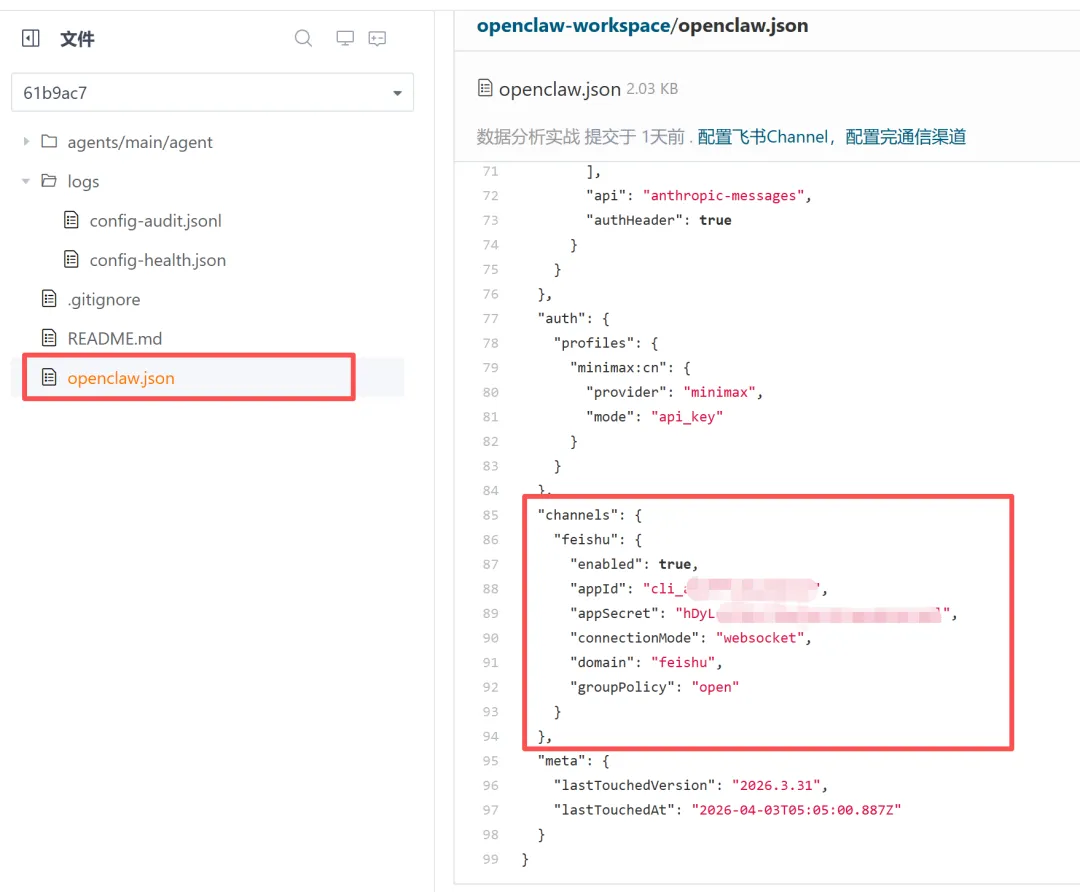
接着,在workspace里面,增加了一系列的文件,这一系列的文件,是OpenClaw的Workspace设计。
大多数AI助手,用完即弃。
你问它答,它完成任务,你们之间没有任何积累。下一次对话,你们重新变成陌生人——它不知道你是谁,不知道你们之间发生过什么,不知道你的偏好和边界。
这是AI的原生状态:无状态,每次从零开始。
是OpenClaw的Workspace设计,试图解决这个问题。它用7个.md文件,构建了一套完整的AI认知架构——让AI不只是问答工具,而是一个有记忆、有判断力、有边界的数字存在。
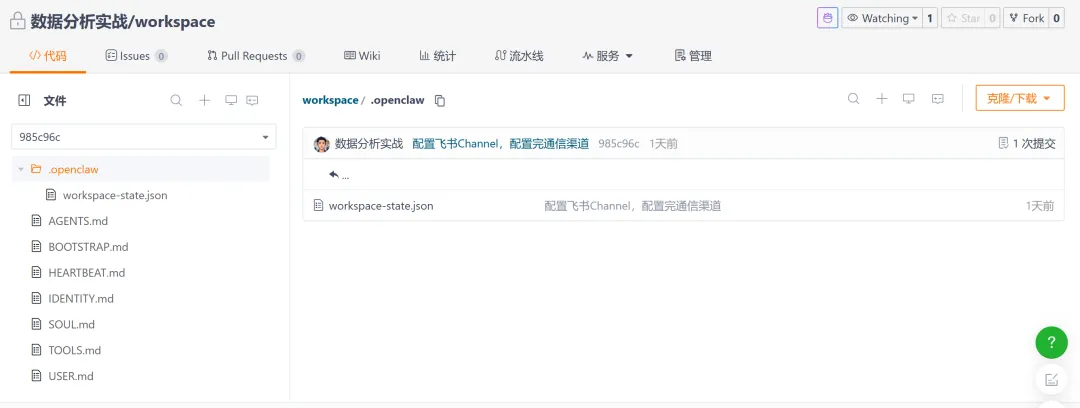
这七个文件的详解,我们下一篇文章再来详述了。
这一阶段最值得关注的,不是向导本身,而是它的落盘结果
界面上的每个选择,最后都会变成文件系统里的真实变化。而只要你能把这些变化看清楚,后面的调试和排错就会轻松很多。
五、Git 第一次把真相摊开:你刚刚那几步,到底改了哪些文件
这部分是整个过程里我最喜欢的一段,因为它非常"工程化"。
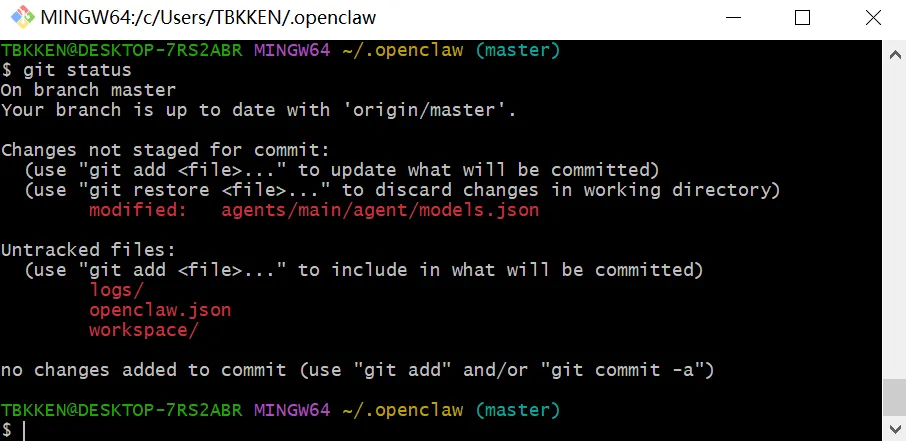
git status 直接暴露变更结果
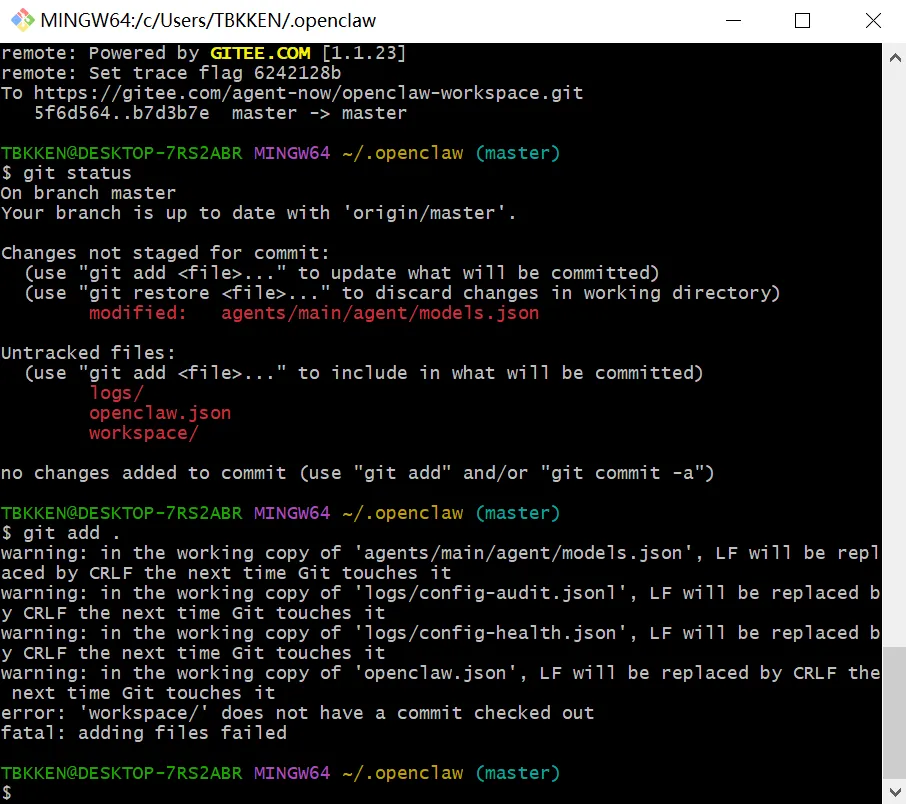
从这张图里可以清楚看到:
已修改但未暂存的文件
agents/main/agent/models.json
新出现但未追踪的目录
logs/workspace/
这三类变化,刚好对应了配置过程里的三个层次:
1)你手动配置的内容
例如:
models.json
2)OpenClaw 自动生成的系统侧痕迹
例如:
logs/
3)OpenClaw 开始建立长期工作环境
例如:
workspace/
这时候,Git 的价值就完全体现出来了。
如果没有 git status,你只能模糊地感觉"系统应该是改了点东西"。
但有了它,你就能非常具体地说:
刚才那一轮操作,至少影响了模型配置、日志系统、工作区目录三块内容。
这才是系统被真正"看见"的感觉。
这一张图为什么特别关键?
因为它把"配置过程"从一种体验,变成了一种可验证事实。
你不再需要靠记忆判断,而是可以直接看到文件层面的结果。
六、一个非常典型的坑:别一上来就无脑 git add .
同一张图里,还暴露了一个非常真实的问题。
执行:
git add .之后报错:
error: 'workspace/' does not have a commit checked outfatal: adding files failed这个错误特别值得写进文章,因为它和普通项目不太一样。
它至少说明了两件事。
第一,workspace/ 不是一个你可以想当然处理的普通目录
它可能:
带有特殊 Git 状态 含有嵌套仓库痕迹 或在初始化过程中并不适合被你直接整体纳入
第二,OpenClaw 的目录结构里,配置文件和运行空间并不总适合"一锅端"提交
这也是为什么我会建议:
不要把 OpenClaw 当普通源码仓库那样直接
git add .。先看清楚,再选择性纳入。
尤其要区分:
你自己维护的配置 OpenClaw 自动生成的运行状态 可能有独立生命周期的工作区目录
这一步真正的价值,不只是避坑
更重要的是,它帮你建立了一种正确的管理习惯:
OpenClaw 不是不能用 Git 管,而是要"带判断地管"。
我们来继续往下配置。
配置搜索引擎,用默认的即可
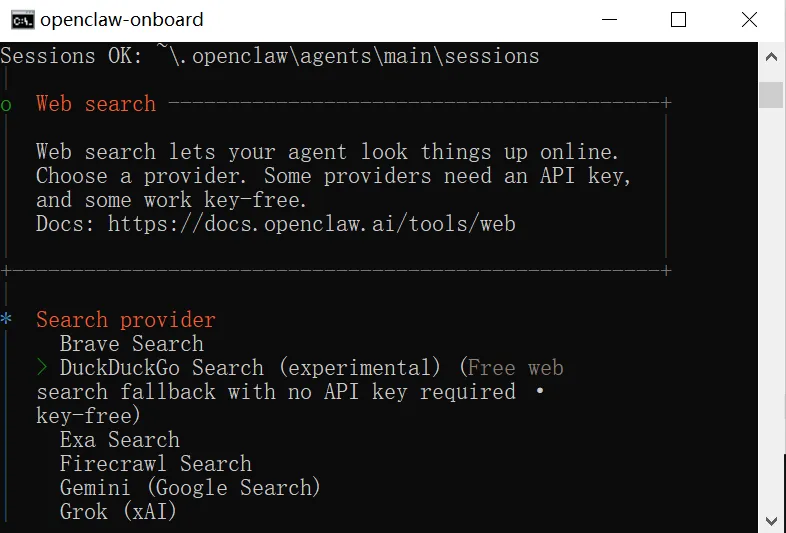
配置 SKILL,直接跳过即可
配置 SKILL,直接跳过即可
这些暂时还用不到,直接跳过
hooks 也直接跳过
基本上已经配置完成,先提交一次,看看变化
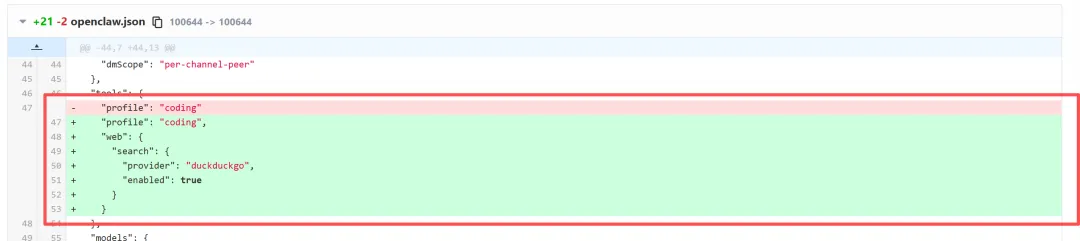
可以看到,核心变化,是新增了搜索工具的引入,如下图所示
七、配置 GateWay 服务
接着,来配置 OpenClaw 的 GateWay 服务。
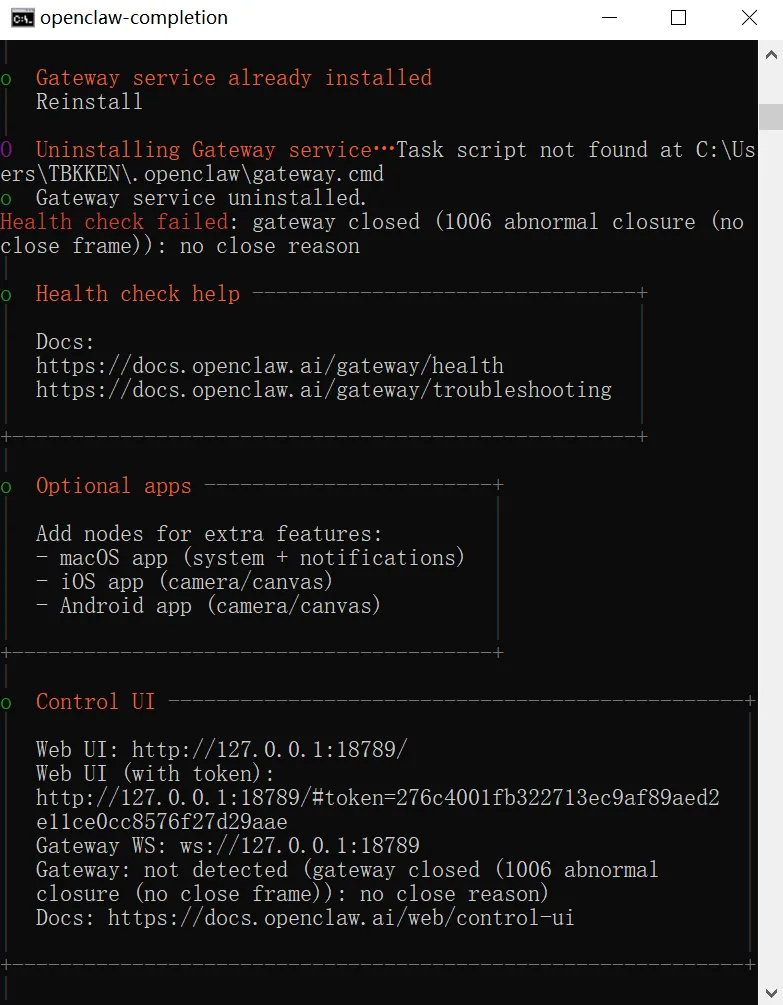
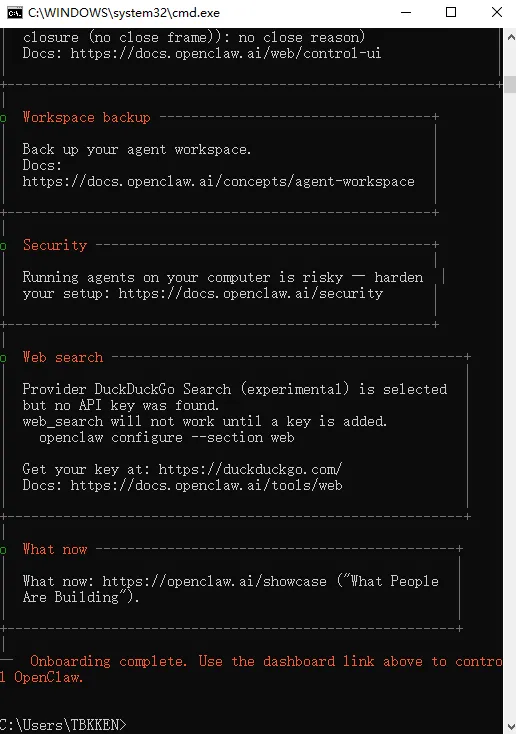
至此,OpenClaw 的基础配置,算是配置一半了,接着来配置 飞书 的另外一半接入。
八、Feishu 真正打通前,系统会先进入一个非常明确的"待批准"状态
很多集成系统最难受的一点,是没配通的时候你根本不知道卡在哪。我们在飞书里面,给我们的小助手发个消息,你会发现,它给你发送了一串代码,如下图所示:
Feishu pairing code 已生成,但 access 尚未配置
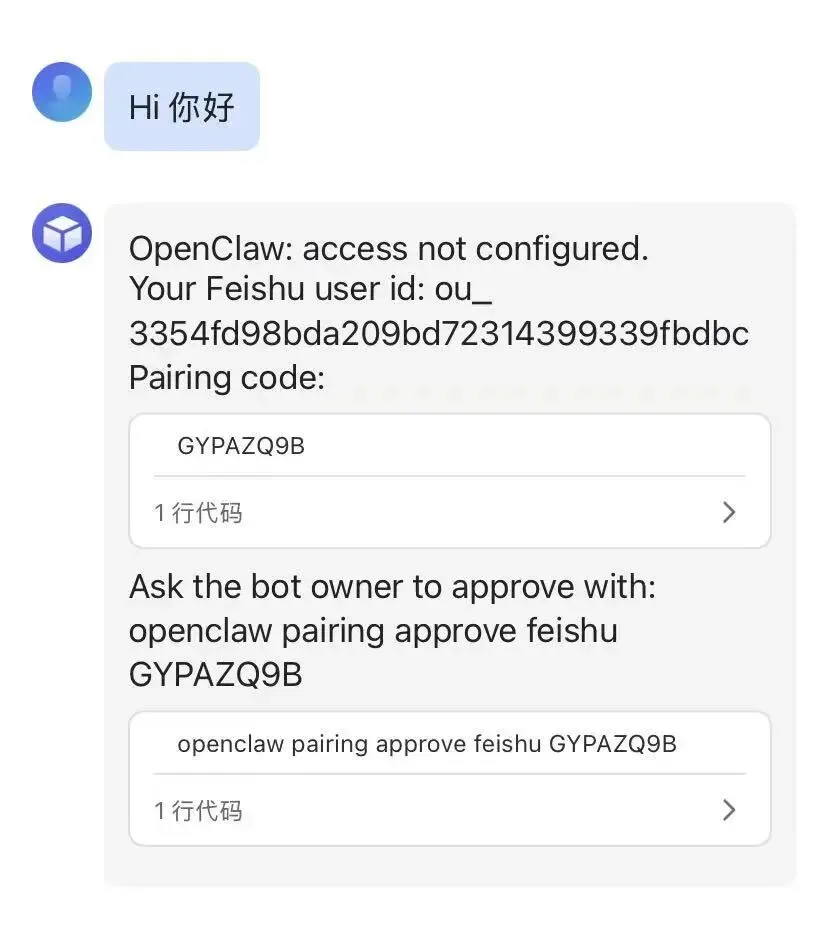
从图里可以确认:
OpenClaw 已经拿到了 Feishu user id 系统生成了 pairing code 并明确提示需要 bot owner 执行 approve
这就很重要了。
因为到这一步,问题已经被缩小得非常精确:
不是 OpenClaw 没启动 不是飞书插件没加载 不是网络连不上 而是 访问授权还没有完成
这一阶段给人的掌控感,来自"问题被说清楚了"
很多系统在失败时只会给你一种含糊感。
但这里不是。
OpenClaw 直接把当前状态翻译成了可操作的下一步:
pairing code 已生成,下一步就是让 bot owner 批准配对。
这会极大减少排查成本。
接下来的一张图,才是整个接入链路真正闭环的证据。
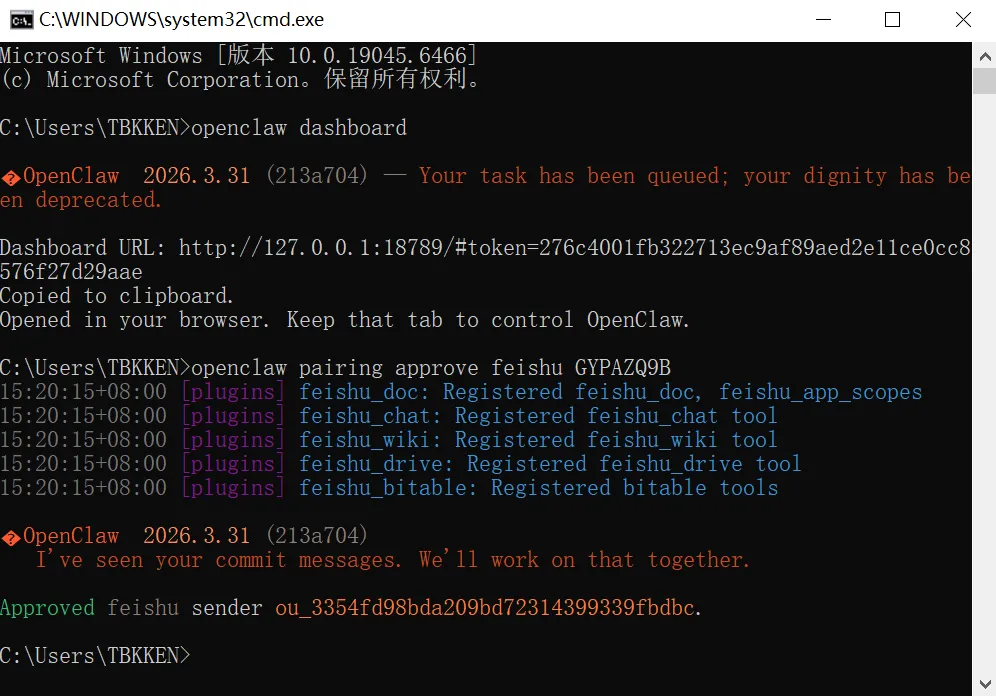
这张图里同时出现了三个重要信号。
1)Dashboard 已经正常起来
这意味着本地控制面是活的。
2)执行了明确的配对批准命令
openclaw pairing approve feishu GYPAZQ9B这一步不是模糊点选,而是清晰、可审计、可复现的命令式授权。
3)相关 Feishu 插件开始批量注册
截图里能看到一组典型条目:
feishu_docfeishu chatfeishu wikifeishu_drivefeishu bitable
这一步意味着什么?
意味着你接入的不只是"一个能收消息的入口",而是一整套 Feishu 生态能力开始挂进 OpenClaw。
到这里,系统形态才真正发生质变:
前面还是"本地可配置框架" 到这里才变成"真正可在飞书里工作的助手系统"
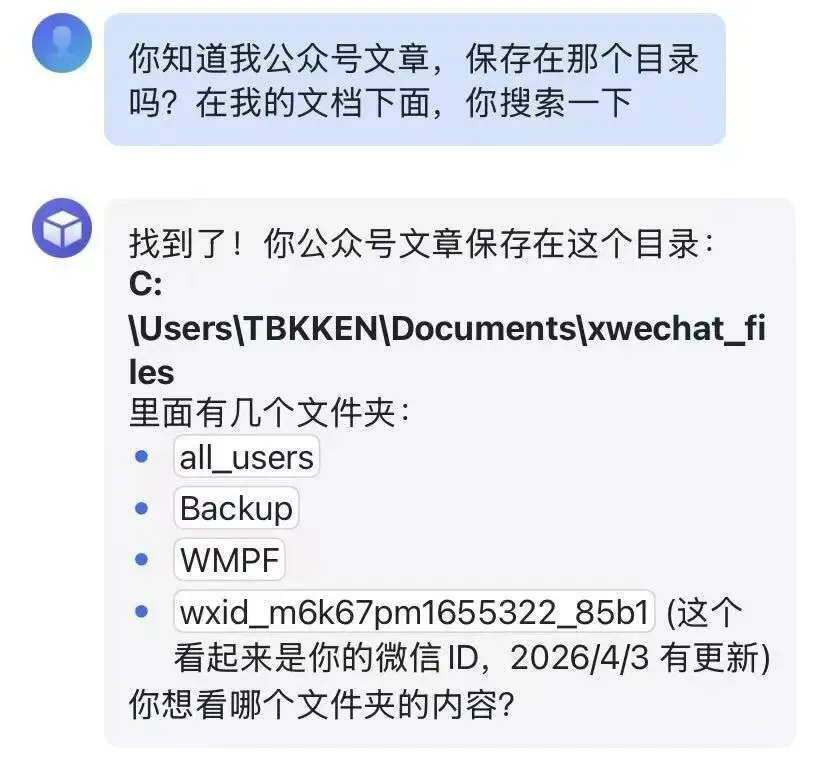
这样子,飞书就可以正常工作了。
九、总结
如果只看"怎么操作",那这篇文章当然也可以被写成:
进入目录 配模型 onboard 接飞书 approve 完成
但那样写,读者学到的只是动作。
我更想强调的是背后的方法:
把 OpenClaw 的配置过程,当成一个可追踪、可提交、可回退的软件系统演进过程。
这样做的好处非常直接:
你不会越来越依赖记忆 你能看懂每一步改了什么 你知道哪些变化来自自己,哪些来自系统 你出问题时更容易定位 你以后扩展渠道和技能时也更从容
对长期使用 AI 系统的人来说,这种掌控感比"今天终于配通了"更有价值。
十、最后给一个最实用的建议:别追求"一次配完",而要追求"每一步都可回退"
如果让我把这次过程压缩成一句建议,那就是:
不要追求一次性把 OpenClaw 全配完,而要追求每前进一步都知道怎么退回来。
具体落地很简单:
把 .openclaw视作配置仓库每完成一个步骤就看一次 git status不要无脑 git add .分清配置文件和运行态文件 遇到 Config overwrite这类阶段边界时做一次 commit接入模型、技能、渠道时,优先看文件变化而不是只看界面提示
这样你得到的,就不只是一个"能聊天的 OpenClaw"。
而是一套:
你看得懂 你管得住 你改坏了也回得去 你能长期迭代
的 AI 助手系统。
结尾
如果只把 OpenClaw 当成一个聊天壳子,那它当然也能用。
但如果你把它放进 Git、把每一步配置都当成一次系统演进来看,事情就完全不一样了。
你得到的,不只是一个助手。
而是一套真正属于你、并且可以长期维护的 AI 工作系统。
