 夜雨聆风
夜雨聆风
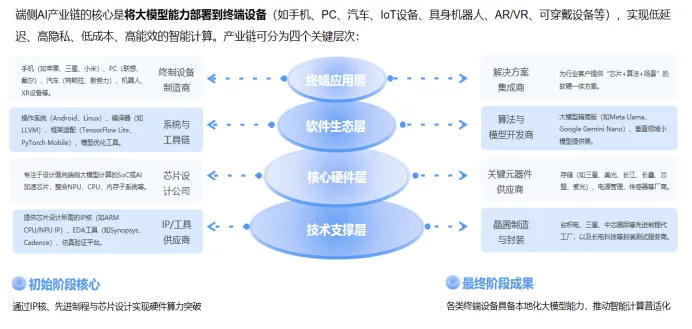
端侧 AI 算力核心:NPU 技术与应用
近年来,AI计算主要依赖云端集中式算力,通过将大量数据上传至云端处理后再回传终端完成任务交付。虽然该模式在大模型训练和非实时任务中具有显著优势,并便于集中调度与优化算力资源,但随着AI应用场景扩展,其局限性逐渐显现,尤其在延迟、数据安全与隐私保护,以及带宽和成本方面存在制约。因此,将算力下沉至终端成为发展趋势。
然而,现有端侧传统芯片在处理AI任务时仍面临两大技术困境:
1.存储墙:传统冯诺依曼架构中,计算单元与存储分离,数据传输带宽受限,计算单元容易空转,限制芯片整体性能。
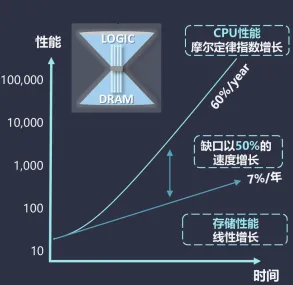
图1 冯诺依曼架构
2.功耗墙:功耗直接制约终端设备的续航、便携性及应用场景拓展。采用异构集成方案,可在同等功耗下实现更优性能,或在同等性能下异构集成能耗最低。
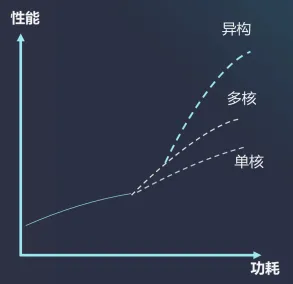
图2 功耗性能对比图
为突破这些瓶颈,端侧AI NPU应运而生。通过定制化架构设计,NPU在终端提供高效算力,同时与云端协同处理复杂计算任务,实现低延迟、高效能和安全可控的算力服务,为端侧智能化应用提供持续支撑。
一、端侧AI NPU概念与发展
端侧AI NPU(Neural Processing Unit)全称为神经网络处理器,是专为低功耗加速AI推理而打造的硬件模块,其运行原理是利用电路模拟人类的神经元和突触结构,通过标量、向量和张量数学运算组成的神经网络层计算以及非线性激活函数执行AI相关的计算任务。
相比之下,传统CPU擅长顺序控制,负责读取、解释、执行计算机指令;GPU擅长并行数据流处理,针对通用图形渲染进行优化;而NPU则专注于AI推理的数学运算。将NPU与存储器、通信接口及传感器接口整合后,即可形成支持多样性异构计算的端侧SoC,为智能终端提供高效、低延迟的AI算力。
特性 | CPU | GPU | NPU |
设计初衷 | 通用计算与系统控制 | 最初用于图形渲染,后扩展至并行计算 | 专用于神经网络计算 |
计算能力 | 强顺序处理能力,低并行度 | 强并行计算能力,适合大规模数据处理 | 高效神经网络推理能力(张量运算优化) |
灵活性 | 极高,支持各种通用任务 | 较高,可编程实现多种并行任务 | 较低,针对AI模型专用优化 |
能效比 | 较低 | 中等 | 高(针对AI任务优化) |
典型应用 | 操作系统控制、逻辑运算、通用程序 | 图形渲染、AI训练/推理、科学计算 | 深度学习推理、边缘计算、实时AI处理 |
部署位置 | 端侧与云端通用 | 主要在云端,也逐步进入端侧 | 主要在端侧(手机、IoT、车载等) |
二、端侧AI NPU技术路线与性能优化
近存计算(Near-Memory Computing)成为突破上文所述“存储墙”、“功耗墙”瓶颈的核心架构方向,通过减少计算与存储间的往返传输,从架构层面缓解带宽压力、降低能耗。
3D DRAM 近存计算技术则是实现高效近存计算的关键物理路径。通过垂直集成计算与存储,大幅缩短数据通路、提升带宽、降低延迟,为近存计算提供硬件支撑,充分释放现有算力。在此架构下,端侧 NPU 的性能优势集中体现为三点:能效提升;数据通路缩短,实时推理能力显著增强:缓解计算单元空转,有效释放潜在有效算力。
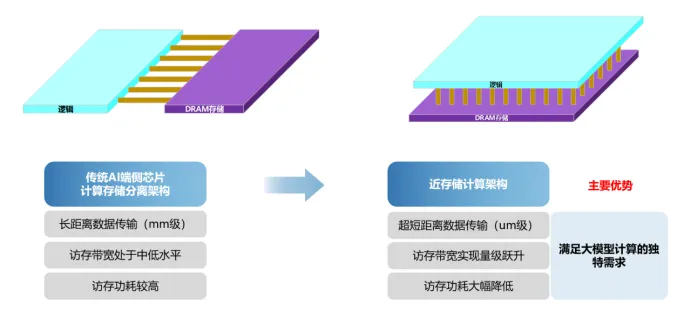
端侧 NPU 的演进并非单纯堆叠算力,而是以近存计算为架构目标、3D 堆叠为核心实现手段,通过重构计算与存储的协同关系,在功耗约束下实现系统效率最优 —— 这正是当前端侧 AI 芯片竞争的技术焦点。
三、华为 vs 瑞芯微端侧 NPU
端侧 AI NPU 产业呈现多元化发展格局,不同厂商侧重点各异,但都围绕端云协同、算力与成本优化展开。目前市场上比较成熟的产品代表包括:华为昇腾 310B ,其代表“高算力+端云协同”的技术路径,强调复杂模型的端侧延伸与生态协同能力;瑞芯微 RK3588则体现“低功耗+成本优化”的产品路线,更适配大规模边缘设备的普及需求。两者在端侧 AI 市场形成差异化分工,共同推动端侧智能的规模化落地。
芯片 | 核心性能 | 端云协同 | 成本/功耗 | 技术特点 | 定位 |
华为 昇腾 310B | 8-16 TOPS,低功耗端侧 | 支持云-边-端协同,依托昇腾生态 | 功耗较低,成本较高 | 异构架构,支持FP16/INT8/BF16 | 高算力端侧,适合复杂 AI 推理 |
瑞芯微 RK3588 | 4 TOPS,功耗 <1W | 侧重端侧独立运行 | 超低功耗,成本优势明显 | 集成式NPU,整数运算优化 | 低功耗部署,适合轻量化场景 |
四、行业应用
端侧AI NPU的落地赛道,精准锚定智能时代终端设备的智能感知与推理需求,覆盖三大万亿级高速增长市场:
1.智能驾驶:作为车载感知层核心硬件,NPU 支撑座舱内 DMS/OMS 感知、自动驾驶 ADAS 视觉识别,每辆智能车都是多颗端侧 AI 芯片的集成体,为行车安全与智能交互提供低延迟算力;
2.AIoT 与消费电子:下一代 AI 手机的端侧大模型运行、AI PC 的本地智能计算、AR/VR 眼镜的沉浸式交互,都离不开 NPU 的赋能,它正成为这类终端的基础标配;
3.智能制造:具身智能、工业机器人的实时决策,智能安防的本地化识别,无人机巡检、设备预测性维护的精准分析,对可靠性和实时性要求极高,是端侧 AI NPU 的天然应用战场。
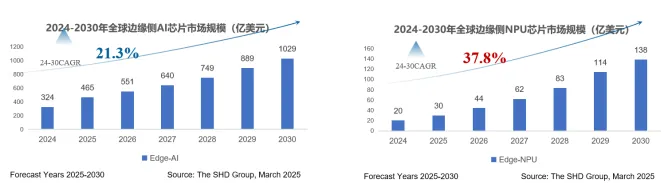
据行业预测,2025年中国边缘AI芯片市场规模将达438亿元,2030年有望突破千亿元,年复合增长率约19.1%,显示出广阔发展空间。
五、苏州元涌科技--端侧NPU的引领者
恒邦天使轮投资企业--苏州元涌科技有限公司(简称“元涌科技”),专注终端侧 AI NPU 协处理芯片研发,公司依托 3D 堆叠近存计算与芯联计算架构,为大模型在终端高效、低功耗运行提供核心支撑。
公司由南京大学林军博士领衔创立,核心成员涵盖多名通信与芯片行业资深专家。团队发表论文100余篇,申请发明专利90余项,完成多次流片验证,自主NPU IP核性能实测达标,积累3D堆叠封装工艺经验,率先跨越从理论到产品的鸿沟。
当前全球边缘端侧 NPU 芯片市场规模已达 30 亿美元,预计至 2030 年复合增长率达 37.8%,行业迎来高速发展期。在此背景下,元涌科技加快商业化进程,积极拓展产业合作:一方面相关科技公司推进测试与开发板联合研发,另一方面与上下游供应链伙伴深化合作,不断夯实生态基础,完善上下游产业布局。更为关键的是,公司在供应链层面已实现设计、制造、封装全链条国产化,能够有效规避地缘政治风险,进一步筑牢发展安全屏障。
随着端侧 AI 需求持续爆发,元涌科技不仅具备强劲的商业化潜力--能够带动上下游产业链发展、创造高端就业岗位--更在突破芯片关键技术、保障国家算力安全、助力 “双碳” 目标与数据隐私保护等方面兼具重要社会价值,是算力自主创新赛道的关键力量。

端侧 AI NPU 技术重构了 AI 底层算力架构,“云 — 边 — 端” 协同已经成为行业必然趋势。随着人工智能全面爆发,叠加智能驾驶、AIoT、消费电子、机器人等下游应用持续渗透,端侧 AI NPU 市场已正式进入产业爆发期,技术成熟度、市场需求与供应链能力形成共振,正是资本布局的黄金窗口期。
恒邦资本基于对端侧AI产业链的长期深入研究,精准投资了由南京大学林军教授领衔的团队——苏州元涌科技有限公司,目前,元涌科技已具备清晰的技术壁垒、已验证的流片成果、头部客户合作基础及全链条国产化供应链,新一轮融资正在陆续启动。
恒邦资本(全称“深圳前海恒邦股权投资有限公司”)成立于2016年5月,为深圳市私募基金商会副会长单位,深圳金融商会上市公司专委会会长单位,大湾区碳中和协会副会长单位,深圳市氢能与燃料电池协会会员单位,于2021年4月获评深圳“2020年度最佳新锐投资机构”,2022年获评“氢天奖-卓越投资机构”,2024年获证券时报“2024创投金鹰奖年度新势力机构”,2025年获证券时报“2025创投金鹰奖年度早期投资机构”。恒邦资本专注于新一代信息技术、新能源新材料、人工智能与大数据、大健康四大领域,立足粤港澳大湾区、辐射全国,投资足迹遍布中国十余个城市。覆盖企业全生命周期投资,陆续完成了亿道信息、云天励飞、中科闻歌、银河水滴、中科亿海微、世冠科技、宸境科技、中科富海、国鸿氢能等多家硬核科技类企业的投资。管理团队拥有十余年的投资管理经验,来自于中科院、摩根士丹利、瑞银、中银香港资管、平安银行、光大银行等多家行业知名企业,行业资源丰富,管理规模增长迅速。依托强大的管理团队及科学严格的风控体系,恒邦资本已逐步成长为业内有一定知名度和影响力的创投企业。
本文版权归“恒邦资本官方微信号”所有,欢迎注明出处转载。
统筹:钟伟林

恒以致远 实干兴邦

欢迎关注我们的网站
