 夜雨聆风
夜雨聆风上一期最后,我们留了一个坑:
为什么很多个“假脑细胞”叠起来,AI 就突然变厉害了?
答案是:
光叠起来,还不够。
中间还差一个关键角色。
它听上去很技术,但你其实天天都见:
及格线。
一场考试,最关键的未必是分数本身
假设有两个学生。
一个考了 59 分。
一个考了 61 分。
如果只是看数字,他们只差 2 分。
但只要学校规定:
60 分及格。
事情就变了。
59 分,叫不及格。
61 分,叫通过。
你会发现,真正改变结果的,不只是“加了多少分”,而是中间那条规则:
到线没有。
这条线,决定了系统怎么做下一步判断。
而在神经网络里,干这件事的,就是:
激活函数(Activation Function)。
上一期那些“评委”,如果只会加分,其实还是不够
上一篇我们把感知机讲成“会加权投票的评委”。
几个线索进来:
- 耳朵像不像猫
- 胡须像不像猫
- 轮廓像不像猫
然后每个线索分配不同权重,最后加总,得出一个分数。
这个思路没错。
问题在于:
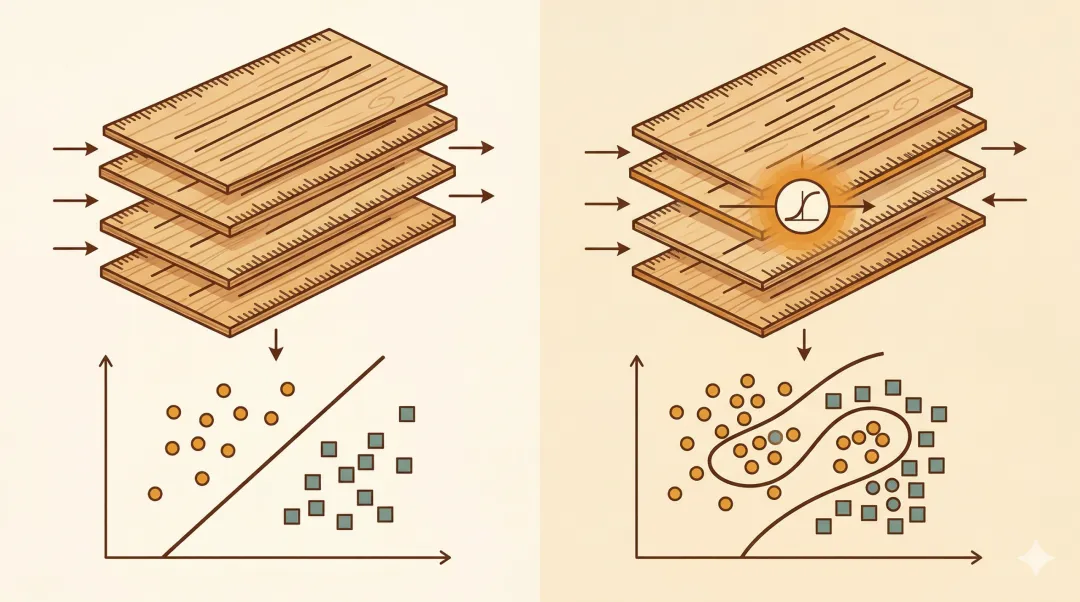
如果每一层都只是加权、求和、再把结果原样传给下一层,那你叠再多层,本质上也还是一次更复杂的加权求和。
说人话就是:
你以为自己请来了三位老师,分三轮打分。
结果他们做的事完全一样,而且中间没有任何“过线”“不过线”的判断。
那最后会发生什么?
三张评分表,还是可以压成一张总评分表。
看起来层数变多了。
本质上,还是那套直来直去的线性规则。
这也就是为什么,很多人第一次听到“没有激活函数,多层网络也没什么用”时,会觉得反直觉。
但它真的就是这样:
线性后面接线性,最后还是线性。
你把好几把直尺叠在一起,画出来的依然是直线。
所以激活函数到底干了什么?
它干的事情并不神秘。
你可以先把它理解成一句话:
每一层在把分数交给下一层之前,先按自己的规则处理一遍。
这个“处理”,就是激活。
比如:
- 分数太低,直接归零
- 分数过了线,才允许往下传
- 或者把一个很大的分数,压成 0 到 1 之间的“像不像概率”
这时候,网络就不再只是机械地做加法。
它开始在每一层,都做一次“判断”。
而一旦有了这种判断,整个系统就能开始“拐弯”。
这就是那个经常被提到、但很多人第一次听会有点懵的词:
非线性。
你完全可以先别管定义,只记一句人话:
非线性,就是 AI 不再只能拿着一把直尺看世界。
没有激活函数,AI 会笨到什么程度?
想象一下,你要训练一个 AI 分辨猫和狗。
如果没有激活函数,它很可能只能学出特别生硬的规则。
比如:
“体重超过 5 公斤的都是狗。”
或者:
“耳朵尖一点的更像猫,脸长一点的更像狗。”
听上去好像有点道理。
但现实世界不会这么配合你。
有的猫很胖。
有的狗也小小一只。
有的猫毛炸开的时候,看起来像个拖把。
有的狐狸远看还像猫。
如果模型只能用一条直来直去的规则分世界,它迟早会撞墙。
所以,激活函数真正重要的地方,不是“让模型多算了一步”。
而是:
它让模型终于有机会处理那些弯弯绕绕、没法一刀切的现实问题。
第一种老师:Sigmoid,温柔派的“像不像评分器”
讲激活函数,最经典的一位老前辈,叫 Sigmoid。

你可以把它想成一个特别温柔的老师。
它不会粗暴地说“行”或者“不行”。
它更像在说:
- 这题很不像,给你 0.02
- 这题有点像,给你 0.63
- 这题非常像,给你 0.97
也就是说,Sigmoid 很擅长把一个原本可能很大、也可能很小的分数,压缩成 0 到 1 之间。
这就特别像什么?
特别像一种“像不像”的感觉值。
所以在很多早期神经网络和二分类任务里,它很好用。
因为人类很容易理解这种输出:
越接近 1,越像;越接近 0,越不像。
它的曲线长得也很有特点,是一条平滑的 S 形线。
这条 S 形线背后的直觉,其实也很生活化:
一开始分数太低,怎么加都还是“不太像”;
到了中间区域,变化会突然变敏感;
再往上走,又慢慢接近“非常像”,但不会无限冲上去。
所以 Sigmoid 给人的感觉,就像一个会说:
“别急,我给你一个循序渐进的判断。”
但温柔也有温柔的问题
Sigmoid 很优雅。
可它也有一个现实问题:
太容易变得不敏感。
当输入特别大,或者特别小的时候,它的输出会越来越贴近两端。
这时候,你再怎么微调,变化都不大。
你可以把它想成一个老师改卷改久了,后面开始有点麻:
90 分和 95 分,在他眼里都差不多优秀;
5 分和 10 分,在他眼里也都差不多没救。
这会让后面的学习过程变慢。
于是,后来大家越来越喜欢一位更直接的老师。
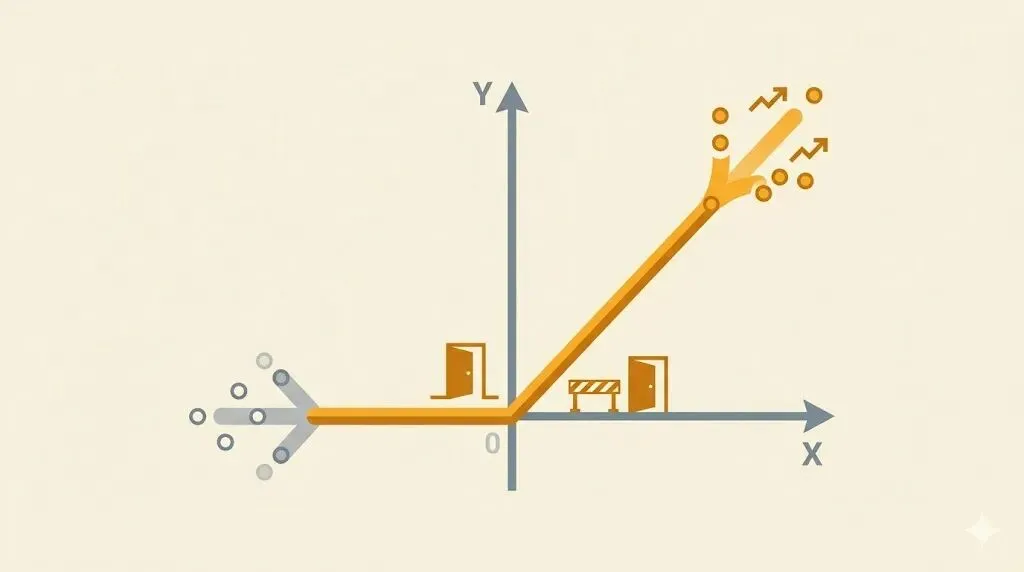
第二种老师:ReLU,不过线就归零
这位老师叫 ReLU。
它的风格和 Sigmoid 完全不一样。
你可以把它理解成一句非常干脆的话:
低于 0,直接按 0 算。
高于 0,多少分就照着多少分走。
是不是一下就有种“学校教导主任”的气质?
没过线?
回去。
过了线?
继续往下走。
ReLU 之所以后来越来越流行,不是因为它名字酷。
而是因为它真的很实用:
- 算起来简单
- 该砍就砍,不拖泥带水
- 正区间里又不会像 Sigmoid 那样那么容易“越学越没感觉”
你可以把它看成一个非常现实的筛选器。
很多信号到了这里,直接被掐掉。
剩下那些真正有用、真正过了线的信号,才有资格进入下一层。
所以 ReLU 的感觉不像“像不像评分器”。
它更像:
“先别跟我废话,先证明你值得继续往下传。”
所以,激活函数到底改变了什么?
现在我们把前面这些东西收一下。
没有激活函数的时候,神经网络就像一群只会加总分的老师。
层数再多,最后也还是一张总表。
有了激活函数之后,每一层都开始有自己的“判卷规则”。
于是,网络不再只是堆加法。
它开始在每一层做筛选、压缩、放行、拒绝。
这时候,“层”才真正有了意义。
所以激活函数并不是一个可有可无的小配件。
它更像是神经网络第一次学会说:
“世界不是非黑即白的一条直线,我得学会拐弯。”
不过,故事到这里还差最后一步。
现在你已经知道:
- 神经网络里有很多“假脑细胞”
- 它们会加权打分
- 中间还要靠激活函数设一道“判断线”
但新的问题又来了:
这些权重到底该怎么改?
AI 凭什么知道,胡须这票该更重一点,耳朵那票该轻一点?
下一篇,我们就来讲:
AI 怎么从「笨蛋」变「学霸」?
也就是它真正的学习方法。
