 夜雨聆风
夜雨聆风大家好,我是林潼。
今天想跟你们聊一个我经常用的命令:/status。
面对 OpenClaw,我们有两种输入命令的方式。
一种是在终端里敲,另一种更简单,直接在飞书、微信这些已经接好的聊天软件里发就行。
我慢慢发现,/status这个命令挺实用的。
它不光能告诉我 AI 现在是不是“活得好好的”,还能帮我根据状态调整用法,真正做到更省钱、更高效、更稳定。
不过说实话,我刚用的时候,也被那一屏信息吓到了。
版本号、Token、Usage……屏幕上突然冒出一大串英文和数字,直接懵。
程序员们可能对这些命令和英文代号已经被熏陶过,但我们非程序员,看着真的容易头大。
所以今天这篇文章,我就以一个非程序员的角度,把我的 /status 面板彻底讲给你听。
我会一条一条拆解,从四个方面来说:
内容解释:这一行到底写了啥? 运行机制:它背后在悄悄干什么? 实际意义:这对我有什么用? 使用建议:那我该怎么看、怎么调?
不管你是纯小白,还是刚入门的新手,看完这篇,你也能轻松看懂自己的状态面板,再也不用对着它发呆啦。
一、先搞懂:/status 面板到底是什么?
简单打个比方,/status就是我 OpenClaw 智能体的“实时仪表盘”。
就像开车时的中控台一样,它会把我 AI 当前的所有运行状态,清清楚楚摆出来,包括:
我用的 OpenClaw 是什么版本 AI 用的是哪个“大脑”(大模型),权限正不正常 这次对话花了多少 Token、多少钱 缓存用得好不好,记忆空间够不够 会话还剩多少时间,任务有没有堆积
能看懂这个面板,我就能更好去“掌控”我们的小Claw。
下面我就拿自己之前在飞书上发 /status 后,OpenClaw 返给我的实际内容为例,一条条拆给你看。
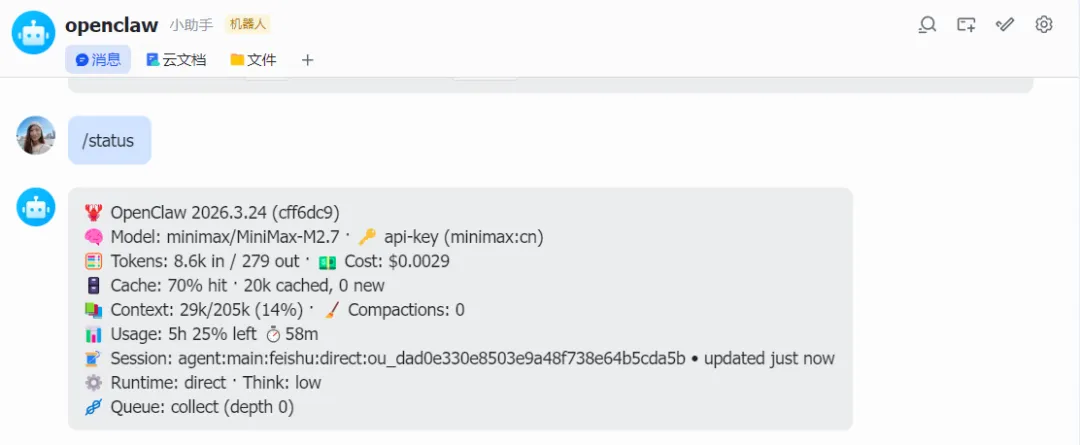
二、逐行拆解:/status 每条内容全解析
1. 🦞 OpenClaw 2026.3.24 (cff6dc9)
这是什么?
OpenClaw:就是OpenClaw这个智能体框架的名字。2026.3.24:是我当前运行的版本发布日期,2026年3月24日更新的。最新的我还没更。cff6dc9:这串叫“哈希值”,相当于这一版程序的唯一身份证号,全世界就这一个。
背后怎么运作的?
哈希值,我们一般用户不需要关心,程序员每次修改代码、修 bug、发布新版本会用,系统会自动生成这串哈希值。
它的作用就是精准定位某一版代码。万一出问题了,开发者凭这串号就能快速找到对应的版本来排查。
对我有什么用?
告诉我,我现在用的是 2026 年 3 月 24 日发布的稳定版,运行稳定,代码能追溯。
我该怎么做?
平时用得顺手,不用管它。如果哪天AI报错或者功能不正常,就可以把这个版本号和哈希值发给开发者,他们能更快帮我们解决问题。(目前我还没有遇到过)
2. 🧠 Model: minimax/MiniMax-M2.7 · 🔑 api-key (minimax:cn)
这是什么?
Model:就是我们接入的大模型,AI的“大脑”。
minimax/MiniMax-M2.7:我目前用的具体模型型号。
MiniMax也是咱国内的大模型公司,M2.7是他们的一款成熟模型,日常聊天、写文案、简单推理都挺好用。
这个模型据说是专门适配OpenClaw的。一个月29块,性价比比较高。
api-key:调用大模型的“钥匙”,用来验证权限和计算费用。
带 cn 后缀说明走的是国内接口
我们接入大模型或很多skill都是通过API收费的,以token计费,这也是为什么阿里还为此成立了以token为核心的组织。
背后怎么运作的?
OpenClaw 自己不会思考。它就像一个“调度员”。
我发指令给它,它拿着api-key去找 MiniMax的服务器,让M2.7这个大脑来思考、生成回答,然后再把结果返给我。
对我有什么用?
我的OpenClaw已经成功连上了MiniMax的M2.7模型,api-key有效,可以正常使用。
我该怎么做?
日常聊天、改文案、查信息、做总结,用 M2.7 完全够,速度快还便宜。如果要写代码、做复杂逻辑推理、算数学题、写长方案,我可以换成更强的大模型,回答会更准。如果遇到“权限错误”或“无法调用”之类的提示,也可以检查api-key是不是过期了。
3. 🧮 Tokens: 8.6k in / 279 out · 💵 Cost: $0.0029
一句话来说:本次对话:输入 8.6k tokens,输出 279 tokens
这是什么?
Token:大模型里的“字数单位”。大概 1000 Token 能换 700 到 800 个汉字。
8.6k in:我这次发给 AI 的内容,换算下来有 8600 个 Token,差不多 6000 到 6900 个字。
279 out:AI 这次回复我的内容,279 个 Token,大概 200 字出头。
Cost: $0.0029:这次对话的实际花费,不到3美分。
背后怎么运作的?
大模型是按 Token 收费的。我输得越多、它回得越长,花的钱就越多。OpenClaw 会帮我实时统计并算好账单。
对我有什么用?
这次我输入的内容比较长,但 AI 回复得短,整体只花了两分钱,很划算。
我该怎么做?
最好不要一次性扔一堆无关的长文本进去,那样既费钱又拖速度。想省钱的话,可以在指令里加一句“请简短回答”。连续对话时,历史记录会越积越多,Token 消耗也会上升。如果聊太久了,需要适时清理一下。
4. 🗄️ Cache: 70% hit · 20k cached, 0 new
一句话解释:70% 的输入命中了上下文缓存(便宜又快)
这是什么?
Cache:缓存,相当于 OpenClaw 的“临时记忆本”,存着我之前聊过的内容。
70% hit:缓存命中率。这次对话里,70% 的内容直接从缓存里读的,没麻烦大模型重新算。
20k cached:缓存里总共存了 20000 Token 的内容,大约 1.4 万到 1.6 万字。
0 new:这次对话没有新增缓存。
背后怎么运作的?
缓存的作用就四个字:提速、省钱。
OpenClaw有个"上下文缓存"机制:你之前发过的内容会被缓存起来,下次发类似内容时直接复用,不重新计费。这样又快又便宜,省token。
对我有什么用?
70% 的命中率很高,说明我的缓存用得很好,实实在在地帮我省了钱、提了速。
我该怎么做?
连续聊同一个话题、做同一类任务时,缓存收益最大,我就不动它。如果我突然换了个完全不同的新话题,比如从写文案切换到写代码,命中率会暂时降下来,这是正常的,不用紧张。如果想彻底重置 AI 的记忆,我会用 /clear 指令清空缓存。
5. 📚 Context: 29k/205k (14%) · 🧹 Compactions: 0
一句话解释是:对话历史占 205k context window 的 14%,还剩 86%
这是什么?
Context:上下文窗口,也就是 AI 的“短期记忆”。它能记住当前对话的总量。
29k/205k (14%):已经用了 29k Token,大约 2 万字,上限是 205k Token,大约 14 万到 16 万字,目前占了 14%。
Compactions: 0:上下文被压缩的次数,目前是 0 次。
背后怎么运作的?
AI 的记忆是有限的。快满的时候,系统会自动压缩(就是Compaction)旧内容,腾出空间,保证对话不“断片”。
占用率低的时候就不压缩,让 AI 完整记住所有内容。
一般是在接近 context 80-90% 左右自动触发Compaction,或者我们人为手动触发(对应的命令是/compaction)。
对我有什么用?
当前只用了 14%,所以AI 记忆非常充裕,能完整记住我之前聊过的所有内容,不会忘事儿。
我该怎么做?
我可以放心地长聊,不用担心 AI 忘了前面说的话。如果哪天占用率超过 80%,可以压缩或清理一下,免得 AI 因为记不住而答错。
清理前,我会记得把重要的内容先复制保存下来。
6. 📊 Usage: 5h 25% left ⏱️ 58m
一句话解释:用量包还剩 5 小时,按当前速度估计还能跑 58 分钟
这是什么?
Usage:当前会话的生命周期。
5h:我这个聊天窗口已经运行了 5 小时。
25% left:剩余可用时间比例。
58m:倒计时,还能用大约 58 分钟。
背后怎么运作的?
为了防止一个会话跑太久导致卡顿或者内存爆掉,OpenClaw 会给每个会话设一个时间配额。
时间到了,系统会自动重置这个会话,也就是清空上下文和缓存,但不会删掉历史记录。
对我有什么用?
我还有大约 58 分钟。之后这个会话会重置,我当前的对话状态会被清空。
我该怎么做?
重要的内容,比如文案、方案、代码,最好复制保存,不等重置了才后悔。倒计时剩10分钟左右的时候,我最好手动开个新会话,避免突然中断。如果要做长期任务,隔段时间就开新开会话,不让一个会话跑太久。
7. 📝 Session: agent:main:feishu:direct:... · updated just now
一句话解释:当前 session 标识:主 agent → 飞书 → 私聊
这是什么?
Session:当前会话的唯一 ID,一长串系统自动生成的字符。
updated just now:这个会话刚刚活跃过,说明我刚发完指令,AI 也刚回复完。
背后怎么运作的?
OpenClaw 可以同时开好几个会话,也就是多个聊天窗口。每个会话都有自己唯一的 ID,防止串线和混淆。
对我有什么用?
系统能正常识别我的会话,没串线,刚刚还活跃着,一切正常。
我该怎么做?
什么也不用做。这串 ID 是系统自己管的,我正常聊天就行。
8. ⚙️ Runtime: direct · Think: low
一句话解释:运行模式,direct=直接响应
这是什么?
Runtime: direct:直接运行模式。
Think: low:低思考强度模式。
背后怎么运作的?
direct 模式不经过额外封装,直接调用大模型,特点是速度快、资源消耗低。
Think 控制AI的推理深度,就和我们平时用的大模型一样有快速模式,和深度思考模式。
low 就是快速响应、不深度推理;high 就是多轮深度推理,回答更严谨,但速度会慢一些,也更费 Token。
补充一个点,OpenClaw的运行模式有两种:
direct:你直接跟我说话,我在实时响应;subagent:把我这个问题扔给另一个 AI agent 去处理,处理完再回来;目前是 direct,说明我问的每个问题都是直接回答的。
对我有什么用?
当前模式主打“快和省”,很适合我平时的日常使用。
我该怎么做?
日常聊天、润色文案、查信息、做总结,我保持现状就行,又快又省钱。
如果需要写代码、做复杂逻辑分析、或者处理专业问题,我会把思考强度调成 high,这样回答会更靠谱。
如果觉得变慢了,我就适当精简一下自己的提问。
9. 🧬 Queue: collect (depth 0)
一句话解释:队列状态,collect 是收集模式,depth 0 表示没有等待中的任务
这是什么?
Queue:任务队列,存放着待处理的指令。
collect:当前处于“收集状态”,正在等我的新指令。
depth 0:队列深度为 0,意思是一个排队的任务都没有。
背后怎么运作的?
AI 处理指令是按“先来后到”排队的。
depth 后面的数字越大,说明排队越多,响应就越慢。如果是 0,那就是完全空闲。
对我有什么用?
这时候我的 AI 完全闲着。只要我发个指令过去,它立马就能回复,一点延迟都没有。
我该怎么做?
现在是最佳状态,我可以放心发指令。
如果以后发现 depth 后面的数字持续大于 3,比如到了 4 或 5,说明我发得太快了,AI 处理不过来。这时候稍微放慢一点节奏就好。
三、整体状态总结
综合上面 9 条信息,可以很肯定地说:我当前的 OpenClaw 处于极佳运行状态。
✅ 版本稳定:2026.3.24 稳定版,运行没毛病✅ 模型正常:M2.7 模型连接成功,api-key 有效✅ 成本可控:一次对话才花两分钱,缓存命中率还高✅ 记忆充足:上下文只用了 14%,AI 不会忘事✅ 响应飞快:direct 模式加上队列是空的,指令发过去秒回✅ 模式适配:low 思考强度,日常用刚刚好
唯一需要注意的是:我的会话还剩大约 58 分钟。记得在到期前把重要内容保存下来,或者手动开个新会话。
最后
看完这篇文章,你是不是觉得 /status 也没那么可怕了?
其实它就像汽车的仪表盘。一开始看不懂那些图标,了解之后就明白了:哪个灯亮了该加油,哪个灯亮了该保养。
AI 也是一样。学会看状态,我们就能更好地“驾驭”它,让他帮我们干活啦。
以上就是今天的内容啦,如果对你有所帮助,欢迎转发,点赞,在看哦。欢迎关注我。
最近整理了一份10本AI经典电子书,需要的欢迎关注我,后台回复:AI电子书即可获取。
