 夜雨聆风
夜雨聆风⚡️ Hey 兄弟们!我是小帅 👋 今天给大家安利一个我花了 3 天撸出来的项目——全能数据处理工具箱!这玩意儿简直是数据分析师的救命稻草,帮你从繁琐的数据处理中解放出来!
📌 本文看点
项目起源
核心功能
技术实现
扣子技能
使用案例
未来规划
PROJECT ORIGIN
🚀 项目起源
事情是这样的 👇
上个月帮女神处理一份销售数据,结果被 Excel 折磨得怀疑人生:
😵 重复数据 删到眼瞎
😭 缺失值 填到崩溃
💀 图表 做得像狗啃的一样丑
那一刻我下定决心:一定要写一个工具,让数据处理变得像喝奶茶一样简单!
于是——【清洗你的 Excel!🤩】诞生了!
CORE FEATURES
💻 核心功能
输入 & 输出
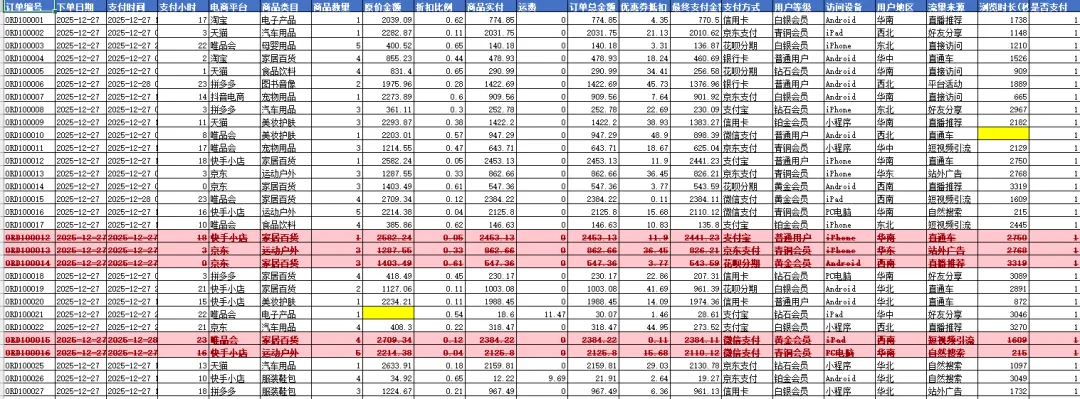
【清洗你的 Excel!🤩】工具,瞄准日常主要文件格式:CSV、Excel(*.xls、*.xlsx)、JSON,一个函数快速识别文件类型、导入、搞定:
# 无论什么格式,一个函数,完事!def load_data(self, file_path):"""通用数据读取"""file_path = Path(file_path)if file_path.suffix == '.csv':self.df = pd.read_csv(file_path)elif file_path.suffix in ['.xlsx', '.xls']:self.df = pd.read_excel(file_path)elif file_path.suffix == '.json':self.df = pd.read_json(file_path)print(f"✅ 数据加载成功: {self.df.shape[0]}行 × {self.df.shape[1]}列")return self.df
输出的 Excel 包含 4 个 Sheet:
📋 原始数据 | 🧹 清洗后的数据 | 🏷️ 清洗标记 | 📊 相关性矩阵

🧹 智能清洗黑科技
删除重复数据、填充缺失值、检测并修复异常值,基本上覆盖了日常数据处理中90%以上的场景!
(1)一键去重
支持按指定列去重,再也不用手动筛选;比如:你可以指定 <姓名>、<年龄> 2个字段,只有当 <姓名>+<年龄> 一样时,才删除重复数据。
如果你没有指定列,那就当全部列值一样时才执行去重。
if subset is not None:# 用户指定列去重self.df = self.df.drop_duplicates(subset=subset)print(f"🧹 按列 {subset} 去重: 删除{duplicates}条重复值")else:# 默认全部字段去重self.df.drop_duplicates(inplace=True)print(f"🧹 按全部字段去重: 删除{duplicates}条重复值")
(2)智能填充
数值类型的列(如:int、float)自动用中位数填充,其他数据类型的列用众数。
for col in self.df.columns:if self.df[col].dtype in ['int64', 'float64']:self.df[col] = self.df[col].fillna(self.df[col].median())else:self.df[col] = self.df[col].fillna(self.df[col].mode()[0])
(3)异常值检测
用 IQR 或 Z-score 方法定义值边界,清洗异常值
if method == 'iqr':Q1 = self.df[column].quantile(0.25)Q3 = self.df[column].quantile(0.75)IQR = Q3 - Q1self.df = self.df[(self.df[column] >= Q1 - 1.5 * IQR) & (self.df[column] <= Q3 + 1.5 * IQR)]elif method == 'zscore':z_scores = np.abs((self.df[column] - self.df[column].mean()) / self.df[column].std())self.df = self.df[z_scores <= 3]
(4)保留<清洗标记>
小帅我想得挺周到,专门输出一个 Sheet,保留清洗标记:
🏷️ 删除的重复行,标<红色底纹>+<删除线>
🏷️ 填充的空值,标<黄色底纹>
哈哈哈,是不是很贴心鸭~~~ 😂
🏷️ 打标签神器
在数据处理中,有时你是不是想给某些字段打上标签🏷️?
比如:给年龄打标签,30岁以下叫小鲜肉、30~45岁叫轻熟男、45~60岁叫大叔。
没问题,给你搞定:
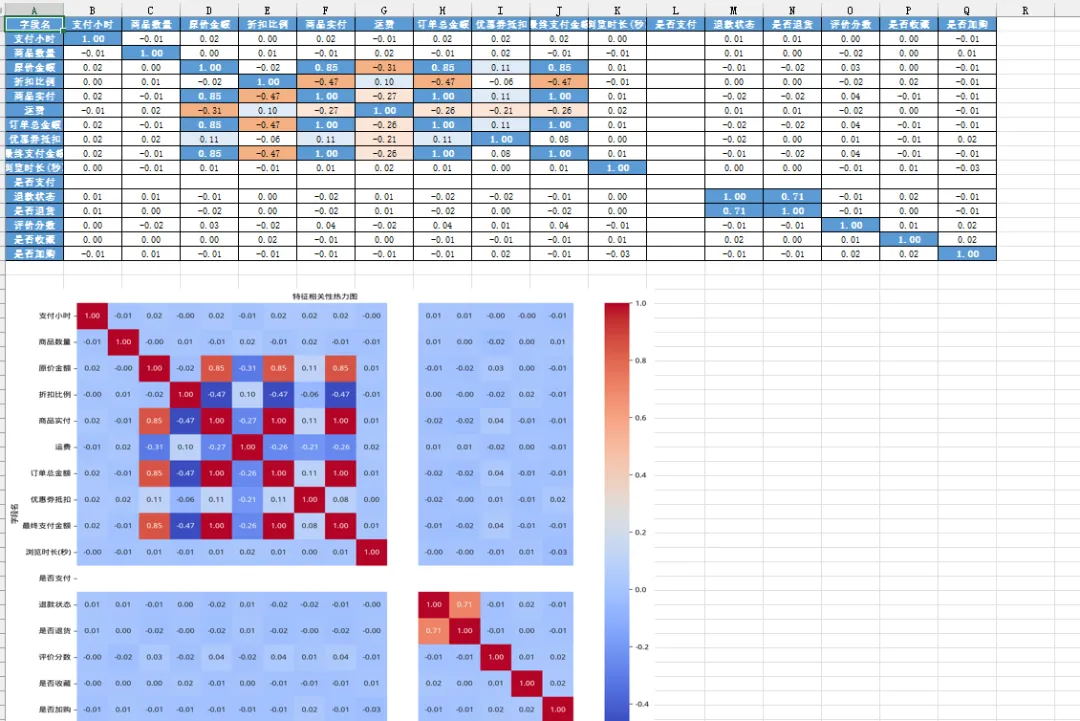
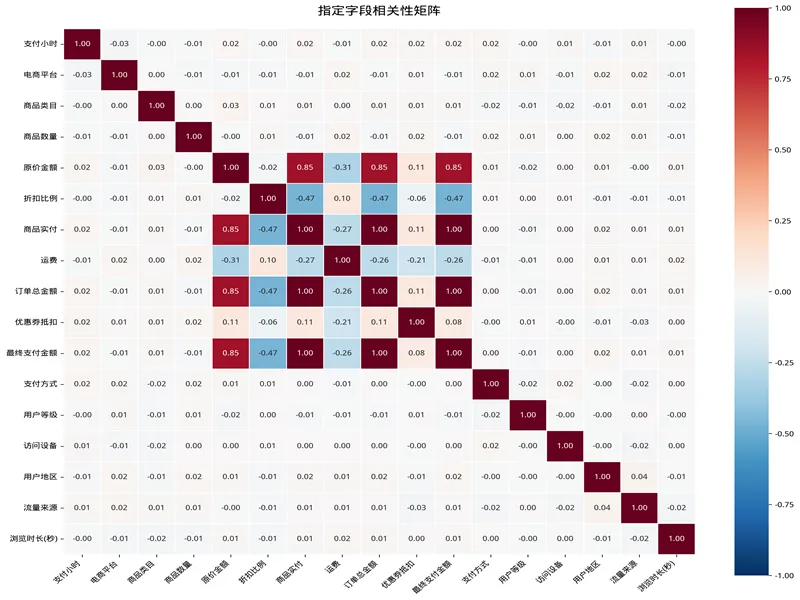
transformer.transform_data(bin_column='年龄',bin_bins=[0, 30, 45, 60, 100],bin_labels=['小鲜肉', '轻熟男', '大叔', '老爷爷'])📊 相关性矩阵热力图
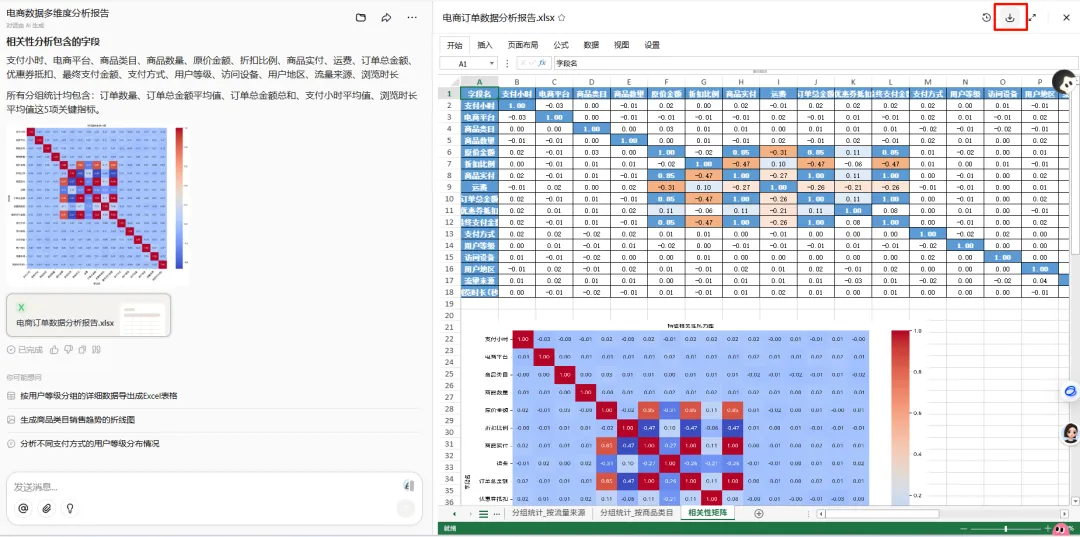
找出数据中的关联关系,生成相关性矩阵热力图!
📝 生成美观报告
生成的 Excel 报告还是挺专业滴,哈哈:
✅ 宋体9号字,专业感拉满
✅ 表头蓝色底色,颜值爆表
✅ 重复行红色删除线,一目了然
✅ 填充值黄色加粗,清晰醒目
✅ 相关性热力图自动插入,高级感爆棚
TECH STACK
🛠️ 技术实现
我采用了超清晰的模块化设计:
data_processor/
├── io_utils.py # 数据读写
├── cleaning.py # 数据清洗
├── transformation.py # 特征工程
├── analysis.py # 数据分析
└── visualization.py # 数据可视化
每个模块独立工作,想用哪个用哪个,简直不要太方便!
COZE SKILL
💡 封装成扣子技能
做开发我一直认准一个核心原则:一定要让大家用得够爽! 😜
直接跑代码咱们程序员轻轻松松,但零基础小白看着就头大,门槛直接拉满 😭
所以我直接把代码打包封装,做成 Coze 扣子专属技能啦~
不用敲代码、不用懂技术,全程打字对话就能直接用!!
简单又省心,小白也能轻松拿捏 ✅
USE CASE
🎯 使用案例
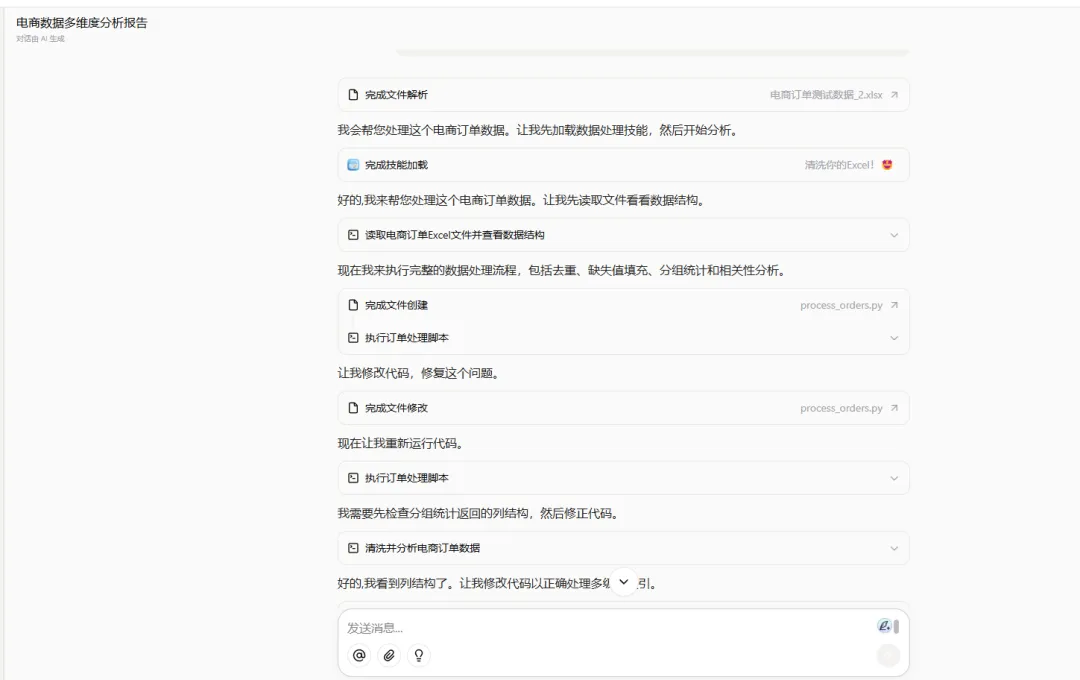
这里举一个处理电商订单数据的实例,就4个步骤:上传原始数据文件、Say你的需求、等待、下载处理后的文件。
Step 1-2:上传原始文件、说需求
这里的原始数据文件是一个4000多行的电商订单数据集,包含字段:订单编号、下单日期、支付时间、电商平台、商品类目、金额、折扣、支付方式等,还是有点儿复杂的
上传文件后,说出你的处理需求:

需求列表:
需求1、去重:按照【订单编号】、【下单日期】、【支付时间】去重。
需求2、填充空值。
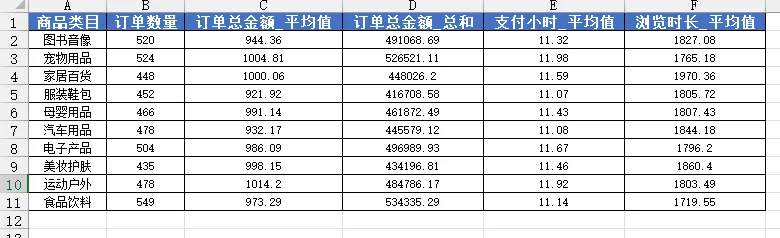
需求3、以【用户等级】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求4、以【电商平台】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求5、以【支付方式】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求6、以【用户地区】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求7、以【流量来源】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求8、以【商品类目】作为分组,计算【订单编号】数量、【订单总金额】的平均值与总和、【支付小时】的平均值、【浏览时长(秒)】的平均值。
需求9、生成相关字段的相关性矩阵。
Step 3:等待处理中
系统收到你的需求和文件后,会进行分析,然后开始处理,你只需要安静等待就好啦~~~ ☕
Step 4:处理完成后,就可以下载生成好的文件啦
ROADMAP
🚀 未来规划
这个工具还在不断进化!未来计划:
🔧 添加更多数据处理算法
📈 支持更多可视化类型
🤖 实现自动化报告生成
🧠 集成机器学习功能
🌟 最后说两句
兄弟们,这个工具真的改变了我的数据处理方式!
从前需要几小时的工作,现在几分钟就能搞定,简直不要太爽!
如果你也被数据处理折磨过,不妨试试这个工具,相信你会回来感谢我的 💪
我是 AI 小帅超会玩
带你解锁更多 AI 黑科技!🤖✨
如果你觉得今天这篇有收获,欢迎 点赞 · 在看 · 转发 三连
我们下期不见不散~👋🏻
