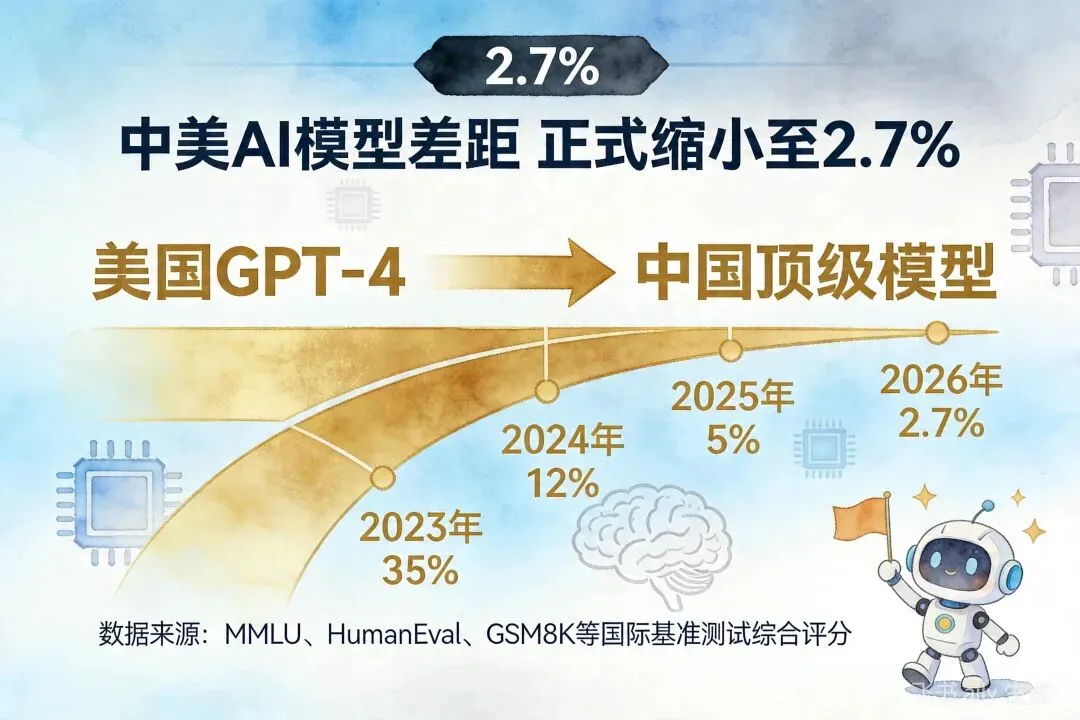
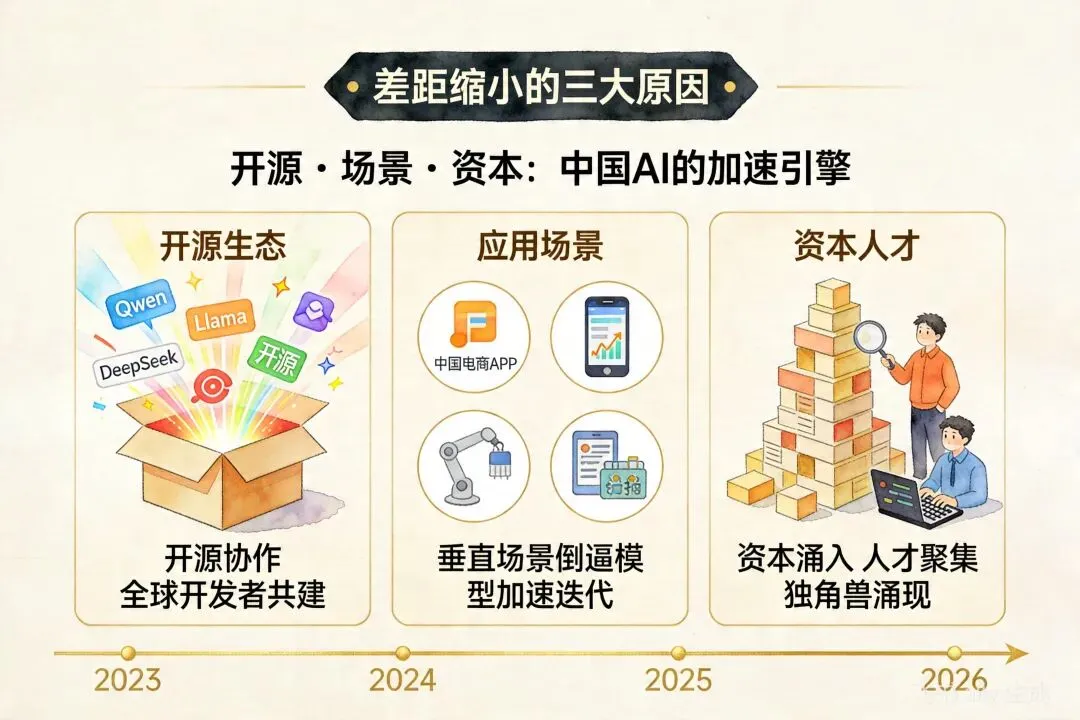
斯坦福2026 AI指数报告:中美学模型差距缩小至2.7%,阿里跻身全球前三这份报告,可能是中国AI最扬眉吐气的一份"成绩单"。4月18日,斯坦福大学正式发布《2026年人工智能指数报告》。这是一份年年发布、年年刷屏的行业"体检报告"。但今年,有两个数字格外刺眼:中美顶级AI模型综合性能差距:仅剩2.7%阿里巴巴:位列2025年全球顶级模型贡献榜第三名2.7%这个数字,放在一年前还是两位数,放在三年前是三四十个百分点。如今,它意味着:在最前沿的AI模型层面,中国和美国,已经基本站在同一条起跑线上了。2.7%,意味着什么?先搞清楚这个数字是怎么算出来的。斯坦福AI指数报告,采用的是MMLU、HumanEval、GSM8K等多项国际主流基准测试的综合评分,对全球主要大模型进行横向对比。2.7%的差距,指的是:在综合性能维度上,中国最顶尖模型的得分,与美国最顶尖模型的得分,相差不到3个百分点。这是什么概念?做个类比:高考总分750分,2.7%的差距相当于不到20分的分差。放到实际使用中,这个差距几乎感知不到——一个能做的任务,另一个也能做。更关键的是,这个差距还在继续收窄。阿里:全球第三,中国第一报告同步发布了"2025年全球顶级模型贡献榜"。阿里巴巴,凭借通义千问(Qwen)系列模型的持续迭代和国际影响力,位列全球第三,仅次于OpenAI和Anthropic。这是中国公司第一次,在全球模型贡献榜单上,杀入前三。阿里达摩院的Qwen系列,是近年来开源社区最活跃的大模型之一。从Qwen1.5到Qwen2.5,从百亿参数到千亿参数,每一代都引发全球开发者的关注和调用。斯坦福报告点名阿里,意味着:中国大模型,已经不是"追赶者",而是"贡献者"。差距缩小的背后,是什么在驱动?2.7%的数字,不是凭空出现的。它的背后,是三个结构性变化的叠加。第一,开源生态的爆发。Llama、Mistral、Qwen、DeepSeek……开源模型的质量在过去两年急剧提升。开源,意味着全球开发者共同参与迭代。中国公司的开源模型,在GitHub上的star数和fork数持续攀升,形成了真正的全球协作网络。第二,应用场景的倒逼。中国AI应用的广度和深度,在某些垂直领域已经超过美国。电商、短视频、智能制造、医疗影像——这些场景带来的真实数据反馈,让模型迭代有了"加速度"。第三,资本与人才的持续涌入。2025年,中国AI领域的融资规模和技术人才储备,依然保持着高增长。DeepSeek、智谱、MiniMax、月之暗面……一批批独角兽的涌现,形成了健康的竞争生态。2.7%,要不要太乐观?看到2.7%,有人兴奋,也有人提醒:别高兴太早。差距缩小的,是"综合性能"。但在具体维度上,情况并不均衡:纯文本推理、代码生成:国内模型已接近甚至局部超越GPT-4多模态理解、长上下文:与GPT-4V、Claude Opus相比,仍有追赶空间AI Agent、长程任务执行:Anthropic和OpenAI明显领先2.7%是综合均值,但均值之下,水面之下还有大量工作要做。此外,芯片算力的制约依然存在。H100/A100的获取成本,是悬在国内大模型公司头上的一把剑。对普通人的意义2.7%,不是一个学术数字,它的实际意义,体现在三个方面:第一,用AI工具的成本会越来越低。国内模型的竞争加剧,直接让API价格战打得越来越凶。Token价格一降再降,中小企业用AI的门槛越来越低。第二,国产替代的速度在加快。过去,很多企业用AI,第一反应是OpenAI、Anthropic。现在,越来越多的企业在评估:通义千问、DeepSeek、智谱——够不够用?答案是:越来越够用。第三,AI创业的土壤在变厚。模型差距缩小,意味着基于国产模型做应用开发的可行性提高了。不再需要担心"底座"不够强,应用的想象空间才能真正打开。写在最后斯坦福的这份报告,给了一个值得记住的数字:2.7%。但数字只是结果。真正值得关注的,是产生这个结果的机制——开源协作、应用倒逼、资本涌入、人才积累——这些加在一起,才是中国AI真正的底气。2.7%不是终点,它只是一个新起点。想要了解更多OPC创业玩法及第一时间获取AI Agent赛道一手动态,欢迎持续关注我们~ 👉 后台回复「入驻」"获取完整政策包,添加企业微信获取一对一创业咨询。让AI成为你的创业合伙人,一个人就是一支队伍。
 夜雨聆风
夜雨聆风