 夜雨聆风
夜雨聆风
PDF 处理一直是知识库和 RAG 系统里最容易低估的一环。
如果只是从普通 PDF 里抽取文本,pdfminer.six、pypdf、PyMuPDF 这类开源库已经够用。它们能把文本层读出来,速度快,依赖少,也适合做批处理。
麻烦在于,真正有价值的 PDF 往往不是简单文本。技术文档里有多栏排版和插图,论文里有公式和图表,财报里有跨页表格,扫描件可能根本没有文本层,拍照文档还会带来透视变形和阴影。到了 RAG、知识库、Agent 文件读取这些场景里,PDF 转 Markdown 的质量会直接影响后续检索、引用和推理。
当然,可以直接用视觉多模态模型处理这些页面。但 VLM 的部署成本、调用成本和工程复杂度都更高。很多时候,我们需要的不是一个通用视觉模型,而是一个能稳定把复杂文档还原成 Markdown 的 OCR 管线。
本地 PDF 处理工具的选择
本地处理 PDF,常见选择大致有三类。
微软的 MarkItDown 用起来最轻。处理 Word、Excel、PPT 这类 Office 文档时,它的体验不错;但面对 PDF,尤其是复杂 PDF,它基本只能提取文本层。标题层级、公式、表格、图片位置这些结构信息,很难指望它还原出来。原因也很直接:它的 PDF 能力主要依赖 pdfminer.six。
MinerU https://mineru.net 是上海人工智能实验室开源的文档解析工具,最初来自书生·浦语大模型预训练数据处理的需求。它支持图片、PDF、DOCX、PPTX、XLSX 等格式,PDF 解析效果很好,官方也提供了应用形态。代价是速度偏慢一些,本地部署模型通常需要 8GB 以上显存。
IBM 推出的 Docling 更像文档解析的瑞士军刀。它支持 20 多种文件格式,甚至覆盖音视频,LangChain 也已经默认集成。它的问题集中在 OCR 这一层:Tesseract、EasyOCR、RapidOCR 这类引擎更偏上一代 OCR,在复杂版面、公式、表格和多语种文档上能力有限;默认 VLM 引擎目前也不适合中文场景。
给 Docling 补上短板
Docling 的优势在于工程框架已经成熟:格式支持广,转换流程清楚,Markdown 导出也做得比较完整。更关键的是,它给 OCR 解析预留了扩展接口。
这就留下了一个很自然的改造空间:保留 Docling 的文档处理框架,把复杂 PDF 页面的 OCR 换成更强的模型。
正好我之前写过一个基于 GLM-OCR 的小应用,就顺手把 GLM-OCR 的处理流水线接进了 Docling。实际效果比原始 OCR 后端明显更好。
智谱开源的 GLM-OCR 是目前 PDF OCR 方向表现很强的一类专用模型。它覆盖的正好是 PDF 处理中最麻烦的几类内容:复杂排版、数学公式、表格、多语种和手写文本。模型本身也比较小,只有 0.9B,推理速度快,我的 Mac Mini 就能跑起来。
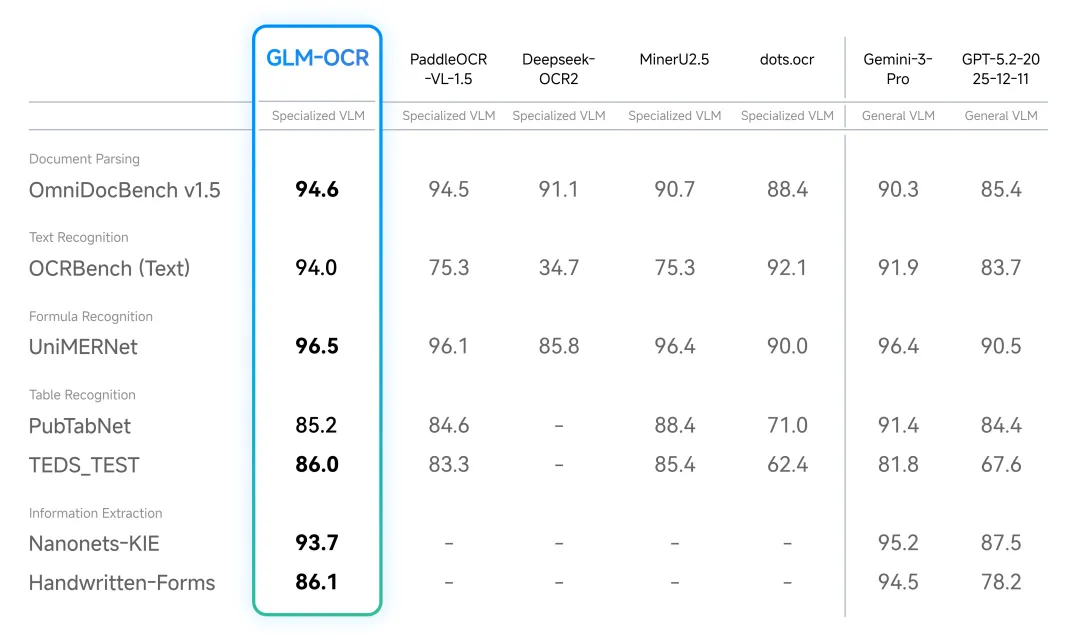
从 benchmark 看,GLM-OCR 在文档解析、文本识别、公式识别、表格识别、手写表单等任务上都有比较强的表现。相比通用 VLM,这种 OCR 专用模型的性价比更高,也更适合放进一个批量文档处理流程里。
这样一来,Docling 负责文件格式、流程编排和 Markdown 导出,GLM-OCR 负责复杂 PDF 页面的识别。两者组合之后,刚好避开了各自单独使用时的短板。
实测效果
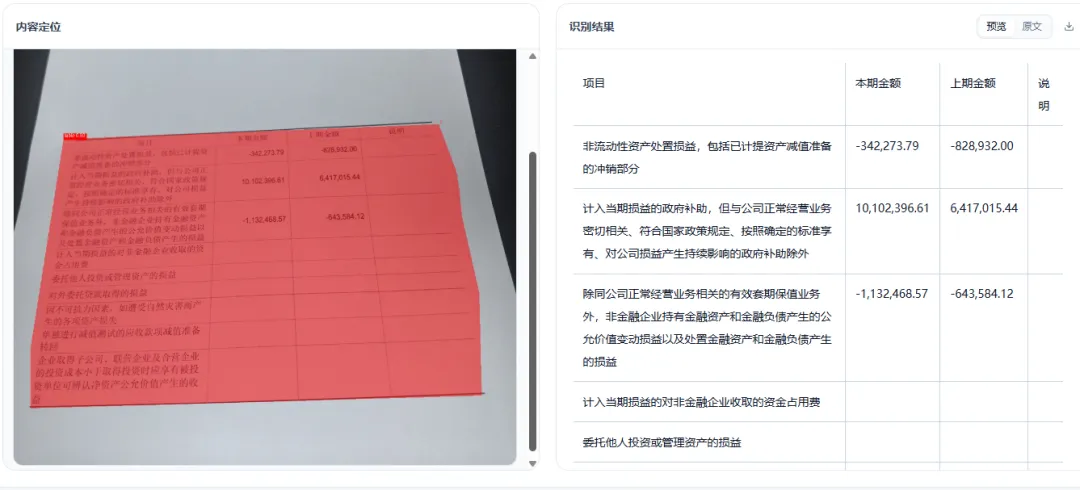
表格照片能保留基本的行列结构,适合财报、票据、拍照表格这类场景。
论文里的双栏排版可以按阅读顺序识别,数学公式也能转换成 Markdown 里可继续处理的形式。

手写内容只要字迹没有过度潦草,识别准确度也不错。

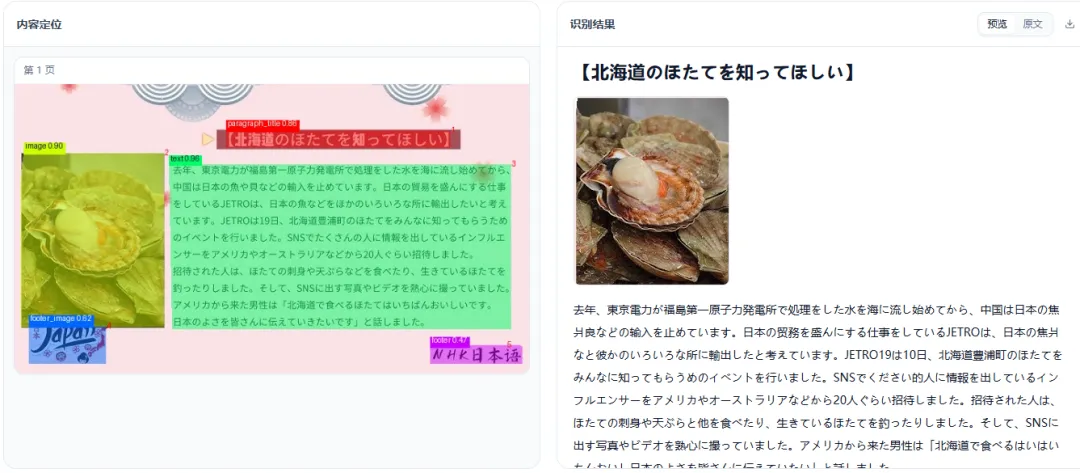
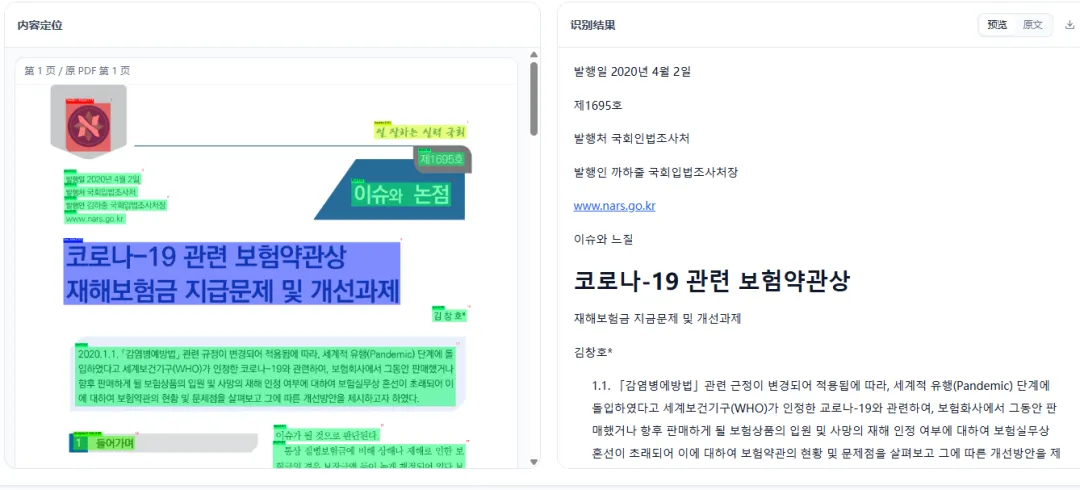
日文、韩文这类多语种文档,也能按版面顺序输出成 Markdown。
使用 Agent Skill 快速体验
如果你用的是 OpenClaw、Claude Code、Codex、OpenCode 这类 AI Agent 工具,可以直接安装这个 skill:
npx skills add https://github.com/ariesfish/docling/tree/main/skills/docling
安装后,直接提示 Agent 使用 docling glm-ocr 技能解析 PDF。它会自动下载模型并安装相关工具,用 Docling + GLM-OCR 的管线处理复杂 PDF。
如果你不想用命令行,也可以试试我的 ocr2md https://github.com/ariesfish/ocr2md 应用。它支持图片和 PDF,适合需要可视化检查结果的场景。
项目地址:
https://github.com/ariesfish/docling https://github.com/ariesfish/ocr2md
