 夜雨聆风
夜雨聆风两大方式让EXCEL自由调用Python代码
VBA虽然在表格处理领域有着举足轻重的作用,但是往往由于太原始了,所以在处理一些基础问题的时候经常需要手搓,比如排序,比如去重,这往往会浪费大量的时间,但是其毕竟是表格原生的语言,直接发送一个xlsm文件,用户也能成功执行
而python中内置很多关于表格处理的包,如xlwings,pandas等,其处理迅速,比如在处理上万行,上千个文件的时候,处理效率确实比VBA更快,但是由于不是“长在表格里的语言”,因此在某些问题上又不如VBA
因此将两者进行联动就显得非常重要了,让两个部分各自发挥自己最大的价值,其中一个很重要的工具就是 命令行,下面重点讲一下如何联动。
1. 通过命令行实现
方式1-1. python 的 sys 模块读取命令行
import sysdefmultiply(a, b):# 定义一个简单的函数,用于计算乘积return a * bif len(sys.argv) < 2: print("请提供至少一个参数") sys.exit(1) # 退出程序,返回错误码1else: print(sys.argv[0]) # 输出 worker.py print(multiply(int(sys.argv[1]), int(sys.argv[2])),end="") # 通过索引取值,输出计算结果现在我在命令行,这样写了一句运行命令:
python worker.py 5 6可以看到,参数之间都是由空格隔开的,因此从 python 之后的 worker.py 开始(这个是程序的名字),就是一个参数列表了,sys 就会读取这个参数列表,并存放,如果我们只写一句 print(sys.argv),那么可以返回一个列表:
['worker.py', '5', '6']因此我们上面的方式,通过索引取值,sys.argv[1] 拿到的就是5,sys.argv[2] 拿到的就是6,然后调用multiply 函数,就并计算结果,最后你能在命令行看到:
worker.py30当然,有的时候你可能不能立马在控制台看到输出,这个是因为
Python的 print()函数使用行缓冲输出内容先存储在内存缓冲区中 当缓冲区满了、遇到换行符或程序结束时,内容才会真正输出到控制台
所以你可以在 print 后面加上一个参数 flush=True,这个代表就是直接将结果立马输出到控制台。
方式1-2. VBA 调用 命令行执行python代码
我们已经知道可以通过命令行执行代码了,那如何通过VBA将命令行调用出来呢?比如我们要实现这样一个简单的需求:
从表格的A1和A2 单元格取值,然后执行python程序进行计算,将结果放到A3 单元格中:
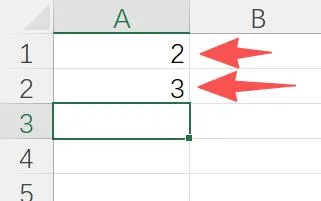
我们就可以运行底下这样一段VBA代码,然后就可以看到A3单元格中填入了数字 6。
Sub test() pyScriptPath = "D:\pythonProject\NewBegin\worker.py" '这里放Python代码的路径 Set objectShell = CreateObject("wscript.shell") '定义一个shell窗口 ' 下面的这个命令就是 python "D:\pythonProject\NewBegin\worker.py" 2 3 pythoncmd = "python " & """" & pyScriptPath & """" & " " & Range("a1").Value & " " & Range("a2").Value Set objExec = objectShell.exec(pythoncmd) 'exec方法可以把输出抓回来 result = objExec.StdOut.ReadAll() '获取所有的输出内容 Range("a3").Value = Replace(result, vbCrLf, "") '可能会有print输出的多余的空行,进行删除End Sub在上面的程序中,我们的 pyScriptPath 告诉VBA 程序在的位置,然后通过 CreateObject 创建一个窗口,发送命令,命令里面的四个引号代表的其实是一个双引号,pythoncmd等同于:
python "D:\pythonProject\NewBegin\worker.py" 2 3
然后我们通过objectShell.exec 构建一个对象,通过objExec.StdOut.ReadAll() 抓取python程序的输出,当然这里也可以使用run方法,只不过这样我们就需要先写入一个文档,然后再从文档里读,这样显然更麻烦。所以通过命令行的交互,我们知道了如何通过VBA调用python程序,但是调用前需要保证你本地:
有可以执行的python代码文件 有python的编译环境
2. 通过EXCEL插件实现
其实如果你有一些python使用xlwings或者pandas的经验,就可以将两个应用很好地融合在一起了,接下来我将演示如何通过xlwings 插件,将两者融合在一起。
方式2-1. EXCEL初始配置
首先打开你的EXCEL,注意需要在宏设置里面,勾选上启用VBA宏,以及信任对VBA工程的访问
打开 Excel,点击左上角的 “文件” (File) -> “选项” (Options) 点击左侧的 “信任中心” (Trust Center) -> “信任中心设置” (Trust Center Settings...) 点击左侧的 “宏设置” (Macro Settings) 勾选这一项:“信任对 VBA 工程对象模型的访问” (Trust access to the VBA project object model) 点击确定保存
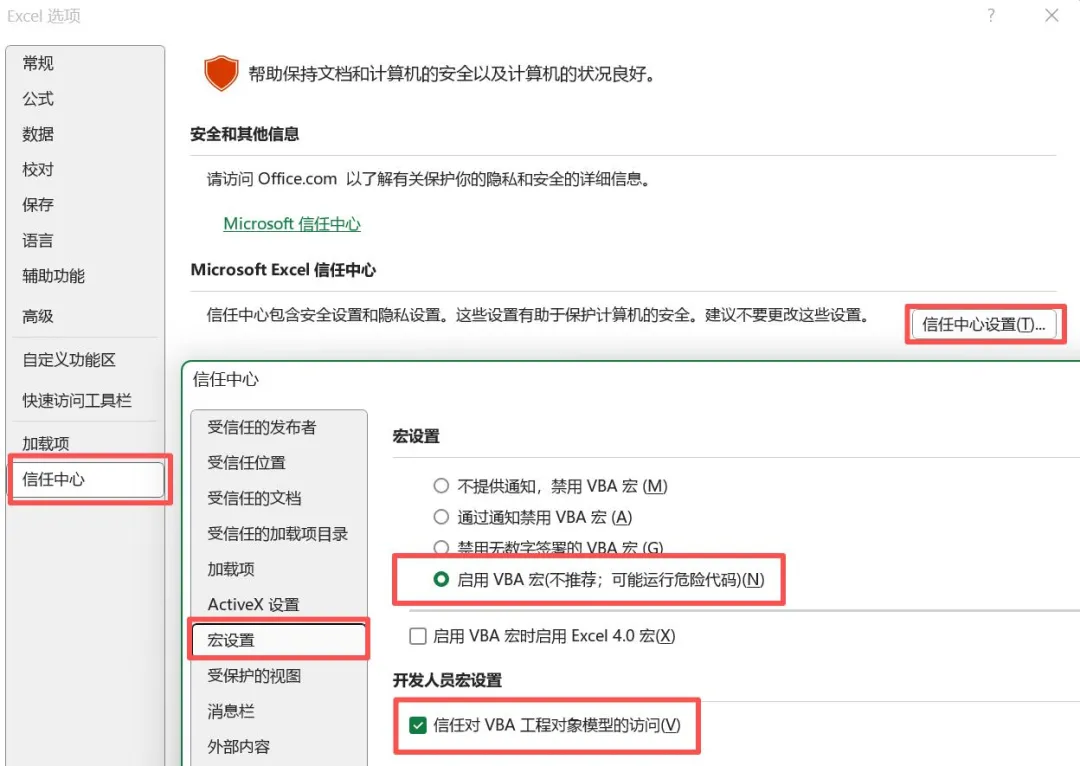
设置完成之后,先退出EXCEL程序,因为后面我们需要在python中安装对应的插件
方式2-2. python 安装插件
然后通过pip安装支持包,然后通过第二条指令安装EXCEL插件
pip install xlwingsxlwings addin install如果成功安装,你在控制台就能看见:
Successfully installed the xlwings add-in!
方式2-3. 插件选项卡
重新打开EXCEL,你就能看到在顶部工具栏,多了一个选项卡xlwings,在这里由于我是直接在anaconda环境的base空间中执行的上面两条命令,因此进入它就自己给我配置好了conda Path 和 Conda Env,如果说你进入的时候这个地方是空的,就在左侧的interpreter处填入你python编译器的位置即可。

另外需要提一下,建议勾选 RunPython: Use UDF Server(这是为了提高速度,防止每次点击都重启 Python 解释器) 接下来,你只需要写一段python程序,然后使用VBA调用它即可
方式2-4. 代码和表格准备
比如,我有一个DATA.xlsx 文件,结构大概是下面这样的:
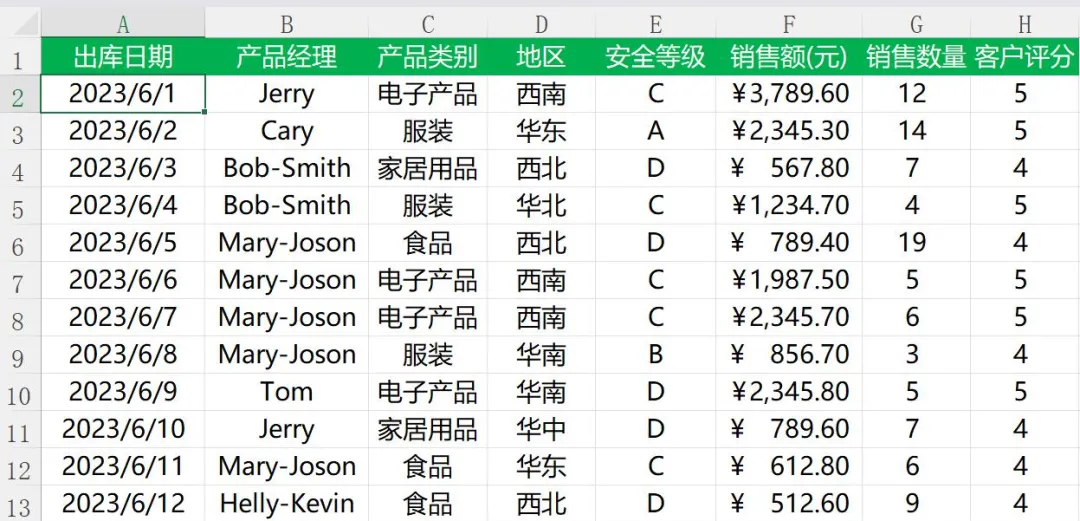
因此如果你需要调用python程序来对你的文档做处理的话,就可以写一个同名的py文件,非常重要的是同名,这个是因为你在xlwings插件下可以看到最左侧有一个run main的按钮,这个按钮的意思是:
在本xlsx文件同一个目录下,找一个同样名字的 py文件,然后执行里面的 main 程序

所以,如果你想要点击上面那个按钮进行执行,就严格按照这个结构组织文件,所以我在DATA.py 中写了以下代码:
import xlwings as xwimport pandas as pd defmain():# 1. 连接 Excel (调用者感知)try: wb = xw.Book.caller()except:# 调试模式:如果不是从 Excel 点按钮运行,而是直接在 PyCharm 运行,# 就手动指定一个文件路径,方便测试代码 wb = xw.Book(r"C:\Users\22330\Desktop\xlwings\DATA.xlsx")# 获取源数据 Sheet (假设数据在第一个 Sheet) source_sheet = wb.sheets[0]# 2. 读取数据 (核心步骤)# expand='table' 自动扩展读取整张表# index=False 表示不把第一列当作索引# header=True (默认) 表示第一行是标题try: df = source_sheet.range('A1').options(pd.DataFrame, expand='table', index=False).valueexcept Exception as e: xw.App().api.StatusBar = "读取数据失败,请检查A1单元格是否为空"return# === 设置拆分依据的列名 === split_column = "产品类别"# 检查列名是否存在,防止报错if split_column notin df.columns:# 使用 Windows 原生弹窗报错 (比 Excel API 更稳定)import ctypes ctypes.windll.user32.MessageBoxW(0, f"找不到列名:{split_column},请检查表头", "Python 错误", 0)return# 3. 开始拆分# df.groupby 就像 Excel 的透视表,瞬间把数据按部门分组for name, group_data in df.groupby(split_column):# 处理 Sheet 名称(Excel 限制 Sheet 名不能超过 31 个字符) sheet_name = str(name)[:31]# 检查 Sheet 是否已存在if sheet_name in [s.name for s in wb.sheets]: current_sheet = wb.sheets[sheet_name] current_sheet.clear() # 如果存在,先清空旧数据else:# 如果不存在,在最后新建一个 Sheet current_sheet = wb.sheets.add(sheet_name, after=wb.sheets[-1])# 4. 写入数据# index=False 表示写入时不带 Pandas 的索引列 current_sheet.range('A1').options(index=False).value = group_data# 自动调整列宽,好看一点 current_sheet.autofit()# 5. 完成提示# 将 Excel 状态栏改为完成 wb.app.api.StatusBar = "拆分完成"# 弹窗提示 (使用 ctypes 确保一定能弹出来)import ctypes ctypes.windll.user32.MessageBoxW(0, "所有部门数据已拆分完毕!", "成功", 0)if __name__ == "__main__": main()实现的主要功能,就是根据 “产品类别” 列拆分得到若干个sheet,其中大家需要理解的就是:
wb = xw.Book.caller() # 这一行代码是精髓。它告诉 Python:“谁在运行我,我就操作谁”因此在xlwings选项卡下点击 “Run Main” 的时候,wb就自动获取到是DATA.xlsx这个工作簿在调用,因此wb就被实例化为这个工作簿了,同时我们把所有要执行的代码,放到 main 这个函数下。
方式2-5. 程序运行
但是在点击这个按钮执行程序之前,需要记得一个非常重要的事情,就是在VBA工程中引用xlwings
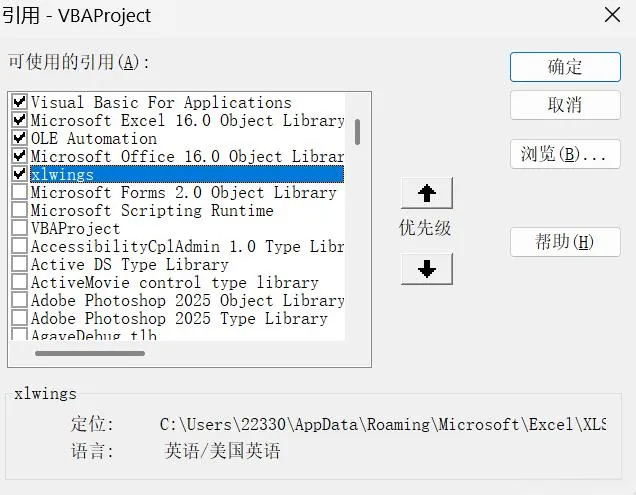
1、工具 → 引用
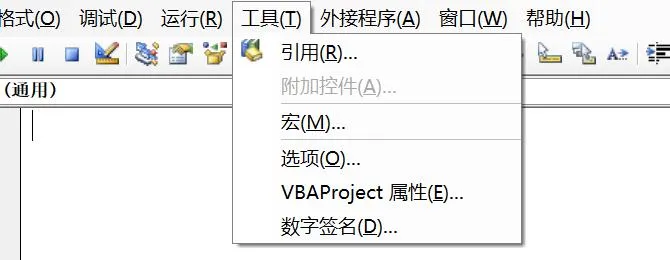
2、然后把xlwings给勾选上
3、单击Run Main 运行程序

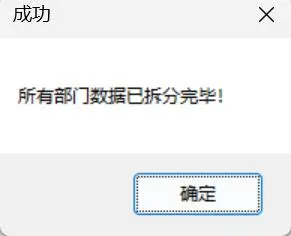
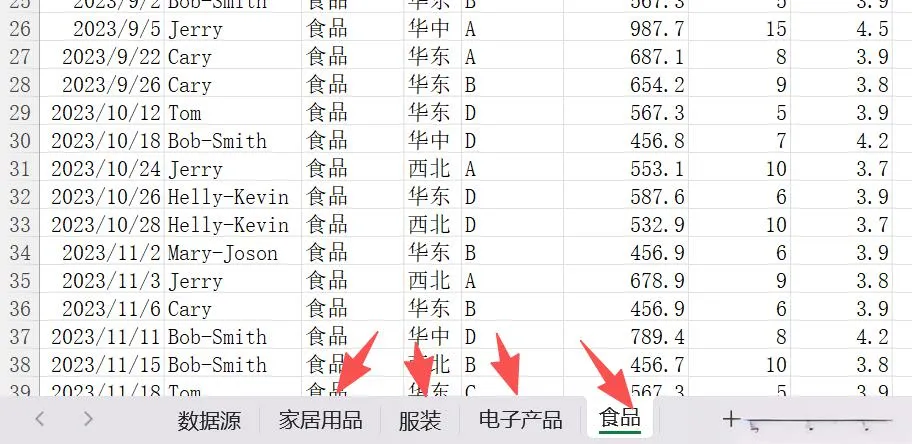
同时看到执行的结果,新建了四个表,按照产品类别进行了划分:
这里补充一句,如果你不想让python程序的名字和表格名字一样,我们也可以自己写VBA代码,然后执行:
Sub MySplit() ' 显式告诉 Excel 去找 splitter.py RunPython ("import splitter; splitter.main()")End Sub这样子,我们其实就告诉xlwings在当前目录下有一个splitter.py文件,点击运行此VBA代码,就会执行splitter.py文件中的main过程,所以我们的py文件名字就不受约束,只不过就是我们自己得写一句上面这样简单的代码
以上就是本期的所有内容啦,如果你也是EXCEL爱好者,经常需要处理表格数据,欢迎关注,给你送一份我摸爬滚打多年的实战手册!
