 夜雨聆风
夜雨聆风在真实业务场景中,许多文档并不只是由文字组成。
例如金融报告、研究论文、技术白皮书、政府文件等,往往同时包含表格、图表、流程图、示意图与图片。这些视觉信息本身也承载着关键内容,但传统文字搜索方式通常无法有效理解或检索这些信息。
为了解决这一问题,OpenSearch 支持多模态文档搜索,该功能通过向量搜索和神经搜索管道实现。然而,针对多模态数据的索引与查询存在多种方法,每种方法在搜索质量、延迟和复杂性方面都有不同的权衡。
为了帮助您找到最契合自身用例的方法,我们针对同一组包含1,000页报告的数据集使用三种方法进行了基准测试。本文将介绍每种方法,展示基准测试结果,并说明在不同情况下应使用何种方法。
数据集
我们使用了Hugging Face提供的“vidore/syntheticDocQA_government_reports_test”数据集进行基准测试。该数据集包含1,000页扫描报告,以及100个问答对。每个问题都对应唯一的相关文档,使其成为一个纯净的检索基准。
https://huggingface.co/datasets/vidore/syntheticDocQA_government_reports_test
三种方法比较
我们评估了以下三种方法,每种方法都代表了质量与延迟谱上的不同位置。
方法1:ColPali后期交互重排序
ColPali 是一种视觉语言模型,它将每一页文档视为一张图像,并生成多个补丁级嵌入(一种后期交互方法)。在搜索时,查询也会被编码成多个标记嵌入,然后通过将每个查询标记与每个文档补丁进行比较来计算相关性。这与ColBERT处理文本的方式类似,但已扩展到视觉内容上。下图展示了ColPali的处理流程:
文档图像 → SageMaker GPU端点(ColPali模型)→
存储在OpenSearch中的多个补丁嵌入 → 在搜索时,通过后期交互评分将查询嵌入与所有补丁嵌入进行比较。
这种方法将整个页面(包括文本、表格、图表和布局)作为整体图像进行处理,无需进行任何文本提取或解析。
方法2:BDA模态感知嵌入
这种方法利用Amazon Bedrock数据自动化(BDA)将每篇文档解析为不同类型的元素:段落、表格和图表。随后,每个元素都通过Amazon Titan多模态嵌入分别进行嵌入:文本元素采用文本模态,图表则采用图像模态(根据边界框坐标从原始页面裁剪而来)。所有嵌入均存储在同一个1,024维向量空间中。 下图展示了BDA流程:
文档 → BDA解析 → 元素提取(段落,表格、图表)→ 将文本元素嵌入“Titan”中,将图像元素嵌入“Titan”中 → 所有内容均以嵌套文档形式存储于OpenSearch中 → 在查询时进行神经搜索。
这种方法保留了特定于模态的信息。例如,图表是以图像的形式嵌入的,而非以光学字符识别(OCR)的文本形式呈现。
方法3:纯文本分块
纯文本分块是最简单的处理方法,也是实践中常见的模式。首先,BDA从文档中提取原始文本。然后,将文本分块成每个约200字的段落,每段之间有30字的重叠,并且每个片段都使用Amazon Titan文本嵌入模型进行嵌入处理。 下图展示了纯文本的分块过程:
文档图像→ BDA文本提取→ 拆分成约200字的段落 → 对每个段落进行“Titan”文本嵌入 → 存储为OpenSearch中的嵌套文档 → 在查询时进行神经搜索。
这种方法实施起来简单直接,但会舍弃所有视觉信息:表格会变成扁平化的文本,而图表、示意图及其他视觉元素则完全被忽略。
基准测试配置
为确保公平比较,我们在基准测试期间控制了以下变量。
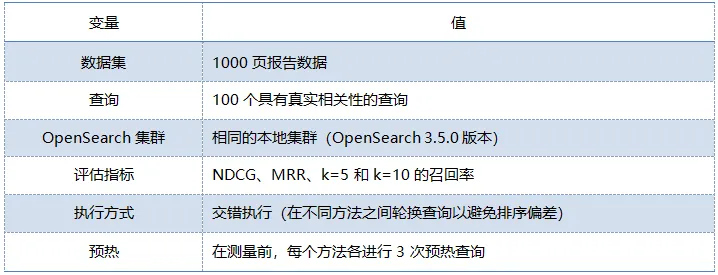
指标定义
我们使用了以下指标来评估搜索质量和性能:
NDCG@k(标准化折损累计增益):用于衡量相关结果在排名靠前位置的优劣。得分1.0表示完美排序。@5和@10分别表示对前5项或前10项结果的评估。
MRR@k(平均倒序排名):用于衡量首个相关结果出现的速度。得分1.0意味着正确文档总是被排在首位。
Recall@k:用于衡量在前k个结果中检索到的相关文档所占百分比。
延迟(毫秒):表示每次查询的平均搜索响应时间(以毫秒为单位)。
P95 延迟(毫秒):表示第 95 百分位的响应时间:95% 的查询完成时间都快于此值。
搜索质量结果
下表从搜索质量指标和查询延迟两个方面对这三种方法进行了比较。
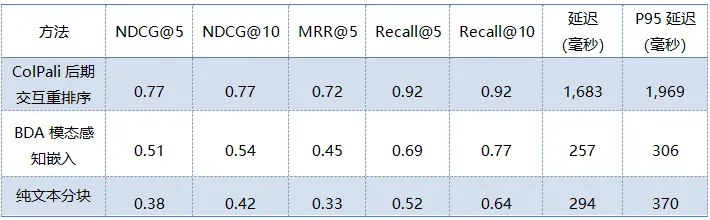
ColPali 在各项质量指标上均表现出色。其 NDCG@10 值为 0.77,Recall@10 为 0.92,这意味着在前 10 个结果中,它能以 92%的准确率找到正确文档。较高的 NDCG@10 分数表明相关文档往往出现在更靠前的位置。但代价是延迟:每个查询的延迟时间约为 1683 毫秒,这使得 ColPali 的运行速度比另外两种方法大约慢 6 到 7 倍,这是因为后期交互评分需要将查询的标记嵌入与所有存储的补丁嵌入进行比较,而重排序步骤则在 SageMaker GPU 端点上运行。
BDA 模式感知嵌入方法介于两种方法之间,其搜索质量处于中等水平(NDCG@10 = 0.54),且延迟较低(约 257 毫秒)。通过将图像和表格作为独立模态进行保存,该方法能够捕捉到纯文本方法所遗漏的信息。
纯文本分块法是最容易实施的,但得分最低(NDCG@10 = 0.42)。当文档中包含带有答案的表格、图表或图形时,纯文本处理方法无法对其进行检索。
数据摄取延迟结果
我们还测量了摄取每份文档所需的时间(50 份文档样本)。下表展示了基准测试的结果。
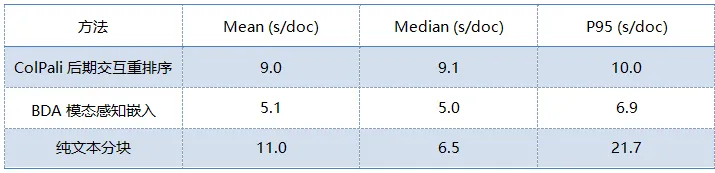
BDA 模态感知嵌入方法具有最稳定且最快的数据摄取时间。ColPali 的后期交互重排序每次文档的处理时间稳定在约 9 秒,这是由Amazon SageMaker GPU 推理时间所驱动的。纯文本分块的差异最大:中位数为 6.5 秒,但 P95 值上升到 21.7 秒,这是因为某些文档会产生大量文本分块,而每个分块都需要单独进行嵌入调用。
应该选择何种方法?
最佳方法取决于您的文档以及您的优先事项:
ColPali 后期交互重排序:如果搜索质量是您的首要考虑因素,并且能够接受稍高的搜索延迟,那么请选择此方法。当文档具有丰富的视觉内容(图表、图形、复杂布局)且准确性比速度更重要时,这是最佳选择。此方法需要一个 GPU 端点(例如,Amazon SageMaker)。
BDA 模态感知嵌入:如果您希望在质量与低延迟之间取得平衡,那么请选择此方法。它通过将文本和图像视为独立的模态来处理混合内容文档。此方法为大多数用例提供了恰当的平衡。
纯文本分块:如果您的文档以文本形式为主,或者简单性和快速实现是优先考虑的因素,那么请选择此方法。它设置起来最简单,但在包含重要视觉信息的文档上表现欠佳。
下一步行动
要了解更多关于 OpenSearch 中的向量搜索和神经搜索的相关信息,请参考以下资源:
多模态搜索
https://docs.opensearch.org/latest/vector-search/ai-search/multimodal-search/
通过特定领域使用外部托管的后期交互模型进行重新排序
https://docs.opensearch.org/latest/search-plugins/search-relevance/rerank-by-field-late-interaction/
如有疑问或想分享自己的基准测试结果,欢迎在 OpenSearch 论坛上参与讨论
https://forum.opensearch.org/
作者简介
Nate Po Hong Lau

Nate Po Hong Lau 是AWS网络服务公司的一名软件开发工程师,负责 OpenSearch 项目。
据悉,该模板由不知名设计师制作,不知名小编上传,不知名热心人士审查,最终供由用户使用。

