 夜雨聆风
夜雨聆风还在为 PDF 翻译后排版错乱、公式乱码、图表错位头疼?普通翻译工具无法保障学术论文的专业术语精度,手动制作双语对照文档耗时耗力,批量处理大型文档更是难上加难?
这款专为科研与技术文档打造的 PDF 智能翻译工具,精准还原原文版式、公式与段落结构,一键生成高质量双语对照 PDF,适配多类大模型,开箱即用彻底解决 PDF 专业翻译的核心痛点。
源代码:
https://www.gitcc.com/GoogleChat/babeldoc-cn

● 原生 PDF 结构解析与版式无损还原: 精准解析 PDF 文档的段落、图表、公式、字体等全结构元素,翻译后 1:1 还原原文排版布局,彻底解决普通翻译工具破坏文档格式、公式乱码、图表错位的行业痛点,学术论文、技术文档翻译后依然保持专业规范的版式。
● 多模式双语对照输出与灵活配置: 原生支持左右同页、页码交替两种双语 PDF 模式,可自由设置译文优先、无水印输出、指定页码翻译、大文档分块处理等个性化配置,同时支持多文件批量翻译,单条命令即可完成多篇论文的批量处理,大幅提升翻译效率。
● 全兼容翻译引擎与低门槛集成能力: 原生支持 OpenAI 全系列模型,完美兼容所有 OpenAI 格式接口,可无缝对接本地 Ollama、DeepSeek、GLM 等开源大模型。同时提供极简 CLI 命令行工具与 Python API,一行命令即可完成翻译,也可轻松嵌入其他工具与业务系统中。
● 科研学术论文翻译与文献研读场景: 专为 SCI、EI 等英文学术论文深度优化,精准保留专业术语、公式、参考文献格式,一键生成双语对照 PDF,帮助科研人员高效研读外文文献、撰写中英双语学术稿件,彻底打破外文文献阅读的语言与格式壁垒。
● 企业技术文档本地化与跨境交付场景: 完美适配技术白皮书、产品手册、专利文档、开发文档等专业 PDF 的翻译需求,可批量完成多文档的标准化翻译与格式还原,帮助企业快速完成技术文档的多语言本地化,高效适配跨境业务交付需求。
● 个人学习与工具二次开发场景: 个人用户可零门槛完成外文教材、行业报告、技术文档的翻译,无需复杂配置即可获得高质量双语文档。同时开源架构支持深度二次开发,开发者可基于其 API 快速搭建专属翻译服务、文档处理工具与插件扩展。

● 大幅降低专业文档翻译成本: 开源免费的核心能力,可直接替代年费高昂的专业 PDF 翻译工具与人工翻译服务,一篇数十页的学术论文翻译成本近乎为零。同时大幅缩短翻译周期,原本数小时的人工排版翻译工作,数分钟即可自动完成。
● 提升科研与企业文档处理效率: 版式自动还原 + 批量翻译能力,让科研人员无需再手动调整翻译后的文档格式,可完全聚焦核心研究工作;企业可快速完成大批量技术文档的本地化处理,大幅缩短产品出海、技术跨境交付的周期,全面提升业务效率。
● 广阔的商业化拓展空间: 基于开源架构可快速打造私有化部署的企业级文档翻译平台,定制行业专属术语库、加密文档处理、多团队协同管理等增值功能,可提供 SaaS 订阅、私有化部署、定制化开发等多种商业化变现服务,适配教育、科研、跨境企业等多行业需求。
● 大模型驱动的专业术语智能对齐: 基于大语言模型能力,可自动提取文档中的专业术语、人名、机构名,生成专属术语库,确保全文翻译术语统一。同时支持自定义术语库导入,针对科研、金融、法律等垂直领域,可大幅提升专业内容的翻译精准度。
● 离线化部署与无网环境适配能力: 支持离线资源一键打包与还原,可将文档解析所需的全部模型、字体打包为离线包,在无外网的涉密内网、离线环境中也可完整运行。配合本地开源大模型,可实现全流程离线的文档翻译,全方位保障涉密文档的数据安全。
● 插件化生态与多工具无缝集成: 采用插件化的流水线架构,支持自定义 OCR、文档解析、翻译、渲染模块,可灵活扩展新能力。同时已深度适配 Zotero 文献管理工具、沉浸式翻译插件等主流工具,形成完整的文档翻译生态,完美适配 AI 时代全场景的文档处理需求。
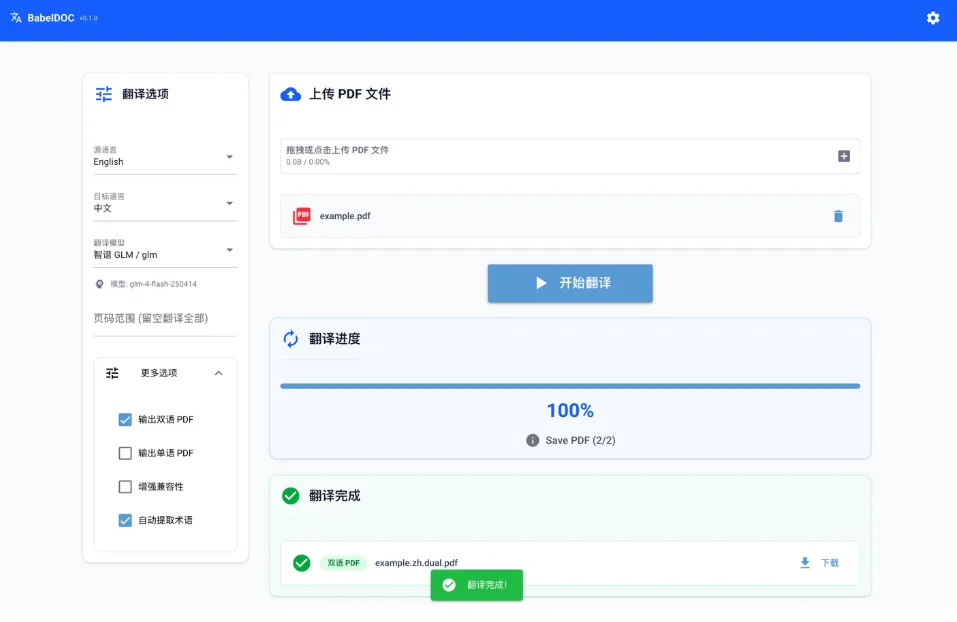
这款专为科研与技术文档打造的 PDF 智能翻译工具,精准还原原文版式、公式与段落结构,一键生成高质量双语对照 PDF,适配多类大模型,开箱即用彻底解决 PDF 专业翻译的核心痛点。
源代码:
https://www.gitcc.com/GoogleChat/babeldoc-cn
