 夜雨聆风
夜雨聆风Agent洞察
1. 整体架构与流程
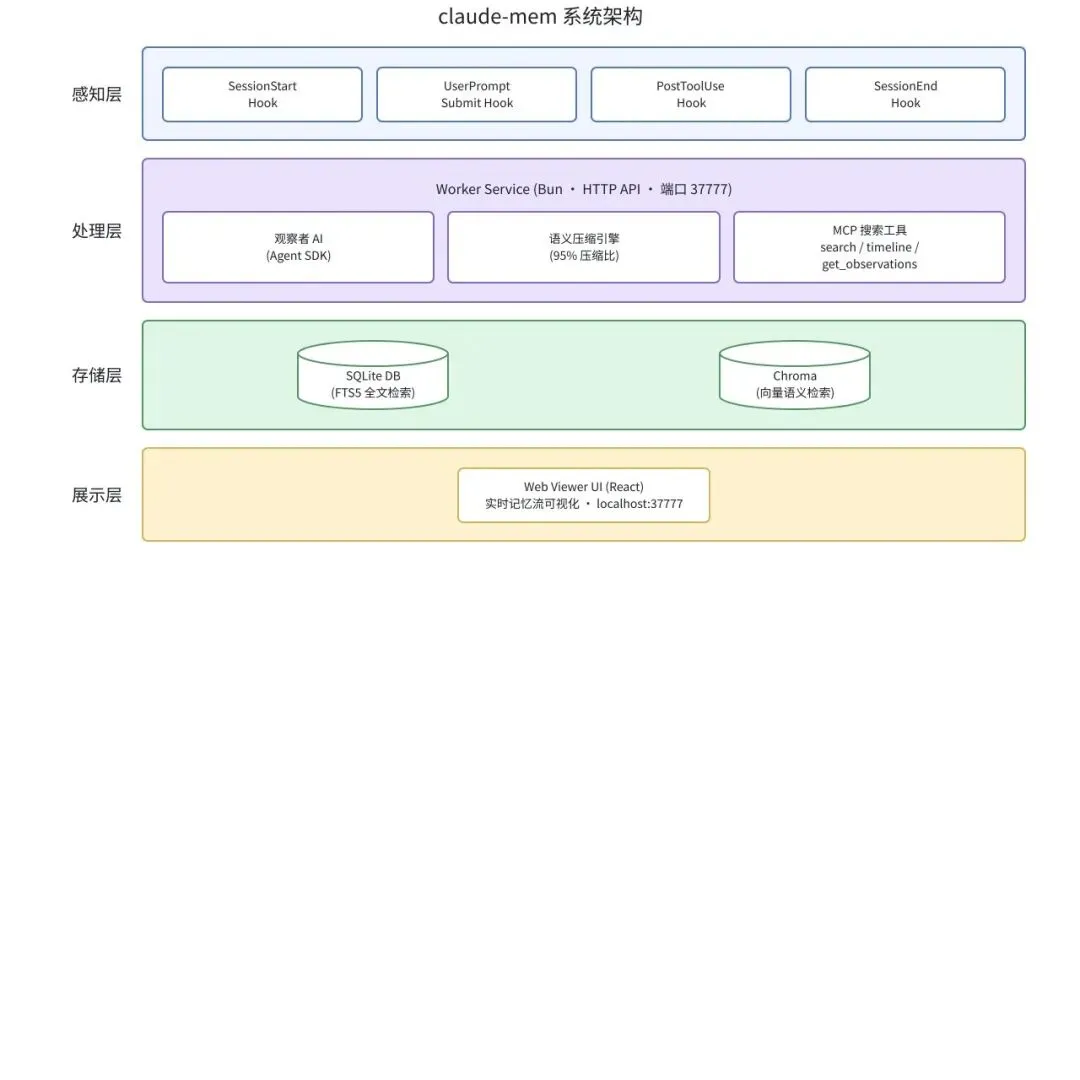
系统架构图
核心数据流
架构要点
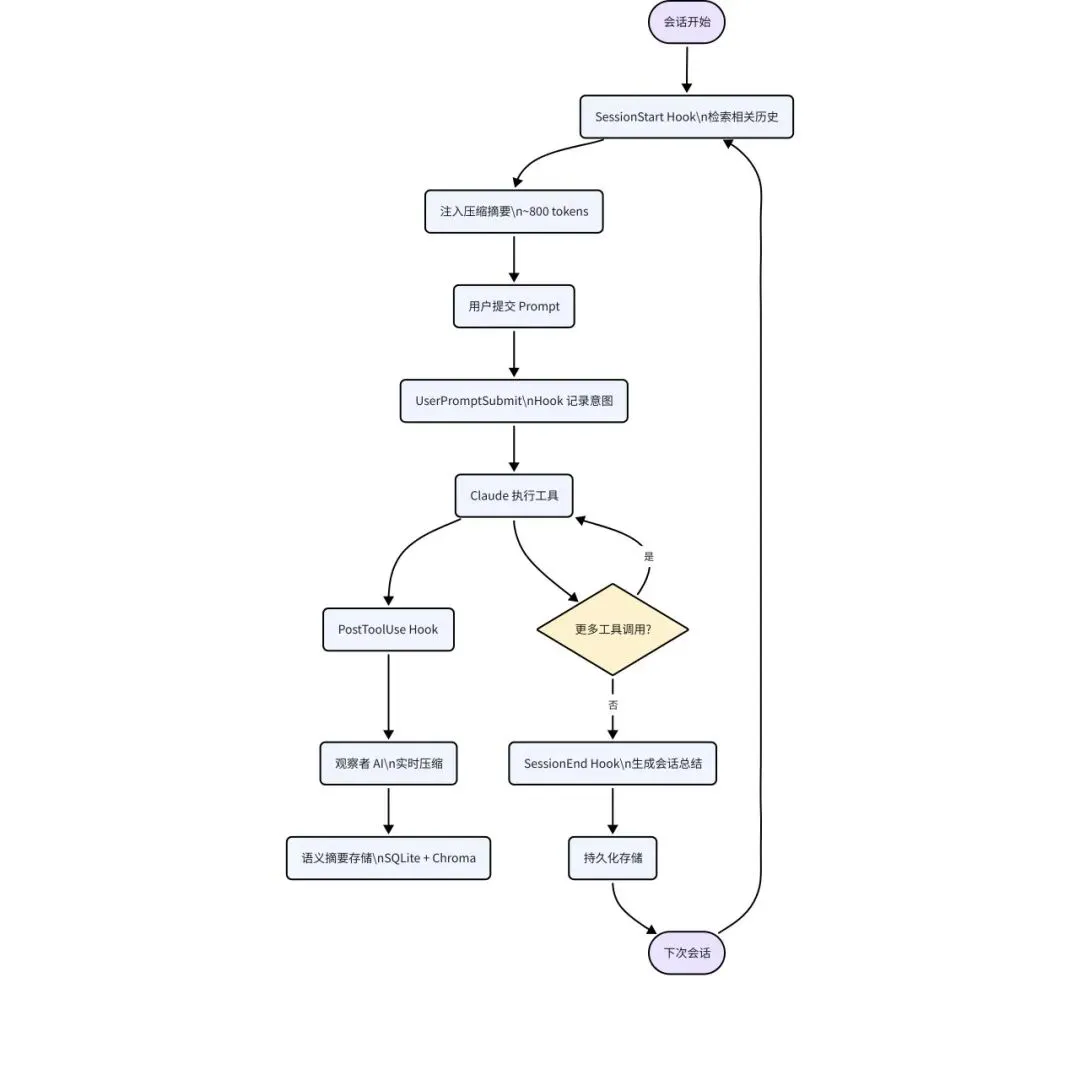
claude-mem 的架构设计围绕 Claude Code 的 Plugin Hook 机制展开。Claude Code 在会话生命周期的五个关键节点(SessionStart、UserPromptSubmit、PostToolUse、Stop、SessionEnd)暴露了钩子接口,claude-mem 在每个钩子上注册了对应的 TypeScript 处理函数,编译为 ESM 模块部署。这些钩子负责"感知",而真正的"思考"(AI 压缩、语义分析)由后台 Worker Service 异步完成,避免阻塞用户交互。
Worker Service 基于 Bun 运行时管理,提供 Express HTTP API。它内部集成了三个核心子系统:观察者 AI(使用 Claude Agent SDK 进行语义压缩)、SQLite 数据库(带 FTS5 全文检索)、Chroma 向量数据库(语义嵌入检索)。双数据库架构实现了关键词精确匹配与语义模糊匹配的互补。
2. 设计理念与思想
核心哲学:"上下文即货币"(Context as Currency)
claude-mem 最深层的设计哲学可以用一句话概括:在 LLM 的有限注意力窗口中,每一个 token 都是稀缺资源,必须像管理预算一样管理上下文。
这个理念源于对 LLM 实际运作方式的深刻理解。一个 100,000 token 的上下文窗口并不等于 100,000 个有效注意力单元——随着上下文膨胀,模型对早期内容的关注度会衰减(即"注意力稀释")。传统 RAG 方案在会话启动时倾泻 35,000+ token 的历史信息,其中仅约 6% 与当前任务相关,这不仅浪费了 token 预算,更关键的是污染了模型的注意力分配,导致"上下文腐烂"(context rot)。
claude-mem 的回答是:不预加载,而是展示目录让 Agent 自主选择。这背后是对 AI Agent 能力的信任——它相信 Agent 比任何预设的检索策略更了解当前任务需要什么信息,因此应该把信息消费的决策权交给 Agent 本身。在之前就决定了什么是相关的。这种"由外而内"的策略无法应对 Agent 任务的动态性和多样性。
3. 核心能力与核心要素
3.1 渐进式信息披露(Progressive Disclosure)
渐进式信息披露是 claude-mem 最核心、最具辨识度的设计。它解决的问题是:AI 编程助手在恢复会话时,如何在"记住一切"(token 爆炸)和"什么都不记"(上下文丢失)之间找到最优平衡点。
传统方案的做法是在会话启动时一次性注入所有历史信息。假设一个项目积累了 200 条观察记录,平均每条 500 token,全量注入需要 100,000 token——这将占满整个上下文窗口,留给实际编码任务的空间几乎为零。即便采用 RAG 预过滤,在 Agent 尚未理解当前任务的时刻,任何预过滤策略都可能遗漏真正需要的信息。
claude-mem 的三层架构反转了这个流程:
第一层(索引层):会话启动时仅注入一个轻量级索引,约 800 token。每条索引项包含标题(语义压缩为约 10 词)、时间戳、类型图标和预估 token 成本。这一层的设计哲学是"展示存在什么,以及获取它的代价"。
第二层(时间线层):当 Agent 在索引中发现感兴趣的条目时,可以请求该条目的时间线上下文——它前后发生了什么,形成因果叙事。这一层帮助 Agent 理解"为什么做了这个决策",而非仅仅"做了什么"。
第三层(详情层):只有当 Agent 明确需要某条观察的完整信息时,才拉取全文(每条约 500-1,000 token)。
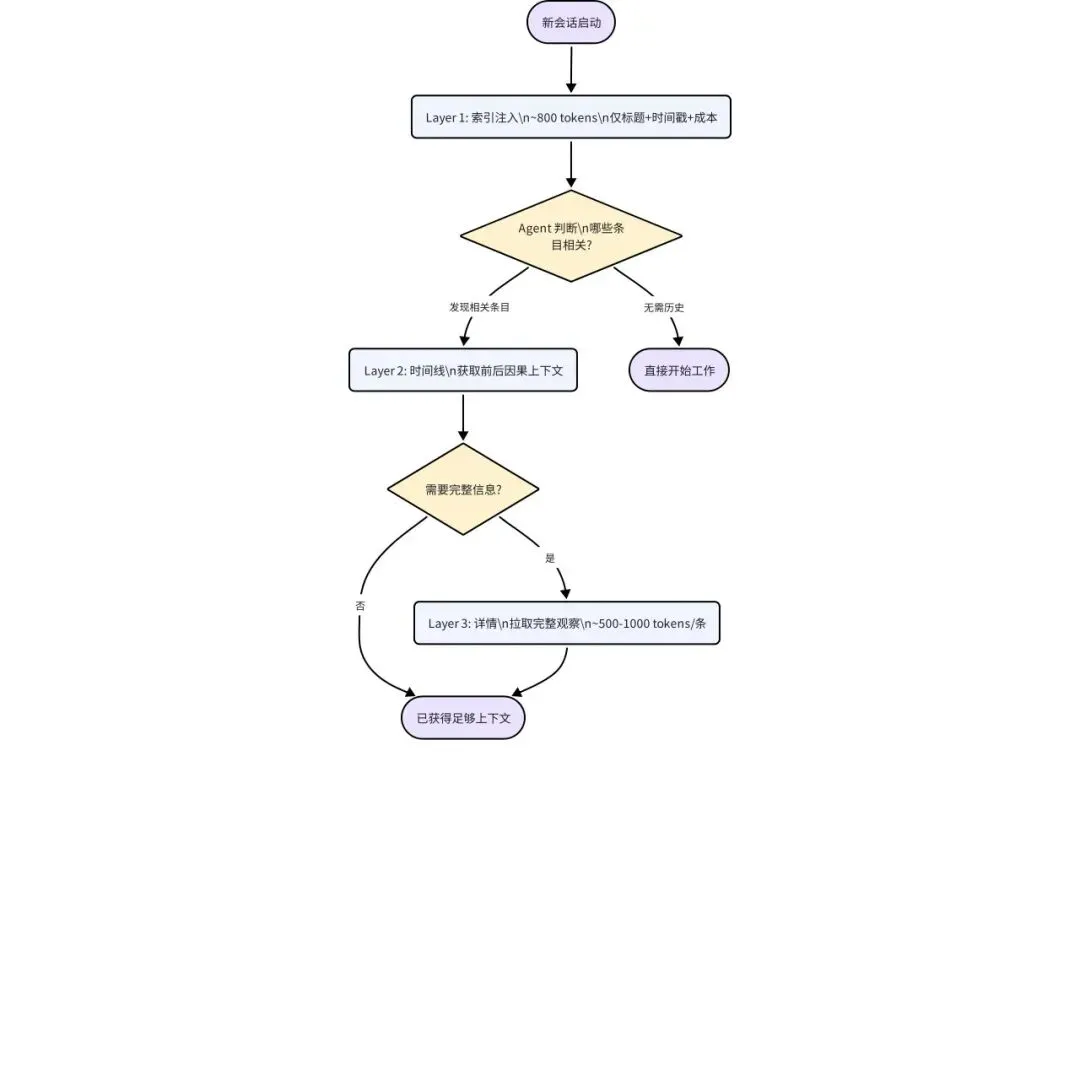
这套机制之所以有效,原因有三:首先,它利用了 LLM 本身的判断能力——Agent 在理解当前任务后,能比任何预设算法更准确地判断哪些历史信息与当前任务相关。其次,它让成本可见化——每条索引都标注了 token 消耗,Agent 可以像做预算一样权衡"这条信息值不值得花 500 token 去看"。最后,它保留了完整性——信息没有被丢弃,只是延迟加载,任何历史都可以被追溯。
3.2 实时观察与 AI 压缩
claude-mem 的第二核心能力是其"观察者"系统——一个独立的 AI 进程实时监视 Claude Code 的每一次工具调用,将冗长的工具输出压缩为结构化的语义摘要。
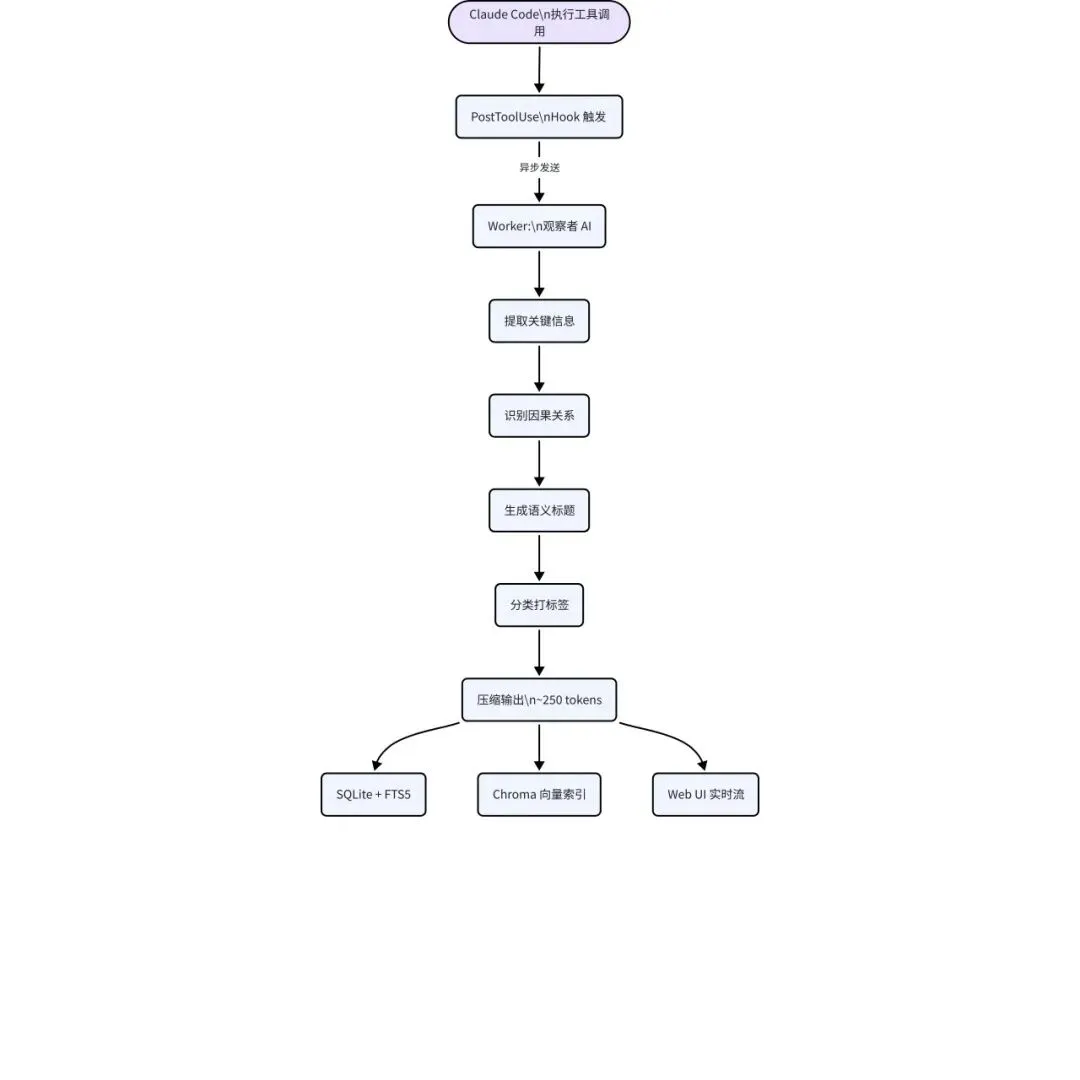
这个能力解决的问题是:Claude Code 在一次会话中可能执行数十甚至上百次工具调用(文件读写、命令执行、搜索等),每次工具输出可能包含数千 token 的原始数据。如果直接存储这些原始数据,不仅存储成本高,更重要的是在未来检索时会产生大量噪音。
观察者 AI 使用 Claude Agent SDK 实现,工作流程如下:每次 PostToolUse 钩子触发时,钩子将工具调用的类型、输入、输出发送给 Worker Service;Worker 中的观察者 AI 分析这些原始数据,提取关键信息——做了什么、为什么做、结果如何、有什么值得记住的——然后生成一条结构化观察记录,包含语义压缩的标题(约 10 词)、分类标签(决策、bug 修复、功能实现、发现等)、影响的文件路径、以及包含前后因果上下文的摘要正文。
压缩比约为 95%——将 1,000-10,000 token 的工具输出压缩至约 500 token。这个压缩不是简单的截断,而是语义级别的信息萃取。
3.3 双引擎混合检索
claude-mem 同时维护 SQLite(FTS5 全文检索)和 Chroma(向量嵌入语义检索)两个检索引擎,实现关键词精确匹配与语义模糊匹配的互补。
当用户问"我们是怎么实现身份认证的?"时,关键词检索会找到包含"auth"、"authentication"、"登录"等精确词汇的记录;语义检索则能找到虽然不含这些关键词、但在概念上与身份认证相关的记录(如"JWT token 过期处理"、"OAuth 回调 URL 配置")。两者融合后的结果比单一引擎更完整、更准确。
