 夜雨聆风
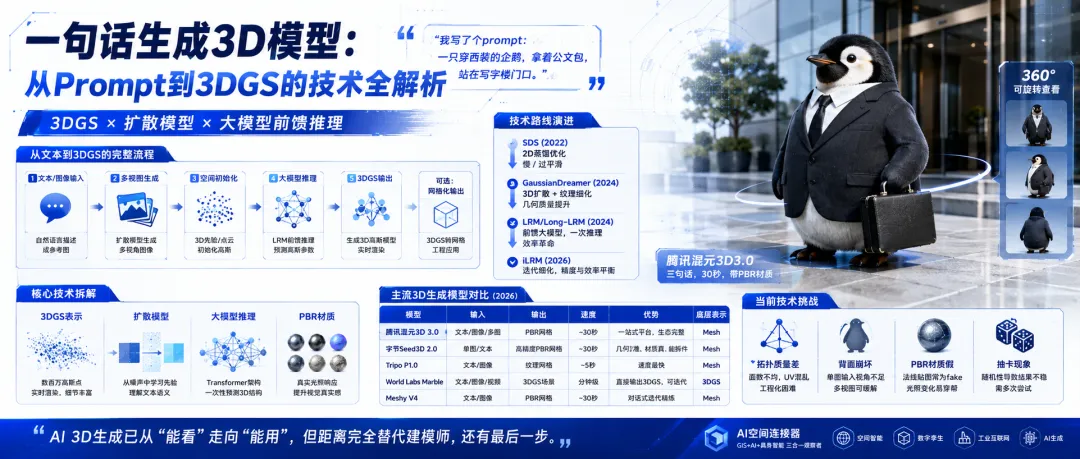
夜雨聆风"我写了个prompt:一只穿西装的企鹅,拿着公文包,站在写字楼门口。AI给了我这个。"
屏幕上是一只3D企鹅——毛茸茸的,西装笔挺,公文包在右手上。可以360度旋转看,可以放到Unity里跑。
"用的是什么?"
"腾讯混元3D3.0。三句话,30秒,带PBR材质。"
他接着说:"以前找建模师做这个,至少两天。现在30秒。但说实话,模型放大看,企鹅脚底的拓扑一塌糊涂,UV也没展开。能看,但不能用。"
这就是2026年AI 3D生成的真实水平:肉眼看着已经很好了,工程上用起来还是有坑。
这篇拆解从"一句话"到"一个3DGS模型"中间到底发生了什么,以及为什么它还没完全替代建模师。
先搞清楚这件事到底在做什么
你要的不是一张图。你要的是一个3D模型——有几何、有材质、可以从任意角度看。
2022年的做法叫Score Distillation Sampling(SDS),代表是DreamFusion。思路很直接:
文本 prompt → 2D扩散模型(Stable Diffusion)→ 生成多个角度的2D图 → 用这些图的梯度"蒸馏"回一个3D表示(NeRF)→ 反复优化但这个方案有两个致命问题:
- 慢
——一个模型要优化几个小时 - 过平滑
——SDS的梯度有方差,结果经常糊成一团
3DGS的出现改变了一切。
DreamGaussian(2023)第一个把SDS和3DGS结合,原因很简单:
3DGS的渲染速度是NeRF的100倍以上。SDS需要渲染成千上万个视角来计算梯度——NeRF做这个要几小时,3DGS只要几分钟。
# DreamGaussian的核心流程(简化)# 来源: DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creationimport torchfrom diff_gaussian_rasterization import GaussianRasterizationSettings, GaussianRasterizerclassDreamGaussianOptimizer:def__init__(self, prompt, num_iterations=500):self.prompt = promptself.num_iterations = num_iterations# 1. 加载2D扩散模型(Stable Diffusion)from diffusers import StableDiffusionPipelineself.pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1" )self.pipe.enable_xformers_memory_efficient_attention()# 2. 初始化3D高斯(从稀疏点云开始)# 先用文本生成几个多视角图,反投影得到初始点云self.gaussians = self.initialize_gaussians(prompt)# 3. 设置光栅化器self.rasterizer = GaussianRasterizer( raster_settings=GaussianRasterizationSettings( image_height=512, image_width=512, tanfovx=1.0, # tan(FOV/2) tanfovy=1.0, bg=torch.tensor([1, 1, 1], dtype=torch.float32), scale_modifier=1.0, viewmatrix=torch.eye(4), projmatrix=torch.eye(4), sh_degree=3, campos=torch.zeros(3), prefiltered=False, debug=False, ) )defsds_loss(self, rendered_image, prompt_embeddings):""" Score Distillation Sampling Loss 核心思想:用扩散模型的噪声预测作为梯度信号 具体步骤: 1. 给渲染图加随机噪声(t时刻) 2. 用扩散模型预测噪声 3. 计算预测噪声和真实噪声的差异 4. 反向传播更新3D高斯参数 """# 加噪声 t = torch.randint(0, 1000, (1,)) # 随机时间步 noise = torch.randn_like(rendered_image) noisy_image = self.add_noise(rendered_image, noise, t)# 用扩散模型预测噪声(带文本条件)with torch.no_grad(): predicted_noise = self.pipe.unet( noisy_image, t, encoder_hidden_states=prompt_embeddings, ).sample# SDS梯度 = 预测噪声 - 真实噪声 sds_gradient = predicted_noise - noise# 这个梯度告诉3D高斯:往哪个方向调整,# 渲染出来的图会更接近扩散模型对prompt的理解return sds_gradientdefoptimize(self):"""主优化循环"""for i inrange(self.num_iterations):# 从随机视角渲染 viewpoint = self.get_random_viewpoint() rendered = self.render(viewpoint)# 计算SDS loss loss = self.sds_loss(rendered, self.prompt_embeddings)# 反向传播更新高斯参数 loss.backward()self.optimizer.step()self.optimizer.zero_grad()if i % 100 == 0:print(f"Iteration {i}: SDS loss = {loss.item():.4f}")这个方案的瓶颈很明显:SDS梯度本身就不稳定。它本质上是靠"2D扩散模型觉得好不好"来反向更新3D高斯——一个没有3D理解力的老师,教一个3D学生。
所以DreamGaussian生成的模型,正面看很好看,侧面看就可能变形。
第二代:用3D先验替代2D蒸馏
DreamGaussian的改进方向很明确:不要再用2D扩散模型的梯度来教3D了,直接用3D扩散模型。
GaussianDreamer(2024)做了这件事。它的关键改动:
旧路线(DreamGaussian): 3D高斯 → 渲染2D图 → 2D扩散模型打分 → SDS梯度 → 更新高斯新路线(GaussianDreamer): 3D先验初始化 → 3D扩散模型直接操作高斯参数 → 2D扩散模型细化纹理# GaussianDreamer的核心流程(简化)# 来源: GaussianDreamer: Fast Generation from Text to 3D Gaussians# by Bridging 2D and 3D Diffusion ModelsclassGaussianDreamer:def__init__(self, text_prompt):self.text_prompt = text_prompt# 2D扩散模型:负责纹理细化from diffusers import StableDiffusionPipelineself.sd_model = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base" )# 3D扩散模型:负责几何初始化# 这是一个在3D数据上训练的扩散模型# 输入文本,输出粗糙的3D点云+法向self.diffusion_3d = self.load_3d_diffusion_model()defgenerate(self):# === 阶段1:3D扩散模型生成初始高斯 ===# 3D扩散模型直接生成3D结构,不是2D图的蒸馏# 这一步的几何质量比SDS方法好得多# 3D扩散模型内部是一个UNet,在3D体素/点云上操作# 输入:文本embedding# 输出:3D点云 + 法向 + 粗糙颜色 point_cloud = self.diffusion_3d.sample( prompt=self.text_prompt, num_points=100_000, )# 把点云转成3D高斯的初始状态 gaussians = self.pointcloud_to_gaussians(point_cloud)# === 阶段2:用2D扩散模型细化纹理 ===# 几何已经有了,现在让纹理更好看# 这里用SDS但只做纹理优化,不碰几何for i inrange(300): # 只需要300步,因为几何已经很好了 viewpoint = self.get_random_viewpoint() rendered = self.render(viewpoint, gaussians)# 只优化颜色/不透明度,不优化位置/旋转/缩放 texture_loss = self.sds_texture_loss(rendered, self.text_prompt) texture_loss.backward(retain_graph=True)# 只更新颜色相关的参数self.update_gaussian_colors(gaussians)return gaussiansdefpointcloud_to_gaussians(self, point_cloud):"""把3D点云转成3D高斯初始化"""# 每个点变成一个高斯函数# 位置 = 点的坐标# 旋转 = 基于法向量估计朝向# 缩放 = 基于点密度估计 N = len(point_cloud) means = point_cloud.positions # (N, 3)# 用PCA估算每个点局部邻域的协方差 rotations = self.estimate_rotations( point_cloud.positions, point_cloud.normals, )# 缩放:基于最近邻距离 scales = self.estimate_scales( point_cloud.positions, k_neighbors=5, )# 颜色:先从点云里取 colors = point_cloud.colors # (N, 3)# 不透明度:初始化为中等值 opacities = torch.full((N, 1), 0.5)return {'means': means, # 位置 (N, 3)'rotations': rotations, # 旋转 (N, 4) 四元数'scales': scales, # 缩放 (N, 3)'colors': colors, # 颜色 (N, 3) SH系数'opacities': opacities, # 不透明度 (N, 1) }这个方案的改进是根本性的:3D扩散模型生成的初始几何质量比SDS好得多,因为它是"真正懂3D"的老师。纹理阶段虽然还是用SDS,但几何不动,只优化颜色,就不会出现"侧面变形"的问题。
但GaussianDreamer依然需要迭代优化——生成一个模型要15分钟。
第三代:前馈大模型,一次推理出结果
上面的方法都有一个共同问题:慢。SDS要几百步迭代,GaussianDreamer要300步纹理优化。
2023年底,LRM(Large Reconstruction Model)出来了。它的思路完全不同:
不要优化。直接预测。
旧路线:输入1张图 → 初始化3D表示 → 迭代优化几百步 → 输出3D模型新路线:输入1张图 → 直接喂给Transformer → 输出3D模型这是一次范式转移。从"用梯度慢慢调"变成"用数据驱动一次出结果"。
GS-LRM:直接把图转成高斯参数
GS-LRM(ECCV 2024,康奈尔)是LRM的3DGS版本。核心代码结构:
import torchimport torch.nn as nnfrom einops import rearrangeclassGSLRM(nn.Module):""" Large Reconstruction Model for 3D Gaussian Splatting 输入:1-4张稀疏视图图像 + 相机位姿 输出:3D高斯参数(直接可用的.splat格式) 推理时间:~0.23秒(A100) """def__init__(self, num_views=4, image_size=256, num_gaussians=160_000):super().__init__()self.num_views = num_viewsself.num_gaussians = num_gaussians# === 1. 图像编码器:用预训练的DINOv2提取图像特征 ===self.image_encoder = self.load_dinov2_backbone()# DINOv2输出每个patch的特征向量# 对于256×256的图,patch_size=14,得到18×18=324个patch特征# === 2. 相机编码器:把相机位姿编码成特征 ===self.camera_encoder = nn.Sequential( nn.Linear(16, 128), # [R|t]展平为16维 → 128维 nn.LayerNorm(128), nn.GELU(), nn.Linear(128, 256), )# === 3. Token融合:图像特征 + 相机特征 → 统一token序列 ===self.token_mixer = nn.TransformerEncoderLayer( d_model=768, nhead=12, dim_feedforward=3072, batch_first=True, )# === 4. 高斯解码器:从token序列预测高斯参数 ===# 这里用的是"可学习的3D查询token"# 类似DETR的目标检测思路:N个query token → N个高斯self.gaussian_queries = nn.Parameter( torch.randn(num_gaussians, 768) )self.gaussian_decoder = nn.TransformerDecoder( nn.TransformerDecoderLayer( d_model=768, nhead=12, dim_feedforward=3072, batch_first=True, ), num_layers=4, )# === 5. 参数头:从decoder输出预测每个高斯的具体参数 ===self.param_heads = nn.ModuleDict({'position': nn.Sequential( nn.Linear(768, 256), nn.GELU(), nn.Linear(256, 3), # (x, y, z) nn.Tanh(), # 限制在[-1, 1]范围 ),'rotation': nn.Sequential( nn.Linear(768, 256), nn.GELU(), nn.Linear(256, 4), # 四元数 (w, x, y, z) ),'scale': nn.Sequential( nn.Linear(768, 256), nn.GELU(), nn.Linear(256, 3), # (sx, sy, sz) ),'color': nn.Sequential( nn.Linear(768, 256), nn.GELU(), nn.Linear(256, 48), # SH系数 (3通道 × 16阶 = 48) ),'opacity': nn.Sequential( nn.Linear(768, 256), nn.GELU(), nn.Linear(256, 1), ), })defforward(self, images, camera_poses):""" 前馈推理,不需要任何迭代优化 Args: images: (B, num_views, 3, 256, 256) 多视图图像 camera_poses: (B, num_views, 4, 4) 相机位姿矩阵 Returns: gaussian_params: dict,包含所有高斯参数 """ B = images.shape[0]# 1. 编码每张图像 image_features = []for v inrange(self.num_views): feat = self.image_encoder(images[:, v]) # (B, 324, 768) cam_feat = self.camera_encoder( camera_poses[:, v].view(B, -1)[:, :16] ).unsqueeze(1) # (B, 1, 256) → (B, 1, 768)# 图像特征 + 相机特征 combined = torch.cat([feat, cam_feat], dim=1) # (B, 325, 768) image_features.append(combined)# 2. 融合多视图特征 all_tokens = torch.cat(image_features, dim=1) # (B, num_views*325, 768) memory = self.token_mixer(all_tokens) # (B, 1300, 768)# 3. 高斯解码 queries = self.gaussian_queries.unsqueeze(0).expand(B, -1, -1)# (B, 160000, 768) decoded = self.gaussian_decoder( queries, # query: 要预测的高斯 memory, # key/value: 从图像中提取的信息 ) # (B, 160000, 768)# 4. 预测参数 gaussian_params = {}for name, head inself.param_heads.items(): gaussian_params[name] = head(decoded)return gaussian_params# 从输入到输出,一次forward,0.23秒# 不需要任何梯度下降这段代码的核心洞察是:把3D重建变成了一个"翻译"问题。
输入是"看图"(多视图图像),输出是"3D描述"(16万个高斯参数)。中间的Transformer就是翻译器——它学过几十万对"图→3D"的例子,知道看到一张图该怎么输出对应的3D高斯。
训练数据从哪里来?从Objaverse。这个数据集有80万个带标注的3D模型。对每个模型随机渲染几个视角作为输入,原始3D模型转成高斯参数作为输出——这就是训练对。
Long-LRM:从单物体到场景级
GS-LRM的问题是只能处理2-4张输入图。重建单个物体够了,但一个园区、一栋楼怎么办?
Long-LRM(2024)的解法:换架构。
# Long-LRM的核心架构变化# 来源: Long-LRM: Long-sequence Large Reconstruction Modelimport torchimport torch.nn as nnfrom mamba_ssm import Mamba2classLongLRMBlock(nn.Module):""" Mamba2 + Transformer 交替架构 Mamba处理长序列效率高,Transformer做全局注意力 """def__init__(self, d_model=768, mamba_d_state=64):super().__init__()# Mamba2块:高效处理长序列(64张图 × 324 patch = 20736 tokens)# Mamba的时间复杂度是O(N),Transformer是O(N²)# 对长序列,Mamba快得多self.mamba_block = Mamba2( d_model=d_model, d_state=mamba_d_state, d_conv=4, expand=2, )# Transformer块:全局注意力,确保不同视角之间的一致性self.transformer_block = nn.TransformerEncoderLayer( d_model=d_model, nhead=12, dim_feedforward=3072, batch_first=True, )self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)defforward(self, x):# Mamba先跑一遍:局部信息高效处理 x = x + self.mamba_block(self.norm1(x))# Transformer再跑一遍:全局一致性检查 x = x + self.transformer_block(self.norm2(x))return x# 完整模型classLongLRM(nn.Module):def__init__(self, max_views=64, image_size=512):super().__init__()self.max_views = max_views# 图像编码(DINOv2)self.image_encoder = self.load_dinov2_backbone()# 长序列处理:8个 Mamba2+Transformer 交替块self.blocks = nn.ModuleList([ LongLRMBlock(d_model=768) for _ inrange(8) ])# 高斯解码(和GS-LRM类似)self.gaussian_queries = nn.Parameter(torch.randn(500_000, 768))self.gaussian_decoder = nn.TransformerDecoder(...)# 注意:这里预测50万个高斯(GS-LRM只预测16万)# 因为场景级重建需要更多高斯来覆盖大范围空间defforward(self, images, camera_poses):# images: (B, 64, 3, 512, 512) 最多64张图!# GS-LRM只能处理2-4张,Long-LRM能处理64张# ... 编码 → Mamba+Transformer交替 → 解码# 推理时间:~1.3秒(A100 80G)pass从GS-LRM到Long-LRM,本质上是从"看一张图猜3D"到"看64张图重建3D"。前者像一个人在猜一个他从没见过的物体长什么样,后者像一个测绘员用64张照片做建模。
iLRM:迭代优化回来了
LRM系列的最新进展(CVPR 2026)——iLRM做了一个有意思的折中:前馈大模型的框架保留,但加上迭代细化。
# iLRM的核心思路(简化)# 来源: iLRM: An Iterative Large 3D Reconstruction Model (CVPR 2026)classiLRM(nn.Module):""" 迭代式大重建模型 核心改进: 1. 不做一次性预测,而是多轮细化 2. 每一轮基于上一轮的结果 + 新的视图信息 3. 计算效率比GS-LRM/Long-LRM更高(不需要处理所有token) """def__init__(self, num_refinement_steps=3):super().__init__()self.num_steps = num_refinement_steps# 粗重建网络(和GS-LRM类似)self.coarse_model = GSLRM(num_views=4)# 细化网络:每轮迭代用一个轻量Transformerself.refinement_blocks = nn.ModuleList([ nn.TransformerEncoderLayer( d_model=768, nhead=12, dim_feedforward=1536, # 比主模型小 batch_first=True, )for _ inrange(num_refinement_steps) ])defforward(self, images, camera_poses):# 第1步:粗重建(4张图,快速出结果) coarse_gaussians = self.coarse_model(images[:, :4], camera_poses[:, :4])# 第2步:迭代细化 current_gaussians = coarse_gaussiansfor i inrange(self.num_steps):# 用当前的高斯渲染所有可用视角 rendered_views = self.render_all_views( current_gaussians, camera_poses )# 比较渲染结果和真实输入图像的差异 residuals = images - rendered_views# 用残差信息更新高斯参数# 只更新残差大的区域(稀疏更新,节省计算) update_mask = self.compute_update_mask(residuals) current_gaussians = self.refinement_blocks[i]( current_gaussians, residuals, update_mask, )return current_gaussians# iLRM的优势:# - 粗重建只用4张图(快)# - 细化阶段只更新有问题的区域(省算力)# - 最终质量接近用全部视图一次性预测,但计算量小得多产品层的对比:腾讯、字节、Tripo
上面的都是学术模型。落到产品上,2026年能用的文生3D/图生3D工具已经有好几个了。
# 2026年主流3D生成产品对比classAI3DModels:"""2026年主要玩家的3D生成能力""" MODELS = {"腾讯混元3D 3.0": {"输入":"文本 / 单图 / 多图 / 草图","输出":"带PBR材质的网格模型","速度":"~30秒","优势":"一站式平台(含动画),生态完整","短板":"底层3D表示是网格,不是高斯","网址":"3d.hunyuan.tencent.com", },"字节Seed3D 2.0": {"输入":"单图 / 文本","输出":"带PBR材质的高精度3D模型","速度":"~30秒","优势":"几何准、材质真、能拆件、能仿真","短板":"主要面向生产级3D资产,非场景级","发布时间":"2026年4月", },"Tripo P1.0": {"输入":"文本 / 图像","输出":"带纹理网格","速度":"~5秒(业界最快之一)","优势":"速度","短板":"几何质量不如Seed3D", },"World Labs Marble": {"输入":"文本 / 图像 / 视频","输出":"3DGS场景","速度":"分钟级","优势":"直接输出3DGS格式,可迭代编辑","短板":"生态还在建设中", },"Meshy V4": {"输入":"文本 / 图像","输出":"带PBR纹理的网格","速度":"~30秒","优势":"对话式迭代精炼","短板":"订阅制,不便宜", }, }defcompare(self):""" 一个关键发现: 大部分产品的底层3D表示还是网格(mesh),不是3DGS。 原因: - 网格可以直接导入Blender/Unity/UE - 3DGS虽然渲染好看,但还不是标准3D管线的一部分 - 直到2026年2月glTF才正式纳入3DGS扩展 但技术趋势是: - 先用扩散/LRM生成3DGS(渲染快、细节好) - 再把3DGS转成网格(工程可用) - World Labs是少数直接用3DGS做输出的 """for name, info inself.MODELS.items():print(f"\n{name}:")for k, v in info.items():print(f" {k}:{v}")实际跑起来之后的坑
坑一:文生3D"抽卡"——同一个prompt,每次生成不一样。
这是扩散模型的本质决定的。加随机噪声,去噪过程有随机性。你输入"一只穿西装的企鹅",第一次生成的是胖企鹅,第二次是瘦的,第三次西装颜色都不一样。
# 原因在代码里:defgenerate(self, prompt):# 初始噪声是随机的 x = torch.randn(1, 3, 512, 512) # ← 每次都不一样for t inrange(num_steps): x = self.denoise(x, prompt, t)return x商业产品的做法是给你种子(seed)——同一个seed,结果可复现。但你要找"好看的那个结果",还是得试好几次。
坑二:背面崩坏。
单图生3D的通病。AI只看到正面,背面是猜的。有时候背面长出来完全不合理——企鹅的后背长了个口袋,或者干脆没有背。
多图/长序列输入(Long-LRM)能缓解这个问题,但前提是你能拿到物体的多张图。纯文本生成,背面崩坏无解。
坑三:拓扑质量差,UV乱七八糟。
这是几乎所有AI 3D生成工具的共性问题。生成出来的模型,网格顶点分布没有规律——有的面10万个三角面片,有的面只有3个。UV展开要么没有,要么重叠。
对游戏和工业应用来说,这是致命伤。3D模型不光要"好看",还要"好用"——面数可控、UV干净、能绑骨骼、能做LOD。
# AI生成的网格 vs 手工建模的网格classMeshQuality:defcheck(self, mesh):return {"三角面数": mesh.num_faces, # AI生成:经常10万+,远超需求"最大长宽比": mesh.max_aspect_ratio, # AI生成:经常出现极端细长三角"UV覆盖率": mesh.uv_coverage, # AI生成:经常<50%,重叠严重"流形性": mesh.is_manifold, # AI生成:经常非流形"骨骼绑定": mesh.has_skin_weights, # AI生成:通常没有 }坑四:PBR材质"假"。
Seed3D 2.0宣传的重点是"真实PBR材质"。但实际生成的材质,法线贴图经常是从颜色图里算出来的"假法线"——看起来有凹凸,但光照角度变了就穿帮。
真正的PBR需要:
漫反射贴图(Albedo):AI生成的通常没问题 法线贴图(Normal Map):AI生成的很多是fake normal(从颜色推断) 粗糙度贴图(Roughness):AI通常用一个统一值 金属度贴图(Metallic):同上
一个完整的前馈3D生成流程
把上面的所有东西拼起来,一个能跑的工程流程长这样:
import torchfrom PIL import ImageclassTextTo3DGS:""" 完整的文本/图像到3DGS生成流程 结合了LRM的效率和扩散模型的质量 """def__init__(self, device='cuda'):self.device = device# 阶段1:文本→多视图(扩散模型)from diffusers import StableDiffusionPipelineself.text_to_multiview = self.load_multiview_model()# 输入prompt,输出6个角度的图(前、后、左、右、上、下)# 阶段2:多视图→3DGS(前馈大模型)self.gslrm = self.load_gslrm_model()# 输入6张图+相机位姿,输出3D高斯参数# 阶段3:3DGS→网格(可选,工程需要)# 3DGS转网格:用marching cubes或Marching Tetrahedra @torch.no_grad()defgenerate(self, text_prompt, num_steps=4):""" 端到端:文本prompt → 3DGS模型 总时间:~10秒(A100) """# 1. 文本生成多视图 multiview_images, camera_poses = self.text_to_multiview( text_prompt, num_views=6, # 6个标准视角 )# ~3秒# 2. 多视图→3DGS gaussian_params = self.gslrm( multiview_images.unsqueeze(0).to(self.device), # (1, 6, 3, 256, 256) camera_poses.unsqueeze(0).to(self.device), # (1, 6, 4, 4) )# ~0.5秒# 3. 验证:渲染几个检查视角self.validate(gaussian_params, multiview_images)# 4. 保存self.save_gaussians(gaussian_params, 'output.splat')return gaussian_paramsdefvalidate(self, gaussians, reference_images):"""生成质量检查"""# 从6个标准视角渲染,和参考图比较PSNR psnrs = []for i, (ref, pose) inenumerate(zip(reference_images, self.standard_poses)): rendered = self.render_from_gaussians(gaussians, pose) psnr = self.compute_psnr(rendered, ref) psnrs.append(psnr) avg_psnr = sum(psnrs) / len(psnrs)if avg_psnr < 20:print(f"警告:生成质量偏低 (PSNR={avg_psnr:.1f})")print("建议:换个prompt或调整seed重试")return avg_psnrdefsave_gaussians(self, params, path):"""保存为.splat格式"""# .splat格式:每个高斯28字节# 位置(12) + 缩放(6) + 旋转(4) + 颜色(4) + 不透明度(1) + 填充(1) N = params['position'].shape[0]withopen(path, 'wb') as f:for i inrange(N): pos = params['position'][i].cpu().numpy() scale = params['scale'][i].cpu().numpy() rotation = params['rotation'][i].cpu().numpy() color = params['color'][i].cpu().numpy() opacity = params['opacity'][i].cpu().numpy()# 写入二进制 f.write(pos.tobytes()) # 12 bytes, float32 × 3 f.write(scale.tobytes()) # 6 bytes, float16 × 3 f.write(rotation.astype('u1').tobytes()) # 4 bytes, uint8 × 4 f.write(color.astype('u1').tobytes()) # 3 bytes, uint8 f.write(opacity.astype('u1').tobytes()) # 1 byte, uint8 f.write(b'\x00') # 1 byte padding回到开头那个企鹅。
朋友说30秒生成的模型"能看但不能用"。我问他为什么不能用。
"UV没展开,面数10万但分布不均匀,法线贴图是假的,不能绑骨骼。"
"但你只是要个吉祥物放在游戏UI角落里,又不做主角。"
"这倒是……"
这就是AI 3D生成在2026年的真实定位:如果你需要一个快速出效果的原型,它已经很好用了。如果你需要一个生产级3D资产,它还差最后一步。
那最后一步——干净的拓扑、合理的UV、可用的法线——目前还是建模师的活。
不过话说回来,建模师30秒能干什么?喝半杯咖啡。
AI 30秒能生成一个带PBR材质的企鹅。
AI空间连接器专注空间智能技术拆解与产业分析 GIS+AI+具身智能三合一观察者
如果觉得本文有帮助,欢迎转发、在看、收藏
