 夜雨聆风
夜雨聆风大家好,我是林之愿。
5月7号,OpenAI一口气发了三个语音模型。
我当时看到消息的第一反应是,又发模型?最近OpenAI的发布节奏快到让人有点麻木了,GPT-5.5 Instant刚出来两天,这边又来三个语音模型。
但等我仔细看完技术细节之后,我的态度变了。
这次不是常规迭代,是一个信号,一个很明确的信号,语音AI要进入下一个阶段了。
先说说发了什么。三个模型,GPT-Realtime-2、GPT-Realtime-Translate、GPT-Realtime-Whisper,全部通过Realtime API提供。同时,Realtime API正式退出Beta,转为正式版。
三个模型各司其职。GPT-Realtime-2是旗舰,OpenAI自己说是「首个具备GPT-5级推理能力的语音模型」。GPT-Realtime-Translate做实时翻译,支持70多种输入语言,13种输出语言。GPT-Realtime-Whisper做流式语音转文字,边说边转。
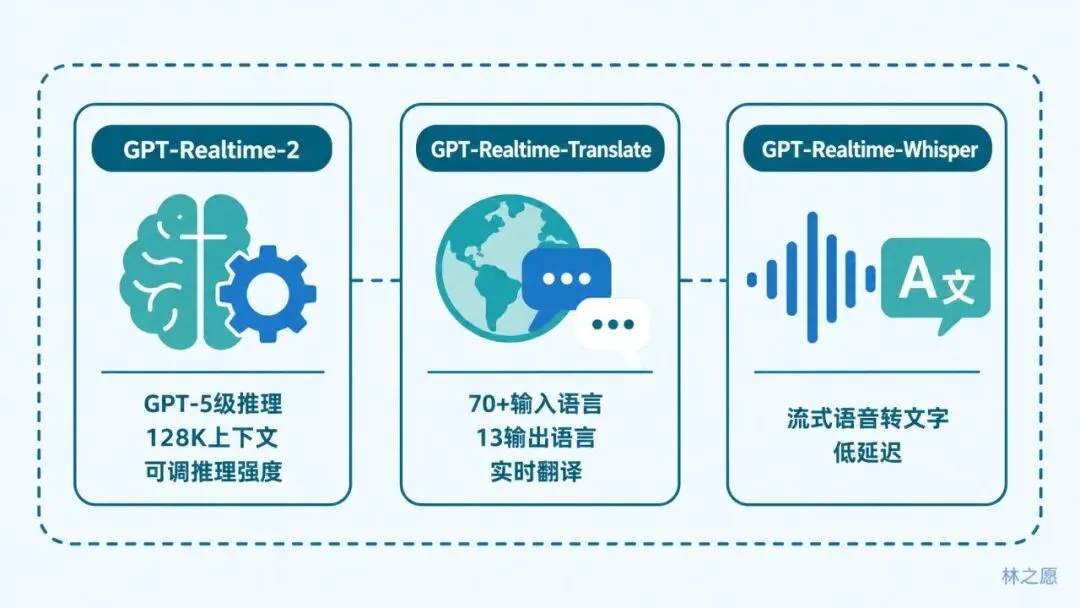
这里面真正让人兴奋的是GPT-Realtime-2。
你可能会问,之前的Realtime API不也能语音对话吗?ChatGPT的Voice Mode不也用了好一阵子了?
对,但这次不一样。
你先想想过去两年语音AI的格局。2023年ChatGPT Voice Mode出来的时候,大家确实被惊艳到了,终于能跟AI自然聊天了。但说实话,那个「自然」是有水分的。它说到底还是一个文字模型在背后跑,先把你说的话转成文字,文字模型处理完,再把回复转成语音。中间有一个转录到合成的管线,延迟在那里,推理能力也受限制。
更关键的是,它不能「做事」。你跟它聊天可以,但你让它帮你查个日程、订个餐厅、调个API,它做不了。它只是一个能说话的聊天机器人。
GPT-Realtime-2把这个架构打破了。
它是一个原生的语音对语音模型,音频进来,音频出去,推理在音频循环内部完成,不是在转录和合成之间的夹缝里挤出来的。OpenAI官方的说法是,这个模型能「边听、边推理、边调用工具、边处理打断」,全程不中断对话。
你品品这几个词,「边听边推理边调用工具边处理打断」,这不是在描述一个语音助手,这是在描述一个能听懂你在说什么、同时在后台帮你干活的同事。
这里有个概念值得展开聊聊。OpenAI提出了三种语音交互模式,Voice-to-Action、Systems-to-Voice、Voice-to-Voice。
Voice-to-Action最直观,你用嘴巴说出需求,AI推理之后调用工具去执行。比如你说「帮我看看明天下午三点有没有空,有的话就约个会」,它听懂了,去查你的日历,发现有空,直接帮你创建会议。全程语音,不需要你掏手机打字。
Voice-to-Voice是实时跨语言对话。Demo里展示了一个场景,两个人同时说不同语言,GPT-Realtime-Translate实时把双方的话翻译成对方能听懂的语言,连第三个人加入说第三种语言也没问题。
Systems-to-Voice是反过来,后台系统主动用语音通知你。比如你的航班延误了,系统不是发一条短信,而是直接用语音告诉你,还帮你查了改签方案。
三种模式加在一起,覆盖了语音交互的主要场景。这是第一次有一个统一的技术框架把这些场景全部打通。
说到技术细节,几个数字值得关注。
GPT-Realtime-2的上下文窗口是128K tokens。什么概念呢,一场正常的对话大概也就几千到一两万tokens,128K意味着它能记住很长很长的对话历史,不会聊着聊着就忘了前面说过什么。
推理强度可调节。你可以设置high、medium、low甚至minimal。推理越强,回答越聪明,但延迟也越高。Artificial Analysis测的数据是,high reasoning模式下首音频延迟2.33秒,minimal模式下1.12秒。这个延迟水平,说实话跟真人对话的反应速度还有差距,但已经是可以接受的范围了。
定价方面,音频输入每小时1.15美元,音频输出每小时4.61美元。换算成token计价的话,音频输入每百万tokens 32美元,音频输出每百万tokens 64美元。缓存输入的价格是每百万tokens 0.40美元,只有实时价格的八十分之一。这个缓存折扣力度很大,说明OpenAI很清楚,高频率重复调用的场景会是主要市场。
你可能会觉得这个价格不便宜。但你算一笔账,一个真人客服的时薪大概是15到25美元,还得加上培训成本、管理成本、办公场地成本。GPT-Realtime-2的音频输出每小时4.61美元,大概是一个真人客服成本的四分之一到五分之一。而且AI不需要休息,不需要社保,不会情绪化,不会离职。
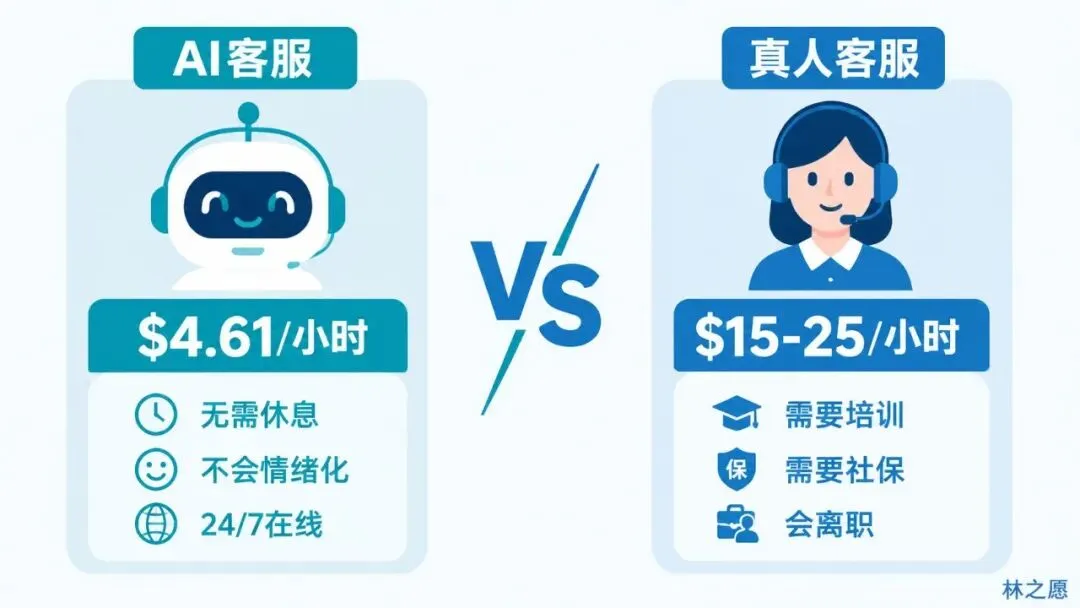
当然,AI客服目前还不能完全替代真人,特别是在处理复杂投诉、需要同理心的场景。但作为一个「第一道防线」,处理80%的常规问题,把真正复杂的case转给真人,这个方案已经非常有吸引力了。
还有一个细节值得说说隐私和安全。OpenAI在公告里特别提到,Realtime API完全支持EU Data Residency,也就是欧盟的数据驻留要求。这对企业客户来说是个硬性要求,GDPR合规不是可选项,是必须的。OpenAI在这个时间点强调这一点,说明他们很清楚企业市场的门槛在哪里。
另外,Realtime API还支持企业隐私承诺,企业可以放心地把敏感数据交给这个API处理,不用担心数据被拿去训练模型或者被第三方访问。
再看基准测试。
Big Bench Audio是一个语音对语音推理测试。GPT-Realtime-1.5在这个测试上的分数是81.4%,GPT-Realtime-2直接跳到了96.6%。从81到96,这不是渐进优化,是代际跃迁。

Conversational Dynamics基准测试,GPT-Realtime-2拿了96.1%。
但也有不那么亮眼的数字。Audio MultiChallenge测试的是多轮对话中的复杂推理能力,GPT-Realtime-1.5是34.7%,GPT-Realtime-2提升到了48.5%。48.5%,刚过半,说明在真正复杂的真实多轮对话场景里,AI还是会犯错的。Awesome Agents的评价很直接,「still fails most hard audio reasoning tasks」。
这个数据其实挺重要的。它提醒我们,虽然GPT-Realtime-2在单项测试上表现亮眼,但在真实世界的复杂场景中,它离「完美」还远。我们在兴奋的同时也要保持清醒。
说到竞品,不得不提Google。
Google的Gemini 3.1 Flash Live在Big Bench Audio上也拿到了96.6%,跟GPT-Realtime-2持平。而且Google一直把自己定位成更低成本的替代方案。所以如果你是开发者在选平台,OpenAI和Google现在在基准测试上打了个平手,选择可能更多取决于生态系统、定价、和你已有的技术栈。
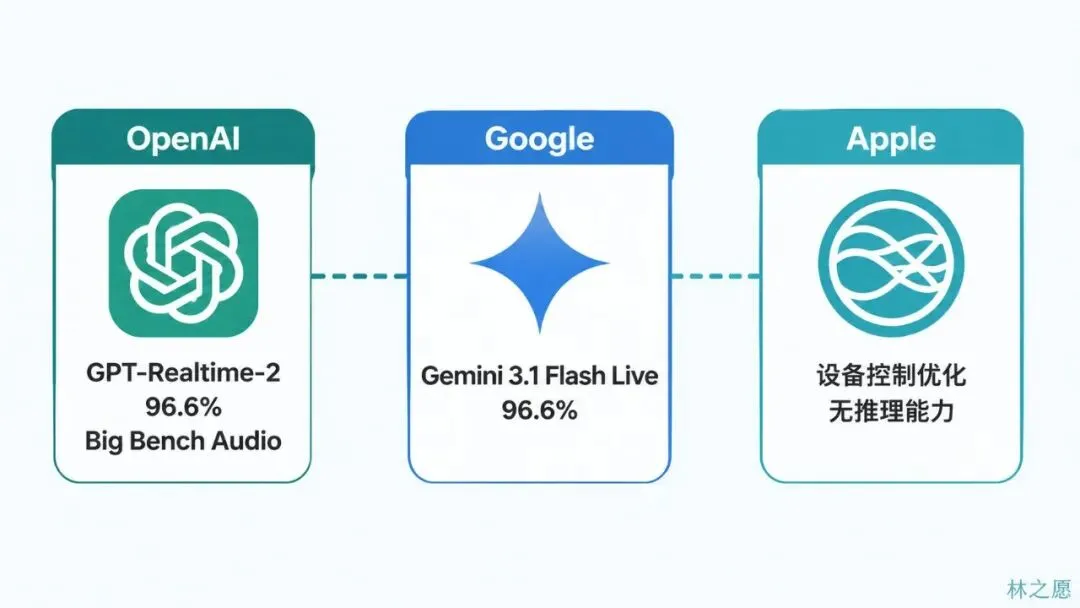
Apple这边就比较尴尬了。Siri的定位一直是设备控制优化,设闹钟、打电话、定闹钟。eMarketer在2026年2月有一份报告,标题就很说明问题,「How ChatGPT OpenAI are eclipsing Siri and Alexa」。传统语音助手面临的不是竞争问题,是生存问题。
你想想,Siri从2011年发布到现在,15年了,还是那个「帮你设个闹钟」的水平。ChatGPT Voice Mode从2023年到现在才三年,已经能跟你自然对话了。GPT-Realtime-2更是直接跳到了「边听边想边做事」的层次。这不是弯道超车,是降维打击。
Amazon的Alexa也是一样的困境。它们当年的愿景是「语音优先」,但技术限制让这个愿景一直停留在「语音命令」的层面。现在OpenAI用大模型的能力,真正实现了「语音智能」。传统语音助手如果不做根本性的架构升级,被淘汰只是时间问题。
不过也要公平地说一句,Apple和Amazon的优势在于硬件生态。Siri集成在每一台iPhone里,Alexa集成在每一台Echo里。OpenAI目前还没有自己的硬件入口,ChatGPT的语音能力是通过App和API提供的。如果Apple哪天决定接入GPT-Realtime-2级别的能力,凭借它的硬件生态,还是有一战之力的。
但问题是,Apple会这么做吗?还是会坚持自己的路线?这可能是2026年下半年最值得关注的科技战略决策之一。
还有一个很有趣的角度。The Next Web的报道提到了一个行业痛点,过去企业要部署语音Agent,得自己拼四五个组件,Whisper或Deepgram做转录,ElevenLabs或Cartesia做文字转语音,GPT-4或Claude做推理,中间还得自己写轮换和打断逻辑。GPT-Realtime-2是一个模型干了所有这些活,音频输入音频输出,推理在内部完成,中间不需要你自己去拼管线。
这对开发者来说是真正的效率提升。
举个具体的例子。假设你是一个创业公司的CTO,想给自己的App加一个语音客服功能。按照以前的做法,你得先选一个语音转文字服务,再选一个文字转语音服务,再选一个大语言模型做推理,然后自己写中间的编排逻辑,处理轮换、打断、上下文切换这些棘手问题。整套系统搭下来,没有三五个月搞不定,还得养一个专门的团队去维护。
现在呢,一个API调用,GPT-Realtime-2全部搞定。音频进去,音频出来,中间的推理、工具调用、打断恢复,模型自己处理。你只需要定义好工具的接口,告诉它「查日历就调这个API」「订餐厅就调那个API」,剩下的它自己来。
这不是效率的量变,是质变。
再看一个更直观的场景。Digital Trends在报道里展示了一个Demo,三个人同时说三种语言,英语、西班牙语、中文,GPT-Realtime-Translate实时把每个人的话翻译成另外两个人能听懂的语言。没有延迟,没有卡顿,就像联合国的同声传译,但不需要那个玻璃房子里的翻译官。
过去这种实时翻译能力是高端会议的专属,价格贵得离谱。现在一个API就能实现,成本可能比请一个翻译实习生还低。
还有一个场景我觉得特别值得关注,医疗问诊。想象一下,一个农村诊所的医生,面对一个说方言的患者,双方语言不通。以前要么找翻译,要么比划。现在手机上开一个语音Agent,患者说方言,AI实时翻译成普通话给医生听,医生说普通话,AI实时翻译成方言给患者听。同时AI还能在后台做初步的症状分析,提醒医生注意某些关键指标。
这个场景不是科幻,是GPT-Realtime-2和GPT-Realtime-Translate组合起来就能实现的事情。
教育领域也是一样。传统的在线教育是看视频、做题、看答案。有了实时语音AI,可以变成真正的互动教学。学生说「我不理解这个概念」,AI不是弹出一段文字解释,而是用语音跟你对话,根据你的回答动态调整讲解方式,直到你真正理解为止。
这比任何录播课都有效,因为它是真正的一对一辅导。
当然,普通用户最关心的问题,什么时候能在ChatGPT里用上这个级别的语音能力?
坦率的讲,目前这三个模型只在API里提供,是给开发者用的。ChatGPT的Voice Mode什么时候升级到GPT-Realtime-2,官方没有给出时间表。但你想想,既然API已经GA了,模型能力已经就位了,ChatGPT端的升级应该不会太远。
我个人猜测,可能在未来一两个月内,ChatGPT的Voice Mode就会有一次大的升级。但这个纯属个人判断,没有官方依据,标注一下「待验证」。
回到这篇文章的核心观点。
语音AI的演进可以分成三代。第一代是命令式,Siri、Alexa、小爱同学,你跟它说一句,它回一句,不会上下文,不会推理。第二代是对话式,ChatGPT Voice Mode为代表,能自然聊天了,但还是一个「说话的聊天机器人」,不能帮你做事。第三代是推理式,GPT-Realtime-2就是这一代的开端,它能边听边想边说,能在对话中调用工具、处理打断、执行复杂任务。
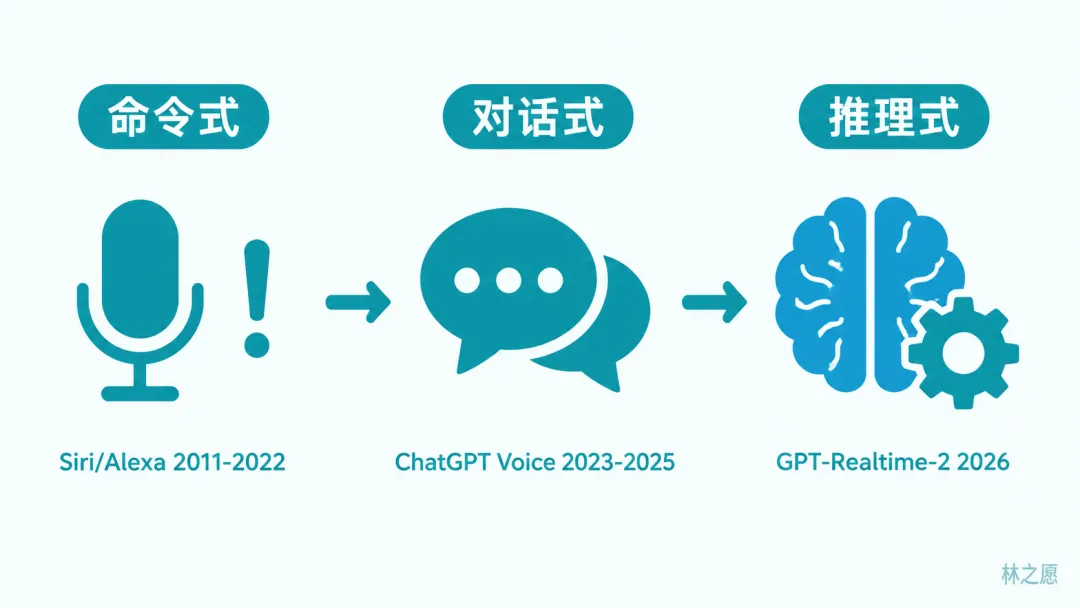
从命令到对话,花了十多年。从对话到推理,只用了两年。
这个速度,说实话,有点吓人。
但Audio MultiChallenge的48.5%也在提醒我们,这个「同事」目前只考了个及格分。它能处理大部分日常场景,但在复杂多轮推理、微妙语境理解、突发状况处理上,还有不小的提升空间。
不要急着把所有客服都裁掉。
也不要觉得这跟自己没关系。
我觉得最合理的姿态是,开始关注,开始试用,找到自己领域里语音交互能解决的具体问题。你是做客服的,试试用GPT-Realtime-2搭一个demo看看效果。你是做教育的,想想实时语音辅导的场景。你是做跨境业务的,GPT-Realtime-Translate可能就是你一直在等的那个同声传译方案。
技术的临界点往往不是某一天突然到来的,而是你回头一看,发现它已经悄悄到了。
语音交互的临界点,我觉得已经到了。
回想一下,2023年ChatGPT Voice Mode出来的时候,大家的反应是「哇,AI居然能说话了」。2024年各种语音模型陆续发布,大家的反应是「嗯,语音AI在进步」。2026年GPT-Realtime-2出来,我的反应是「完了,语音AI真的要改变一切了」。
从「能说话」到「能聊天」到「能做事」,每一步都比上一步快得多。技术演进的速度在加速,而我们适应的速度往往跟不上。
所以我的建议是,不要等到所有人都在用的时候才开始关注。现在就去试试,现在就开始想,你的领域里有哪些场景可以用语音AI来优化。早一步行动的人,往往能拿到最大的红利。
这篇文章写完的时候,我突然想到一件事。十年前我们还在用诺基亚的按键手机发短信,十年后我们可能对着空气说话就能完成所有工作。技术的变化总是比我们想象的快,而我们能做的就是保持关注,保持学习,保持行动。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
/ 作者:林之愿
/ 投稿或爆料,请联系邮箱:1626440040@qq.com
- • [GPT-Realtime-2技术规格、定价、API文档](来源:OpenAI:https://developers.openai.com/api/docs/models/gpt-realtime-2)
- • [Big Bench Audio 96.6%、Conversational Dynamics 96.1%、首音频延迟数据](来源:Artificial Analysis:https://x.com/ArtificialAnlys/status/2052486470469140777)
- • [三个模型详细解读与行业分析](来源:The Next Web:https://thenextweb.com/news/openai-gpt-realtime-2-voice-models)
- • [Audio MultiChallenge基准测试与S2S模型评估](来源:Scale Labs:https://labs.scale.com/leaderboard/audiomc)
- • [传统语音助手被ChatGPT超越的行业分析](来源:eMarketer:https://www.emarketer.com/content/faq-on-voice-ai--how-chatgpt-openai-eclipsing-siri-alexa)
