 夜雨聆风
夜雨聆风研究AIOps已有大半年,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。
作为一个运维,我最不愿意干的事情莫过于从一个复杂的业务系统里找故障根因。虽然说老运维通过经验就可以判断出问题大概出在哪里,但是当你发现每次出现的问题都不一样时,你就会非常痛苦!尤其是,大半年被告警吵醒,然后修复问题。
我想说的是,现在有了AI之后,这个排障的效率是可以大大提升的。今天这篇文章跟大家说一说,我是如何借助OpenCode做问题排障的。
01 | 思路
首先我对这个运维助手的定位很明确:它不是自动运维机器人,它也不是一个万能ChatBot,它更像一个懂代码、懂配置、懂日志、懂Kubernetes的值班副驾。
我希望它能做四件事:
1)帮我快速收集现场
比如线上服务出现 502,它可以自动帮我查:
Deployment 状态;
Pod 状态;
Service 和 Endpoints;
Ingress 配置;
Kubernetes Events;
最近日志;
Prometheus 指标;
最近一次发布变更。
以前这些动作需要我在多个系统之间来回切换,现在可以交给助手统一整理。
2)帮我形成证据链
运维排障最怕“感觉是这个问题”。我希望助手的每个判断都必须有证据,比如:
哪个指标异常;
哪个 Pod 不 Ready;
哪条日志显示健康检查失败;
哪个配置和实际应用行为不一致;
哪次发布之后问题开始出现。
没有证据,就不能下结论。
3)帮我生成问题解决方案
如果问题来自配置,比如 readinessProbe 写错、资源限制不合理、Ingress 配置遗漏,那么助手可以直接在 Git 仓库里生成 YAML 补丁。
但它不能直接改生产,它只能生成:
Git diff;
修复建议;
验证命令;
回滚方案。
最终发布必须经过人或 CI/CD 审批。
4)帮我沉淀 Runbook
每次排障结束后,助手还能把过程整理成 Runbook:
现象;
影响范围;
根因;
排查步骤;
修复方式;
预防措施。
这样下一次遇到类似问题,新人也能照着处理。
02 | 整体架构
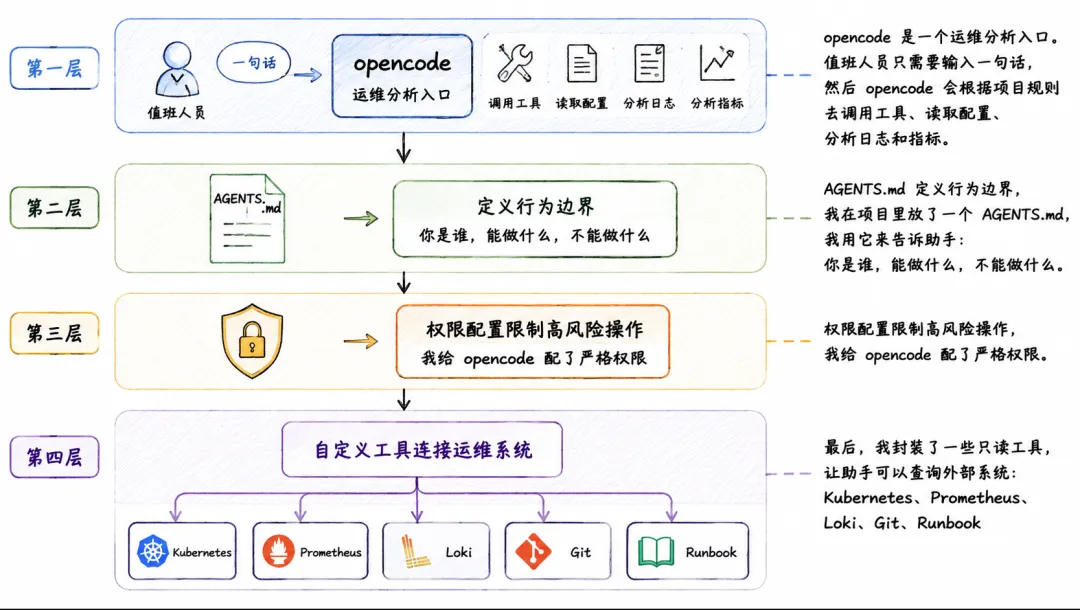
第一层:opencode 作为智能入口
Opencode 本身是一个 AI coding agent,擅长读代码、改代码、理解项目上下文。而我并没有把它只当成“写代码工具”,而是把它变成一个运维分析入口。
值班人员只需要输入一句话,比如:
生产环境 order-api 出现 502 告警,请帮我排查。
要求只读查询生产环境,不要执行重启、删除、扩缩容、发布等操作。
然后 opencode 会根据项目规则去调用工具、读取配置、分析日志和指标。
第二层:AGENTS.md 定义行为边界
我在项目里放了一个AGENTS.md,我用它来告诉助手:你是谁,能做什么,不能做什么。核心规则大概是这样:
你是 SRE 运维助手,目标是帮助值班人员完成排障、变更前检查和修复补丁生成。重要原则:1. 默认先诊断,不直接执行生产变更。2. 对 Kubernetes 生产环境只允许读操作。3. 禁止自动执行 delete、scale、restart、helm upgrade、terraform apply 等高风险命令。4. 所有修复必须优先生成 Git 补丁或 PR 建议。5. 输出必须包含现象、影响范围、证据、根因假设、推荐修复、回滚方案和验证命令。6. 证据不足时,必须明确说明不能确认。
这一步很关键。因为做运维助手,最重要的不是“让 AI 更聪明”,而是先让 AI 守规矩。
第三层:权限配置限制高风险操作
我给 opencode 配了严格权限。
大体原则是:
允许读仓库文件;
允许执行安全查询;
修改配置文件需要在指定目录内;
高风险生产命令全部禁止;
不确定的命令必须人工确认。
例如:
{"permission": {"*": "ask","read": {"*": "allow","*.env": "deny","*.pem": "deny","*kubeconfig*": "deny"},"edit": {"manifests/**": "allow","runbooks/**": "allow"},"bash": {"git status*": "allow","git diff*": "allow","kubectl get *": "allow","kubectl describe *": "ask","kubectl logs *": "ask","kubectl delete *": "deny","kubectl scale *": "deny","kubectl rollout restart *": "deny","helm upgrade *": "deny","terraform apply *": "deny"}}}
这相当于给助手套了一个“安全笼子”。它可以看,可以分析,可以写补丁,但不能擅自操作生产环境。
第四层:自定义工具连接运维系统
最后,我封装了一些只读工具,让助手可以查询外部系统:
Kubernetes工具:查Deployment、Pod、Service、Endpoints、Events;
Prometheus工具:查5xx、延迟、可用副本数;
Loki工具:查最近日志;
Git工具:对比变更;
Runbook工具:生成事故记录。
其中Kubernetes工具只允许白名单命令,比如:
kubectl getkubectl describekubectl logs
禁止:
kubectl deletekubectl scalekubectl rollout restartkubectl apply
这样既能让 AI 看到现场,又不会让它越权操作。03 | 从一个小场景开始落地
我没有一开始就做一个“大而全”的 AIOps 平台。而是从一个非常具体的问题开始,比如从这个问题开始:order-api 出现 502 时,助手能不能帮我完成一次完整排障?落地过程分了四步。
第一步:先整理标准排障路径
我先把人工排障流程写下来。比如 502 问题,通常会看:
kubectl -n prod-order get deploy order-apikubectl -n prod-order get pod -l app=order-apikubectl -n prod-order get svc order-apikubectl -n prod-order get endpoints order-apikubectl -n prod-order get ingresskubectl -n prod-order get events --sort-by=.lastTimestamp
再结合监控:order-api 5xx rateorder-api p95 latencyorder-api available replicas
再结合日志:
最近 30 分钟 error 日志readiness probe 相关日志health check 相关日志
这一步的重点是:先把人的经验变成清晰流程,再让助手去执行。
第二步:把流程写进 Runbook
我给每类故障写了一个Runbook。例如:
runbooks/order-api-502.md里面包括:常见原因;
检查顺序;
关键命令;
判断标准;
修复建议;
回滚方式。
这样助手不是凭空猜,而是基于团队已有经验进行分析。
第三步:限制助手只能做低风险动作
这是整个方案能不能上线的关键。我给它定了一个原则:生产环境只读,修复进入Git。
也就是说,助手发现问题后,不能直接执行:
kubectl applyhelm upgradekubectl rollout restart
它只能修改仓库中的配置文件,然后给出:git diffkubectl diff验证命令回滚命令
而真正上线由人来决定。
第四步:让它输出固定格式
为了避免助手输出一堆散乱分析,我要求它每次排障都按这个结构输出:
1. 现象2. 影响范围3. 已收集证据4. 根因假设5. 推荐修复6. 风险评估7. 验证命令8. 回滚方案9. 后续预防措施
这样每次排障结果都可以直接贴进事故群、工单或者复盘文档。
我的运维大模型课上线了,目前还有很大优惠。扫码咨询优惠(粉丝优惠力度大)

