 夜雨聆风
夜雨聆风❝前面我们介绍了AI工具|Positron中使用Claude Code(接入国产大模型),介绍了如何配置国产主流模型。那么模型配置好了,我们如何使用呢?确保 AI 输出专业、可控、可追溯。那就需要提供良好的「AI提示词」。我根据我的一些实践,构建了RCTIOC的框架来撰写AI提示词。
❞
「R」ole(角色约束)
「C」ontext(研究背景)
「T」ask(任务目标)
「I」nput(输入信息)
「O」utput(输出格式)
「C」heck(风险检查)
RCTIOC框架介绍
R|角色约束 Role
明确模型的协作身份和回答风格
C|研究背景 Context
明确任务背景、证据边界和使用场景
T|任务目标 Task
强调 expected outcome 和 success criteria
I|输入信息 Input
提供必要材料、数据、文献、代码或方案文本
O|输出格式 Output
明确最终交付物、格式、层级和可用性。
C|风险检查 Check
设置 validation rules 和风险核查标准
「下面介绍1个案例,使用RCTIOC框架撰写AI提示词:」
案例:样本量计算
我们以发表在Lancet Diabetes Endocrinol杂志的一篇文章为例,文章详细信息如下:
「文章标题」:Once-weekly albiglutide versus once-daily liraglutide in patients with type 2 diabetes inadequately controlled on oral drugs (HARMONY 7): a randomised, open-label, multicentre, non-inferiority phase 3 study 「期刊」:Lancet Diabetes Endocrinol 「影响因子」:41.8 「原文网址」:https://www.thelancet.com/journals/landia/article/PIIS2213-8587(13)70214-6/abstract 「人群」:口服药控制不佳的2型糖尿病患者 「主要终点」:第32周HbA1c相对基线的变化 「组别」:Albiglutide(试验组)、 Liraglutide(阳性对照组),按照1:1随机分配 「非劣界值」:0.3%
现在设想一个情景:「如果我是这个临床试验的项目统计师,在试验设计阶段,如何借助AI,让AI帮忙计算这个样本量?我只需要做最终把关即可」。现在我们按照RCTIOC框架撰写提示词,让AI帮我们完成这个事情。
「STEP 1」 按照RCTIOC框架撰写提示词
【角色约束 R】你是一名靠谱的临床试验生物统计师,熟悉ICH E9/E9(R1)指导原则,精通R、SAS等样本量计算工具。需基于已确立的统计方法论,所有公式和参数必须注明来源(教材/指南/文献),绝不臆测或虚构任何公式和数值。【研究背景 C】本研究为一项[随机开放非劣效]设计的[3期]临床试验,注册监管机构为[NMPA/FDA],适应症为[2型糖尿病],干预措施为[试验药 vs 对照药],研究目的为[非劣效]。主要终点为[第32周糖化血红蛋白(HbA1c)相对基线变化]。【任务目标 T】请完成以下三项任务:① 首先给出完整的统计假设和标准的样本量计算公式;② 使用R软件编写完整的代码,计算样本量。代码可使用R包或自带函数,但需符合样本量计算公式【输入信息 I】请基于以下参数计算(若某参数未提供影响样本量计算请告知我补充):• 主要终点:[第32周糖化血红蛋白(HbA1c)相对基线变化]• 终点类型:[连续型]• 临床疗效:[试验组 vs 对照组 实际差值为0]• 标准差 σ:[共同标准差为1.1%]• 检验水准 α:[0.025 单侧]• 把握度 1-β:[93%]• 非劣界值:[0.3%],本研究终点指标为低优指标• 分组比例 r(试验:对照):[1:1]• 预期脱落率:[20%]• 样本量计算方法:两样本t检验,不要使用正态近似法【输出格式 O】按以下结构输出:编写R代码,将样本量最终结果输出表格,表格变量名包括:每组人数、考虑脱落每组人数【风险检查 C】在给出最终答案前,请自我核查:✦ R代码是否能实际完整运行?与样本量计算公式是否匹配?✦ 监管接受度:如果我要在 NMPA/FDA 的递交中使用这个方法,审评员是否认可该方法?「STEP 2」 打开Positron—>Continue插件,将上述提示词发送给AI,如下图所示,得到了样本量计算结果:每组319例,考虑脱落每组399例
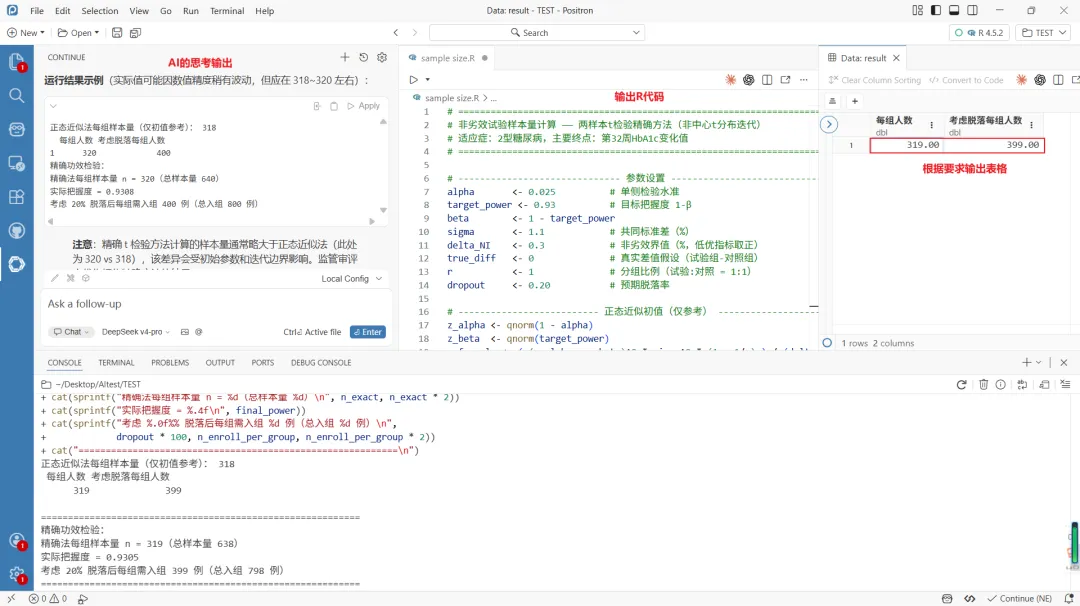
AI生成的R代码:
# =============================================================================# 非劣效试验样本量计算 —— 两样本t检验精确方法(非中心t分布迭代)# 适应症:2型糖尿病,主要终点:第32周HbA1c变化值# =============================================================================# ------------------------------ 参数设置 ----------------------------------alpha <- 0.025# 单侧检验水准target_power <- 0.93# 目标把握度 1-βbeta <- 1 - target_powersigma <- 1.1# 共同标准差(%)delta_NI <- 0.3# 非劣效界值(%,低优指标取正)true_diff <- 0# 真实差值假设(试验组-对照组)r <- 1# 分组比例(试验:对照 = 1:1)dropout <- 0.20# 预期脱落率# -------------------------- 正态近似初值(仅参考) -------------------------z_alpha <- qnorm(1 - alpha)z_beta <- qnorm(target_power)n_formula <- ( (z_alpha + z_beta)^2 * sigma^2 * (1 + 1/r) ) / (delta_NI - true_diff)^2n_init <- ceiling(n_formula)cat("正态近似法每组样本量(仅初值参考):", n_init, "\n")# ------------------ 精确非中心t分布功效函数 -------------------------------# 检验统计量:T = [(X̄_T - X̄_C) - δ_NI] / (Sp * sqrt(1/n_T + 1/n_C))# H0下 T ~ t(df= n_T+n_C-2), H1下 T ~ t(df, ncp)# 其中 ncp = (true_diff - δ_NI) / (σ * sqrt(1/n_T + 1/n_C))## 功效 = P( T < t_{α, df} | ncp ) (拒绝域为左侧,因低优且H1: diff < δ_NI)power_t_noninferior <- function(n, delta_NI, sigma, true_diff = 0, alpha = 0.025, r = 1) { n_T <- n n_C <- n * r df <- n_T + n_C - 2# 非中心参数(真实差值 - 界值,预期为负) ncp <- (true_diff - delta_NI) / (sigma * sqrt(1/n_T + 1/n_C))# 临界值:左侧拒绝域,下侧 alpha 分位数 t_crit <- qt(alpha, df)# 功效 = P(T < t_crit | ncp) power <- pt(t_crit, df, ncp = ncp)return(power)}# ------------------ 二分搜索最小整数样本量(满足功效要求) ----------------# 搜索范围合理增大,以防精确解需更大样本n_low <- max(2, n_init - 20)n_high <- 5000# 确保上界功效足够while (power_t_noninferior(n_high, delta_NI, sigma, true_diff, alpha, r) < target_power) { n_high <- n_high * 2if (n_high > 1e5) stop("未找到满足功效的 n_high,请检查参数")}# 二分查找while (n_high - n_low > 1) { n_mid <- floor((n_low + n_high) / 2) pow_mid <- power_t_noninferior(n_mid, delta_NI, sigma, true_diff, alpha, r)if (pow_mid >= target_power) { n_high <- n_mid } else { n_low <- n_mid }}n_exact <- n_highfinal_power <- power_t_noninferior(n_exact, delta_NI, sigma, true_diff, alpha, r)# ------------------ 考虑脱落率的样本量调整 --------------------------------n_enroll_per_group <- ceiling(n_exact / (1 - dropout))# ------------------ 输出结果表格 ------------------------------------------result <- data.frame( `每组人数` = n_exact, `考虑脱落每组人数` = n_enroll_per_group, check.names = FALSE)print(result, row.names = FALSE)cat("\n===========================================================\n")cat("精确功效检验:\n")cat(sprintf("精确法每组样本量 n = %d(总样本量 %d)\n", n_exact, n_exact * 2))cat(sprintf("实际把握度 = %.4f\n", final_power))cat(sprintf("考虑 %.0f%% 脱落后每组需入组 %d 例(总入组 %d 例)\n", dropout * 100, n_enroll_per_group, n_enroll_per_group * 2))cat("===========================================================\n")# ============================================================# 补充:也可用power.t.test(R 内置,基于非中心 t 分布,非正态近似)# ============================================================「视频演示如下」:(无声音讲解,仅是动态演示)
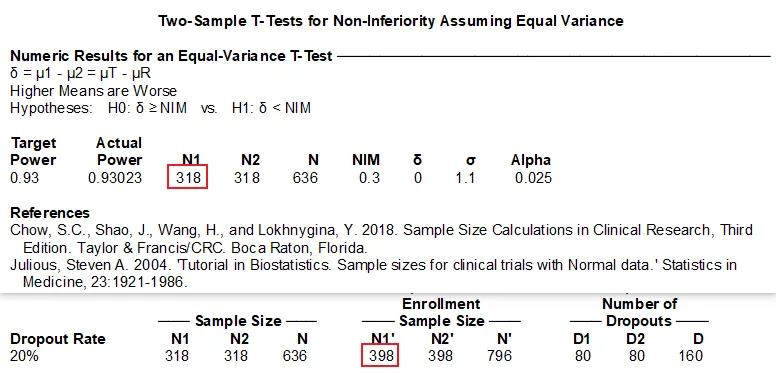
「STEP 3」 自己最终把关数据,可以看出AI给出的结果和原文发表的结果基本一致,同时与自己复核的结果基本一致。

小结
对于医学科研,我们可以针对不同的情形撰写特定的AI提示词,比如样本量计算、统计分析模型、表格生成、图形绘制、文献阅读等等,但框架可以按照RCTIOC 提示词撰写建议「重结果,轻流程」。避免冗余的提示词 希望这个RCTIOC框架可以助力你的工作和学习
