 夜雨聆风
夜雨聆风这是 llama.cpp 源码系列的第二篇。上一篇我们拆解了推理引擎 GGML,理解了张量、Arena、延迟执行、Galloc、KV Cache、线程模型的完整骨架。但还有一个问题没回答:模型文件本身是怎么设计的?从磁盘上的一个文件,到内存里一组可用的 ggml_tensor,中间经历了什么?
这就是本文要讲的内容。读完你会理解 GGUF 的二进制格式、mmap 为什么能做到"瞬间"加载、以及一个 HuggingFace 模型怎么转成 GGUF 用 llama.cpp 跑起来。
引言: 先说清楚这篇文章讲什么——以及为什么需要它
1 模型文件格式的本质——把"一堆数字"和"它们是什么"存进磁盘
抛开所有框架、所有工具,一个模型文件最底层到底存了什么?
两样东西:数据和元数据。
数据就是权重——训练结束后冻结下来的那几十亿个浮点数。元数据告诉你这些数字怎么用——它们按什么形状排列、属于哪一层、叫什么名字、模型总共多少层、用什么 tokenizer。
就这么简单。所有的格式之争,本质上都是在争"数据和元数据怎么组织、怎么打包、怎么读取"这三个问题的不同答案。
2 判断一个格式好不好的六个维度
拿到一个模型文件格式,可以从六个角度评价它:
| 安全性 | ||
| 自描述 | config.json + tokenizer.json 等额外文件来补充 | |
| mmap 友好 | ||
| 单文件 | ||
| 零依赖 | ||
| 量化支持 |
六个维度不是孤立的——一个维度的选择会影响其他维度。下面逐个格式看它们在这六个维度上的取舍。
3 格式一:PyTorch pickle(.pt / .pth / .bin)——最古老,也最危险
PyTorch 从 2016 年诞生起就用 Python 的 pickle 做序列化。Pickle 的设计初衷是"把任意 Python 对象存到磁盘,以后原样读回来"——包括类定义、函数、甚至 lambda。
怎么存的:torch.save(model.state_dict(), "model.pt") → Python 的 pickle 模块把整个 state_dict(一个 OrderedDict,key 是层名,value 是 tensor)序列化成二进制。
问题在哪:pickle 的反序列化过程会执行 pickle 数据中的任意 Python 代码。这意味着一个恶意构造的 .pt 文件可以在你加载时删掉你的文件、窃取你的数据、安装后门。HuggingFace 早期大量使用这种格式,后来因为安全问题逐步迁移到 safetensors。
为什么推理不能用它:需要 Python + PyTorch 运行时(几百 MB)、不支持 mmap(必须一次性读到内存)、不支持量化(权重以 FP32/FP16 存储)、不是自描述的(需要额外代码定义模型类才能加载)。
4 格式二:Safetensors——安全替代 pickle
HuggingFace 在 2022 年推出了 safetensors。它的核心卖点是:纯数据,不能执行代码。
怎么存的:文件头 8 字节是 JSON 元数据的长度(uint64),后面紧跟一段 JSON 描述每个 tensor 的名字、形状、数据类型、在文件中的偏移量,再后面就是原生的 tensor 二进制数据。
Safetensors 文件布局:┌──────────────────────────────────────────────┐│ Header (8 bytes): JSON 部分的长度 │├──────────────────────────────────────────────┤│ JSON Metadata: ││ "token_embd.weight": {shape:[768,6400], ││ dtype:"F16", offsets:[0, 9830400]} ││ "blk.0.attn_q.weight": {...} ││ ... │├──────────────────────────────────────────────┤│ Tensor Data (raw bytes): ││ [9.8MB of token_embd] [1.1MB of attn_q] ...│└──────────────────────────────────────────────┘
为什么它安全:JSON 不是图灵完备的——解析 JSON 不能执行代码。Tensor 数据是纯二进制,直接 memcpy 到目标地址。
为什么推理不能直接用:它只解决了"安全存储",没有解决"高效推理"。Safetensors 的元数据(JSON)在文件最前面,但这只是 tensor 级别的元数据——没有模型架构信息(多少层、什么 attention)、没有 tokenizer、没有推理超参数。而且它不支持量化格式内嵌——权重总是以 FP32/FP16/BF16 存储。
5 格式三:ONNX——跨框架的"通用语言"
ONNX(Open Neural Network Exchange)是微软和 Facebook 在 2017 年发起的。它的目标是:用 PyTorch 训练,用 TensorRT 推理,中间用 ONNX 做桥梁。
ONNX 用 Protobuf 定义了一个完整的计算图——不仅有权重,还有操作节点(Conv、MatMul、ReLU...)。这比 safetensors 更进一步:safetensors 只知道"有这么些 tensor",ONNX 知道"这些 tensor 怎么用"。
为什么 LLM 推理不用它:ONNX 是为视觉模型(固定输入大小、静态图)设计的。LLM 需要动态形状(batch 可变、序列长度可变)、KV Cache、autoregressive 循环——这些都是 ONNX 的弱项。加上 onnxruntime 的依赖链仍然很重。
6 格式四:AWQ / GPTQ——GPU 服务端的量化格式
这两个是专门为 GPU 服务端推理设计的量化格式,不是独立的文件格式——它们通常以 PyTorch checkpoint 或 safetensors 为载体,内部包含量化后的权重和量化参数。
- AWQ
(Activation-aware Weight Quantization):按激活值的大小分配量化精度,重要通道保留更高精度 - GPTQ
(GPT Post-Training Quantization):用 Hessian 矩阵逐层优化量化方案,质量接近原始
它们的问题:必须配合特定的推理引擎(vLLM、TGI、TensorRT-LLM),不能在 llama.cpp 中直接使用。因为它们的量化方案(per-channel scaling、分组量化)和推理逻辑是耦合的。
7 格式五:GGUF——专为本地推理而生
GGUF 的诞生动机很纯粹:前面四种格式没有一个适合"在用户的破笔记本上跑大模型"。
PyTorch pickle 不安全 + 需要 Python。Safetensors 安全但没有模型级元数据 + 需要 Python 库。ONNX 不适合动态 LLM。AWQ/GPTQ 绑定了 GPU 服务端推理引擎。
GGUF 的设计目标一句话:打开文件,一切就绪。 不需要 config.json,不需要 tokenizer.json,不需要 Python,不需要 GPU。一个文件,纯 C 读取,mmap 瞬间加载,量化格式内嵌,跨平台。
8 六维对比:一张表看懂定位
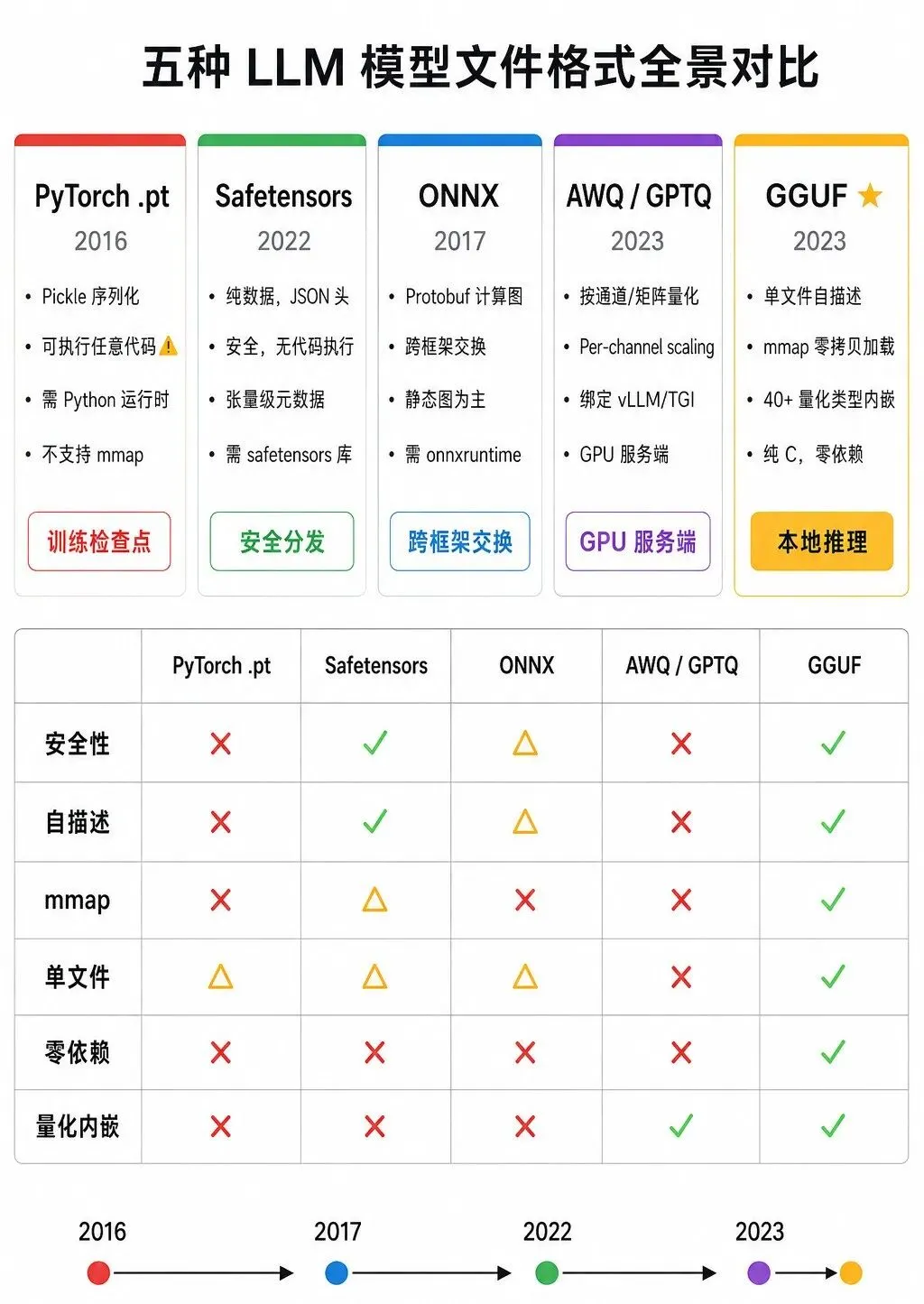
[图1:五种模型格式全景对比] — 五列卡片横向排列,每列标注格式名、诞生年份、核心特征。底部六维对比网格,GGUF 全部 ✓。时间线 2016→2023。
| GGUF | ✓ | ✓ KV+Tensor | ✓ | ✓ | ✓ 纯C | ✓ 40+ | 2023 | 本地推理 |
*Safetensors 通常分片存储(每个文件 < 5GB),需索引文件来拼接。但也可以不分片。
9 完整管线:一个模型从训练到部署的全路径
[训练框架:PyTorch / JAX / TensorFlow]↓ 输出训练好的权重PyTorch .pt (pickle, 不安全)↓ 或直接存为Safetensors (安全, 但仍是"通用数据容器")↓[格式转换 + 量化] ← 这一步是本文的主题├─→ AWQ/GPTQ → vLLM/TGI (GPU 服务器, 高并发)├─→ ONNX → onnxruntime (跨平台, 但不适合LLM)└─→ GGUF → llama.cpp (本地/边缘, 零依赖)↓llama-quantize (可选: FP16→Q4_K_M)↓llama-cli -m model.gguf
GGUF 在这条管线中的位置很清楚:它是从"训练生态"到"部署生态"的桥梁。 上游的 safetensors 是训练框架的"出口格式",下游的 GGUF 是推理引擎的"入口格式"。中间的转换脚本(convert_hf_to_gguf.py)做两件事:把 safetensors 的 FP16 权重拷过来,把 HuggingFace config.json 和 tokenizer.json 转成 GGUF 的 KV 元数据。
10 这篇文章的写法
上一篇我们对着 8000 行 GGML 源码深度拆解,内容非常多。这篇会短一些——因为 GGUF 本身就是一个故意做得很简单的格式。它的设计哲学和 GGML 一脉相承:把事情做到刚好能用,然后停手。打开 ggml/include/gguf.h,前 31 行注释就是完整的文件格式规范。不需要 RFC 文档,不需要单独维护 wiki,源码即规范。
我第一次读 GGUF 相关代码的时候挺惊讶的——"?"总共就这两个文件:gguf.cpp(1556 行,读写实现)和 gguf.h(约 200 行,接口定义)。但越简单的设计越难做——你要在"足够用"和"不复杂"之间找到精确的平衡点。
第一章:GGUF 的二进制格式——五段结构
1.1 规范就在源码注释里
打开 ggml/include/gguf.h,前 31 行就是完整的文件格式规范。不用翻文档,不用查 wiki——源码注释就是规范本身。这很 GGML——把复杂的事情说得尽可能简单。
1. File magic "GGUF" (4 bytes) ← 文件头,固定 0x474755462. File version (uint32_t) ← 当前是 33. Number of ggml tensors in file (int64_t) ← 有多少个权重张量4. Number of key-value-pairs in file (int64_t) ← 有多少个元数据键值对5. For each KV pair: ← 遍历所有 KV 对1. The key (string)2. The value type (gguf_type)3a. If array: type + count + binary of elements3b. Otherwise: binary of value6. For each ggml tensor: ← 遍历所有张量1. The tensor name (string)2. The number of dimensions (uint32)3. For each dimension: size (int64)4. The tensor data type (int32)5. The tensor data offset in tensor data blob (uint64)7. The tensor data binary blob (optional, aligned) ← 实际权重数据
画成图就是五段:
┌──────────────────────────────────────────────┐│ 1. Magic "GGUF" (4 bytes) │├──────────────────────────────────────────────┤│ 2. Header ││ version = 3 (uint32) ││ n_tensors = 90 (int64) ││ n_kv = 33 (int64) │├──────────────────────────────────────────────┤│ 3. KV Metadata (33 pairs, variable length) ││ "general.architecture" → "qwen3" ││ "qwen3.block_count" → 8 ││ "qwen3.embedding_length" → 768 ││ "tokenizer.ggml.tokens" → ["<|endoftext|>",││ "<|im_start|>",││ ...] ││ ... (30 more) │├──────────────────────────────────────────────┤│ 4. Tensor Info Array (90 entries) ││ [0] "token_embd.weight" ││ dims=[768, 6400], type=F16, offset=0 ││ [1] "blk.0.attn_norm.weight" ││ dims=[768], type=F32, offset=9.8M ││ [2] "blk.0.attn_q.weight" ││ dims=[768, 768], type=F16, offset=... ││ ... (87 more) ││ [89] "output_norm.weight" ││ dims=[768], type=F32, offset=127.8M │├──────────────────────────────────────────────┤│ 5. Tensor Data (aligned to 32 bytes) ││ 实际的权重值,按 Tensor Info 的 offset 定位 ││ 总大小 = sum of all tensor sizes │└──────────────────────────────────────────────┘
1.2 存储类型系统
GGUF 的 KV 元数据支持 12 种基本类型(ggml/include/gguf.h:53-68):
enum gguf_type {GGUF_TYPE_UINT8 = 0, // 无符号 8 位整数GGUF_TYPE_INT8 = 1,GGUF_TYPE_UINT16 = 2,GGUF_TYPE_INT16 = 3,GGUF_TYPE_UINT32 = 4,GGUF_TYPE_INT32 = 5, // 枚举用这个GGUF_TYPE_FLOAT32 = 6, // 浮点数GGUF_TYPE_BOOL = 7, // 布尔值(存储为 int8)GGUF_TYPE_STRING = 8, // 字符串(长度 uint64 + 内容)GGUF_TYPE_ARRAY = 9, // 数组(类型 + 数量 + 元素列表)GGUF_TYPE_UINT64 = 10,GGUF_TYPE_INT64 = 11, // 大整数GGUF_TYPE_FLOAT64 = 12,};
字符串的存储方式是 string_length (uint64) 后跟 C 字符串(无 null 终止符)。这样读取时知道要读多少字节,不用扫描 null。
1.3 真实例子:MiniMind 的 GGUF 文件
用 llama.cpp 自带的 llama-gguf 工具看一眼真实的 MiniMind 文件:
$ llama-gguf minimind-f16.gguf r nHeader:magic = GGUFversion = 3n_tensors = 90n_kv = 33KV[0]: general.architecture = "qwen3" ← 决定了构建器KV[1]: general.type = "model"KV[2]: general.name = "Minimind 3"KV[3]: general.version = "3"KV[9]: qwen3.block_count = 8 ← 层数KV[10]: qwen3.context_length = 32768 ← 训练上下文KV[11]: qwen3.embedding_length = 768 ← 嵌入维度KV[12]: qwen3.feed_forward_length = 2432 ← FFN 维度KV[13]: qwen3.attention.head_count = 8 ← Q 头数KV[14]: qwen3.attention.head_count_kv = 4 ← KV 头数 (GQA!)KV[15]: qwen3.rope.freq_base = 1000000.0 ← RoPE 频率KV[19]: general.file_type = 1 ← 1 = F16KV[21]: tokenizer.ggml.model = "gpt2" ← tokenizer 类型KV[22]: tokenizer.ggml.pre = "qwen2" ← pre-tokenizerKV[23]: tokenizer.ggml.tokens = ["<|endoftext|>", ...] ← 6400 tokensTensor[0]: name="token_embd.weight", dims=[768,6400], type=F16, offset=0Tensor[1]: name="blk.0.attn_norm.weight", dims=[768], type=F32, offset=9.8M...Tensor[85]: name="blk.7.attn_output.weight", dims=[768,768], type=F16, offset=125MTensor[89]: name="output_norm.weight", dims=[768], type=F32, offset=127.9M
33 个键值对告诉 llama.cpp 关于这个模型的一切。有了它们,不需要任何额外的配置文件。
1.4 为什么 Tensor Info 在数据区前面
这不是随意的。回想上一篇讲的 mmap:GGUF 文件被 mmap 映射后,程序先读取前面的元数据区(几十 KB),这些页面被加载到物理内存。然后它知道了每个张量在文件里的精确偏移——token_embd.weight 从字节 X 开始、blk.0.attn_q.weight 从字节 Y 开始。
这些偏移量直接作为 tensor->data 的地址,不需要 fread。当程序第一次访问某个张量的数据时,操作系统触发缺页中断,按需加载对应的 4KB 页。 如果某些层的权重在当前推理中没有被用到(比如只跑前几层的情况),它们对应的页面永远不会被加载。
GGUF 的格式设计唯一的指导原则就是"怎么让 mmap 用得最爽"。
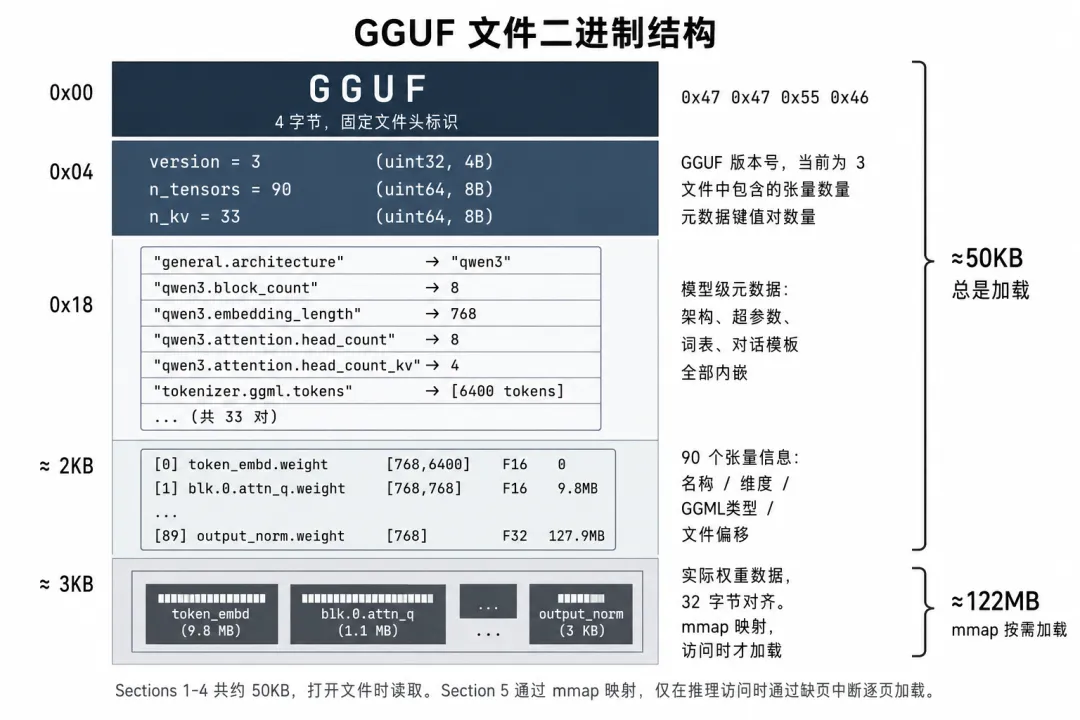
[图2:GGUF 文件五段二进制结构] — 纵向展示 Magic → Header → KV 元数据 → Tensor Info → Tensor Data 的完整布局,标注每段大小和用途。
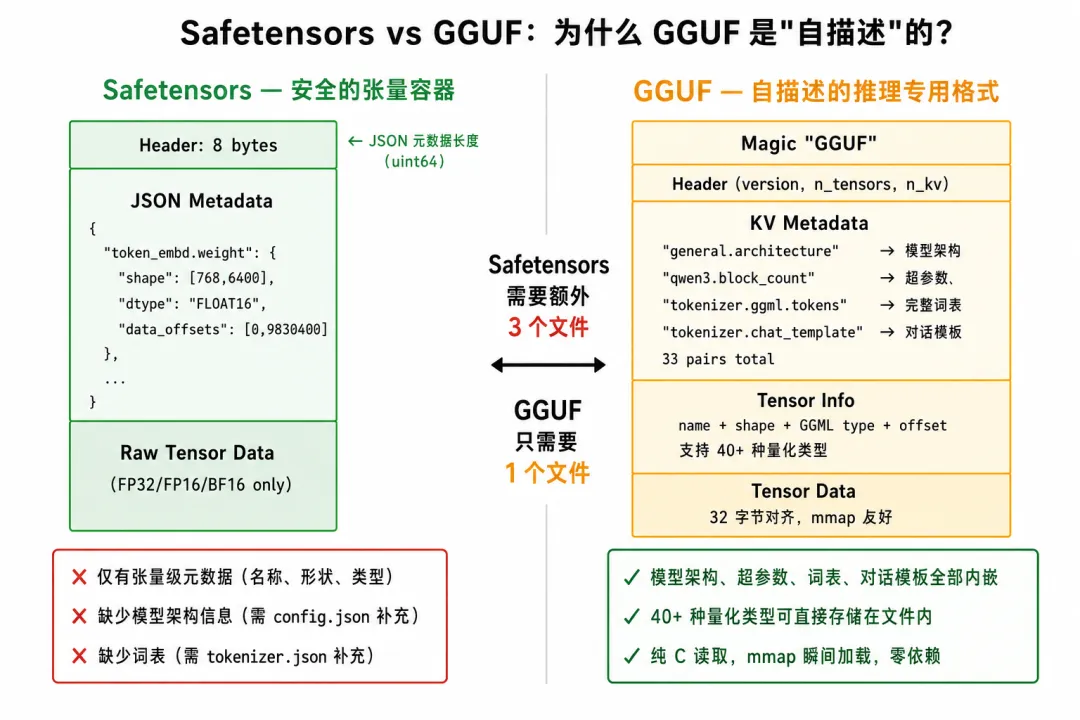
[图3:Safetensors vs GGUF 格式布局对比] — 看完 GGUF 的五段结构后,这里并排对比 Safetensors(Header→JSON→Data)和 GGUF(Magic→Header→KV→TensorInfo→Data)。核心差异:Safetensors 只存张量级元数据,GGUF 内嵌模型架构、超参数、词表、对话模板。
第二章:GGUF 的内存表示——gguf_context
2.1 两个数据结构:gguf_context 和 gguf_tensor_info
当 gguf_init_from_file 被调用时,它创建两个 C++ 结构(ggml/src/gguf.cpp:217):
struct gguf_context {uint32_t version = GGUF_VERSION;std::vector<struct gguf_kv> kv; // 所有 KV 键值对std::vector<struct gguf_tensor_info> info; // 所有张量的信息size_t alignment = GGUF_DEFAULT_ALIGNMENT; // 对齐要求(默认 32)size_t offset = 0; // 数据区在文件中的起始位置size_t size = 0; // 数据区的总字节数void * data = nullptr; // 数据区指针(mmap 地址 或 malloc)};
gguf_kv 存一个键值对的类型和值,gguf_tensor_info 存一个张量的名字、形状、ggml 类型、在数据区中的偏移量。
2.2 读取流程:gguf_init_from_file
这个函数是 GGUF 的核心实现(ggml/src/gguf.cpp,约 200 行)。把它拆成四步,每一步都很直白:
步骤 1:验证"这真的是个 GGUF 文件"。 读前 4 个字节,看是不是 GGUF(0x47475546)。如果不是——直接报错。然后读版本号和你最关心的两个数字:文件里有几个张量、几个 KV 对。
uint32_t magic = read_u32(file); // 必须是 "GGUF"uint32_t version = read_u32(file); // 当前是 3uint64_t n_tensors = read_u64(file); // 例如 90(MiniMind)uint64_t n_kv = read_u64(file); // 例如 33
步骤 2:读所有 KV 元数据。 循环 n_kv 次,每次读一个 key(字符串)+ type(枚举)+ value(按 type 决定长度)。GGUF 用 type 字段告诉读取者"接下来多少字节、怎么解析"——这是自描述格式的核心。
for (int i = 0; i < n_kv; i++) {string key = read_string(file); // "general.architecture"int32_t type = read_i32(file); // GGUF_TYPE_STRING = 8// 根据 type 决定怎么读 valueswitch (type) {case GGUF_TYPE_STRING: value = read_string(file); break; // "qwen3"case GGUF_TYPE_UINT32: value = read_u32(file); break; // 8case GGUF_TYPE_ARRAY: /* 先读元素类型+数量,再逐个读 */ break;// ...}ctx->kv.push_back({key, type, value});}
步骤 3:读所有 Tensor Info。 循环 n_tensors 次,每次读名字、维度数组、ggml 类型、在数据区的偏移量。这一步读完,每个张量的"身份证"就齐了,但数据还躺在磁盘上。
for (int i = 0; i < n_tensors; i++) {string name = read_string(file); // "blk.0.attn_q.weight"uint32_t n_dims = read_u32(file); // 2int64_t ne[4] = {1,1,1,1};for (int d = 0; d < n_dims; d++)ne[d] = read_u64(file); // [768, 768]ggml_type type = (ggml_type)read_i32(file); // GGML_TYPE_F16uint64_t offset = read_u64(file); // 在数据区偏移 1.1MBctx->info.push_back({name, ne, type, offset});}
步骤 4:处理数据区。 此时文件指针恰好在数据区开头。记录下这个位置和数据区大小,然后用 mmap 或 malloc+fread 建立访问通道。数据区本身可能非常大(几十 GB),但在 mmap 模式下,这一行执行完函数就返回了——数据没有真正加载到物理内存。
第三章:llama_model_loader——从 gguf_context 到 llama_model
3.1 加载器做什么
src/llama-model-loader.cpp (1695 行) 负责把 gguf_context 转换成 llama_model。上一篇我们学过 llama_model 的结构——它包含所有层的权重张量引用。
转换步骤分四步:
第 1 步:验证和读取超参数。 从 KV 元数据中提取架构信息:
// llama-model-loader.cpp 内部std::string arch = gguf_get_val_str(meta, "general.architecture");// arch = "qwen3"int n_layer = gguf_get_val_u32(meta, "qwen3.block_count"); // 8int n_embd = gguf_get_val_u32(meta, "qwen3.embedding_length"); // 768int n_head = gguf_get_val_u32(meta, "qwen3.attention.head_count"); // 8int n_head_kv = gguf_get_val_u32(meta, "qwen3.attention.head_count_kv"); // 4// ... 十几个超参数全部从 KV 对中提取
第 2 步:确定模型架构。general.architecture = "qwen3" 触发架构匹配链:
"qwen3" → llama-arch.cpp → LLM_ARCH_QWEN3 → llama-model.cpp → 选择 builder在 llama-arch.cpp (906 行) 中有一个巨大的架构特征表,记录了每种架构的"能力":
// llama-arch.cpp 内部(简化)static const std::map<llm_arch, llm_arch_features> ARCH_FEATURES = {{LLM_ARCH_LLAMA, {.has_attention=true, .has_rope=true, ...}},{LLM_ARCH_QWEN3, {.has_attention=true, .has_rope=true,.has_qk_norm=true, .has_swiglu=true, ...}},{LLM_ARCH_MAMBA, {.has_ssm=true, ...}},// ... 130+ 个架构};
第 3 步:创建张量壳子。 为每个权重在 model_ctx 里创建 ggml_tensor。llama.cpp 用一套简洁的命名规则来组织这些张量:
模型级(不属于任何层):token_embd — 词嵌入矩阵,把 token ID 映射成 768 维向量output_norm — 输出前的 RMS 归一化output — 输出投影(lm_head),把 768 维映射回 6400 维词表每层(blk = block,即 Transformer 层):blk.{i}.attn_norm — 注意力前的归一化blk.{i}.attn_q — Q 投影权重(768×768)blk.{i}.attn_k — K 投影权重(384×768,GQA 的 KV 头只有 Q 的一半)blk.{i}.attn_v — V 投影权重(384×768)blk.{i}.attn_output — 注意力输出投影(768×768)blk.{i}.ffn_gate — FFN 的门控权重(SwiGLU 的 gate 分支)blk.{i}.ffn_up — FFN 的上投影(SwiGLU 的 up 分支)blk.{i}.ffn_down — FFN 的下投影(把 2432 维压回 768 维)
代码里通过一个 create_tensor lambda 批量创建:
// llama-model.cpp:3074auto create_tensor = [&](tensor_name, shape, flags) -> ggml_tensor * {// 在 model_ctx (Arena, no_alloc=true) 里分配 ggml_tensor 结构体return ml.create_tensor(hparams, ..., tensor_name, shape, flags);};for (int il = 0; il < n_layer; il++) {layers[il].wq = create_tensor(TN::ATTN_Q, {n_embd, n_embd}, il);layers[il].wk = create_tensor(TN::ATTN_K, {n_embd_k_gqa, n_embd}, il);// ... 每个层创建 ~13 个权重张量}
我第一次看到这个循环的时候,脑子里闪过上一篇的 llm_build_qwen3——那个 builder 也是用同样的循环在 graph_ctx 里创建计算图节点。一个负责"把权重从文件读到内存",一个负责"把权重变成计算图"。两人用同一个循环结构,各司其职。很整齐。
90 个 ggml_tensor 壳子创建完毕,全部 data=NULL。
第 4 步:分配 backend_buffer,落实数据。 这是上一篇第二章 2.3 讲过的逻辑:
// llama-model.cpp:8187buf = ggml_backend_alloc_ctx_tensors_from_buft(model_ctx, buft);// → 遍历 model_ctx 中所有 tensor// → 分配 122MB 连续 buffer(CPU malloc / GPU cudaMalloc / mmap)// → 逐个设置 tensor->data = buffer_base + offset// → 逐个设置 tensor->buffer = buf// → 如果 mmap:data 指针直接指向 GGUF 文件的虚拟映射地址
3.2 分片文件的加载
FAT32 文件系统单文件最大 4GB。几十 GB 的大模型必须拆成多个分片发布。GGUF 的分片命名遵循 NAME-%05d-of-%05d.gguf 格式:
model-00001-of-00004.gguf (0~4GB)model-00002-of-00004.gguf (4GB~8GB)model-00003-of-00004.gguf (8GB~12GB)model-00004-of-00004.gguf (12GB~16GB)
llama.cpp 加载分片的过程(llama-model-loader.cpp 内部):
1. 检测文件名中的 -%05d-of-%05d 模式 → 推断有 4 个分片2. 打开第一个分片 → 读取 Header + KV 元数据(后续分片的 Header 也被读取做校验,但 KV 元数据只从第一个文件取)3. 读取所有分片的 Tensor Info→ 每个分片有自己的 Tensor Info,但 n_tensors 总数相同→ 加载器把同名的 Tensor Info 合并:offset 加上前面分片的数据累积偏移4. mmap 数据区→ 每个分片独立 mmap,拼接成逻辑上连续的地址空间→ 或 malloc 一份大 buffer,把各分片数据依次 memcpy 进去关键约束:一个张量的数据不能跨分片边界。GGUF 的分片是对齐到张量边界的——不会有张量的前半段在分片 N、后半段在分片 N+1 的情况。
加载器用 llama_get_list_splits 自动检测和拼接(llama-model-loader.cpp:78)。这也是为什么 GGUF 的 Tensor Info 里有 offset 字段——对单文件来说它是"文件内偏移",对分片来说它是"合并后的逻辑偏移"。
第四章:mmap 深度配合——GGUF 的核心设计哲学
4.1 传统做法 vs mmap——差了几个数量级
传统 fread 做法:fopen → malloc(100GB) → fread(100GB) → fclose。对于 100GB 的模型,你需要 100GB 空闲物理内存。fread 是把整个文件从头到尾拷贝到 malloc 出的 buffer 里——100GB 的数据搬运,即使 SSD 读写 3GB/s 也要半分钟以上。
mmap 做法:fopen → mmap(建立映射) → fclose。核心是这一行系统调用:
void * data = mmap(NULL, // 让内核选地址file_size, // 映射整个数据区PROT_READ, // 只读MAP_PRIVATE, // 私有映射(修改不影响原文件)fd, // 文件描述符data_offset // 从文件的第 data_offset 字节开始映射);
这行代码不拷贝任何数据。它只是在进程的页表里建了一条记录:"虚拟地址 0x7f0000000000 到 0x7f0XXXXXXXXX,对应磁盘上 model.gguf 的第 data_offset 到末尾"。操作系统返回"好的,已记录"——函数就返回了。
缺页中断怎么工作? 当程序第一次通过 tensor->data 访问某个权重值(比如 blk.0.attn_q.weight->data[0]):
CPU: 我要读虚拟地址 0x7f0000100000 的 4 字节MMU: 这个地址对应的物理页还没加载 → 触发 page fault (中断#14)内核: 从页表查出 → 对应 model.gguf 文件偏移 1.1MB→ 在物理内存找一页空闲的 4KB→ 发起磁盘 I/O:读 model.gguf 的 1.1MB~1.1MB+4KB→ 把数据写入物理页→ 更新页表:虚拟地址 0x7f0000100000 → 物理页 X→ 返回用户态CPU: 重试刚才的读操作 → 成功读到数据程序: 完全不知道刚才发生了什么
整个过程中,程序看到的只是"读了一个内存地址,拿到了值"。内核在背后默默做了磁盘 I/O。
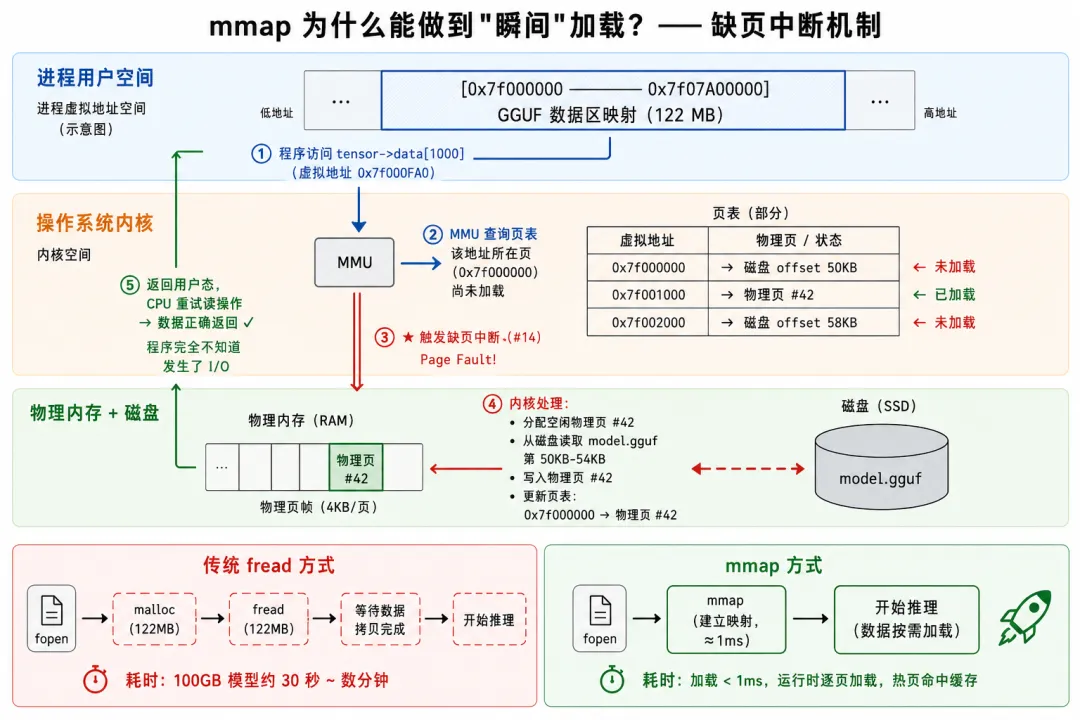
[图4:mmap 缺页中断五步机制] — 三层结构(用户态/内核/物理内存),展示 ①mmap 映射 → ②程序访问 → ③缺页中断 → ④内核处理 → ⑤数据返回的完整流程。
4.2 mmap 和 GGUF 的配合——设计即优化
GGUF 的五段结构让 mmap 的效果最大化:
Header (16B) + KV (几KB) + Tensor Info (几KB) → 必须立即读,但只有几十 KBTensor Data (122MB~100GB) → mmap 映射,按需加载
程序只需要立刻读 Header + KV + Tensor Info(总共几十 KB),然后对数据区做 mmap。推理时访问到哪个张量,操作系统加载哪个页面。没访问到的永远不占物理内存。
如果 GGUF 把元数据放在数据区后面会怎样? 那读取元数据前,必须先跳过整个数据区——要么 fread 整个文件(太慢),要么 seek 到末尾(不支持 mmap 流式读取)。GGUF 的"元数据在前"布局是专门为 mmap 设计的。
多轮对话的叠加优化:第一轮推理时,每层的权重按顺序被访问,操作系统逐页加载。第二、第三轮时,这些页面已经在前几轮中被加载过了,直接从操作系统的 page cache(页缓存)命中——没有磁盘 I/O。操作系统会自动把"热"页面留在内存,"冷"页面换出。用户感受到的效果是:"第一轮稍微慢一点,后面越跑越快。" 这是 mmap + OS page cache 自带的免费午餐。
4.3 GGUF 的默认对齐:32 字节
GGUF 数据区默认 32 字节对齐(GGUF_DEFAULT_ALIGNMENT = 32)。这个数字不是随便选的——对应 AVX/AVX2 的 256 位寄存器宽度,也是 DDR4/DDR5 内存总线的 burst 大小。对齐的张量数据可以一次内存访问完成,不对齐的需要两次。而且 32 是 4096(页大小)的约数,确保张量不会跨页边界——跨页边界的张量会触发两次缺页中断,而不是一次。
第五章:从 HuggingFace 到 GGUF——转换工具的工作原理
5.1 convert_hf_to_gguf.py 做了什么
这个 13423 行的 Python 脚本是 GGUF 生态的关键。它读 HuggingFace 格式的模型目录,输出 GGUF 文件:
HuggingFace 目录:├── config.json → 读出架构名、层数、维度 → 写入 GGUF 的 KV 区├── tokenizer.json → 读出所有 token → 写入 GGUF 的词表 KV 对├── model-00001-of-N.safetensors → 读出所有权重 → 写入 GGUF 的数据区└── ...↓ convert_hf_to_gguf.pyGGUF 文件:├── Header (magic + version + n_tensors + n_kv)├── KV Metadata (33 对: architecture=qwen3, block_count=8, ...)├── Tensor Info (90 个: name, shape, type, offset)└── Data (122MB 对齐后的权重值)
5.2 支持的架构
在 convert_hf_to_gguf.py 内部,每种架构是一个 ModelBase 的子类。以 Qwen3 为例:
@ModelBase.register("Qwen3ForCausalLM")classQwen3Model(TextModel):model_arch = gguf.MODEL_ARCH.QWEN3
@ModelBase.register 装饰器把 HuggingFace 的类名("Qwen3ForCausalLM")和 GGUF 的架构名(QWEN3)绑定。当脚本读到一个 HuggingFace 模型的 config.json 里 "architectures": ["Qwen3ForCausalLM"],自动匹配到这个类。
5.3 如果你有一个全新的模型
需要三步(llama.cpp 官方文档 docs/development/HOWTO-add-model.md 对此有说明):
假设你有一个叫 MyModel 的新架构,HuggingFace 类名是 MyModelForCausalLM,结构和 LLaMA 基本一样。需要改三个地方:
第 1 步:Python 端注册(convert_hf_to_gguf.py,约 20 行)
@ModelBase.register("MyModelForCausalLM") # ← config.json 的 architectures 字段classMyModelModel(TextModel):model_arch = MODEL_ARCH.MYMODEL# 告诉转换器"我的张量叫什么名字":GGUF 命名 → HuggingFace 命名_model_tensors = {MODEL_TENSOR.TOKEN_EMBD: "model.embed_tokens",MODEL_TENSOR.OUTPUT: "lm_head",MODEL_TENSOR.ATTN_Q: "model.layers.{bid}.self_attn.q_proj",MODEL_TENSOR.ATTN_K: "model.layers.{bid}.self_attn.k_proj",# ... 其他层映射}
转换时脚本遍历 safetensors 文件,按这个映射把 model.layers.0.self_attn.q_proj.weight 重命名为 GGUF 标准名 blk.0.attn_q.weight,同时把 FP16/BF16 数据原样拷贝。
第 2 步:注册张量布局(gguf-py/gguf/constants.py,约 30 行)
classMODEL_ARCH(IntEnum):MYMODEL = auto() # ← 新增# 告诉 GGUF 这个模型有哪些类型的张量,按什么顺序MODEL_TENSORS[MODEL_ARCH.MYMODEL] = [MODEL_TENSOR.TOKEN_EMBD, MODEL_TENSOR.OUTPUT_NORM, MODEL_TENSOR.OUTPUT,MODEL_TENSOR.ATTN_NORM, MODEL_TENSOR.ATTN_Q, MODEL_TENSOR.ATTN_K,MODEL_TENSOR.ATTN_V, MODEL_TENSOR.ATTN_OUT,MODEL_TENSOR.FFN_NORM, MODEL_TENSOR.FFN_GATE, MODEL_TENSOR.FFN_UP,MODEL_TENSOR.FFN_DOWN,]
第 3 步:写 C++ Graph Builder(src/models/mymodel.cpp)
如果架构和 LLaMA 基本一样,直接参考 src/models/llama.cpp 模板——embedding → N层 Transformer → lm_head。每层:attn_norm → QKV → RoPE → Flash Attn → output → 残差 → ffn_norm → gate/silu × up → down → 残差。约 100~200 行 C++。
做完后还需要在 llama-arch.cpp 注册、llama-model.cpp 关联 llm_type、src/models/models.h 声明。这些都是模板化操作——复制已有架构的注册代码,改名字即可。
第 1+2 步约 50 行 Python(做完就能转 GGUF),第 3 步取决于架构复杂度。llama.cpp 官方文档 docs/development/HOWTO-add-model.md 有完整指南。
第六章:一个完整的加载流程——从命令行到你第一个 token
把上面所有内容串起来。当你在终端输入:
llama-cli -m minimind-f16.gguf -p "你好"发生的完整流程:
llama_model_load_from_file("minimind-f16.gguf")│├─► gguf_init_from_file("minimind-f16.gguf")│ → 读 Header: version=3, n_tensors=90, n_kv=33│ → 读 33 个 KV 对 → gguf_context.kv│ → 读 90 个 Tensor Info → gguf_context.info│ → mmap 数据区 → gguf_context.data = 0x7f...│├─► llama_model_loader 构造│ → 读 "general.architecture" = "qwen3"│ → 读 超参数: n_layer=8, n_embd=768, n_head=8, ...│ → 读 tokenizer: 6400 个 token, BPE merges│├─► 确定架构 → LLM_ARCH_QWEN3 → llm_build_qwen3│├─► 在 model_ctx(Arena, no_alloc=true)创建 90 个 ggml_tensor│ token_embd, output_norm, output│ blk.0.attn_q, blk.0.attn_k, blk.0.attn_v, blk.0.attn_output│ blk.0.attn_q_norm, blk.0.attn_k_norm│ blk.0.ffn_gate, blk.0.ffn_down, blk.0.ffn_up│ ... (8层)│ 全部 data=NULL│├─► ggml_backend_alloc_ctx_tensors_from_buft(model_ctx, cpu_buft)│ → 计算总大小 = 122 MB│ → mmap 映射: 每个 tensor->data 直接指向 GGUF 文件内对应偏移│ → 或 malloc: 分配 122MB, memcpy 从文件读取│└─► 返回 llama_model *model->layers[0].wq->data → 0x7f... (GGUF 文件内偏移)model->layers[0].wq->ne = [768, 768]model->hparams.n_layer = 8model->vocab.n_tokens = 6400llama_init_from_model(model, params)→ 创建 llama_context, KV Cache, sampler, ...llama_decode(ctx, batch)→ 第一篇第九章讲的完整推理流程
每个阶段都干净利索,没有多余步骤。这就是 GGUF + mmap + GGML 三者组合的威力——从磁盘文件到跑出第一个 token,中间没有一次完整的数据拷贝。
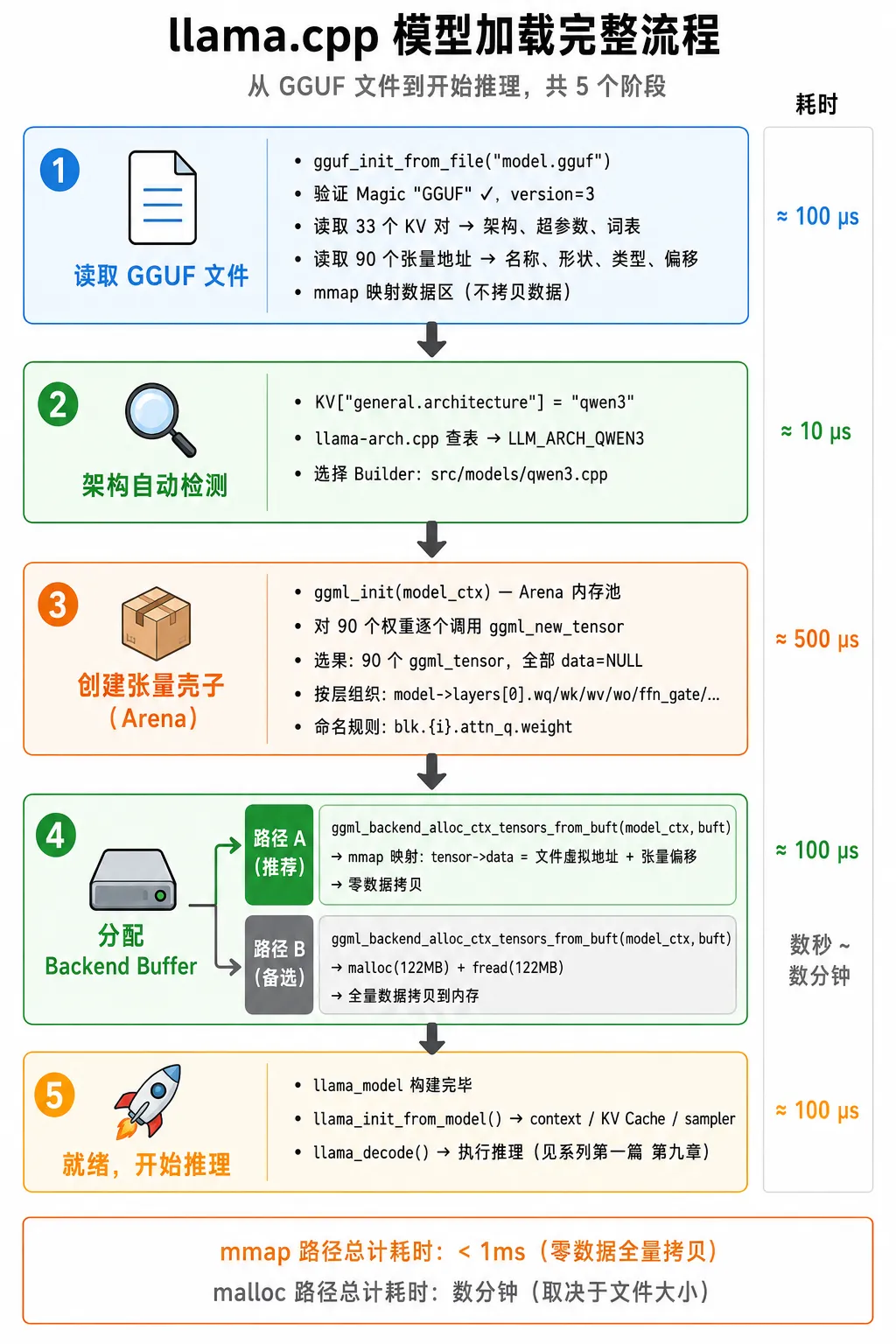
[图5:完整加载流程] — 五阶段纵向流程图,右侧标注每阶段耗时。mmap 路径总耗时 < 1ms,malloc 路径数分钟。
第七章:核心源码索引
ggml/include/gguf.h:1-31 | |
ggml/include/gguf.h:53-68 | |
ggml/src/gguf.cpp:217-228 | |
ggml/src/gguf.cpp | |
src/llama-model-loader.cpp | |
src/llama-model.cpp | |
src/llama-model.cpp:3074 | |
src/llama-model.cpp:8158-8178 | |
src/llama-arch.cpp | |
src/llama-mmap.cpp | |
convert_hf_to_gguf.py | |
docs/development/HOWTO-add-model.md |
第八章:下一篇预告
GGUF 格式和模型加载讲完了。下一篇系列第三篇:130+ 种架构的支持机制——llama.cpp 如何用一套 Builder 模式支持 LLaMA、Qwen、Mistral、Gemma、DeepSeek 等上百种架构?llama-model.cpp 这个 9666 行的最大源文件是如何组织起来的?每种架构的 build() 函数长什么样?
