 夜雨聆风
夜雨聆风昨日,Mira Murati 离开 OpenAI 后创立的 Thinking Machines Lab 发布了第一个研究预览:Interaction Models。简单说,这是一类不需要"等你说完才回话"的 AI 模型。它能边听边说,边看边讲,边搜索边回答。
而国内,早在4月9 日字节跳动也发了一个走同样方向的语音模型 Seeduplex。区别是字节没停在 demo——豆包 App 的"打电话"功能已经全量上线了 Seeduplex(豆包3月月活约 3.45 亿、DAU 约 1.4 亿,QuestMobile 数据),用户量级足够大。
Thinking Machines 这边目前只是发布技术展示,limited research preview 按官方说法还要再等几个月才放出来。
中外同步走到了同一步:让 AI 跟人对话像跟人对话,而不是像对讲机。
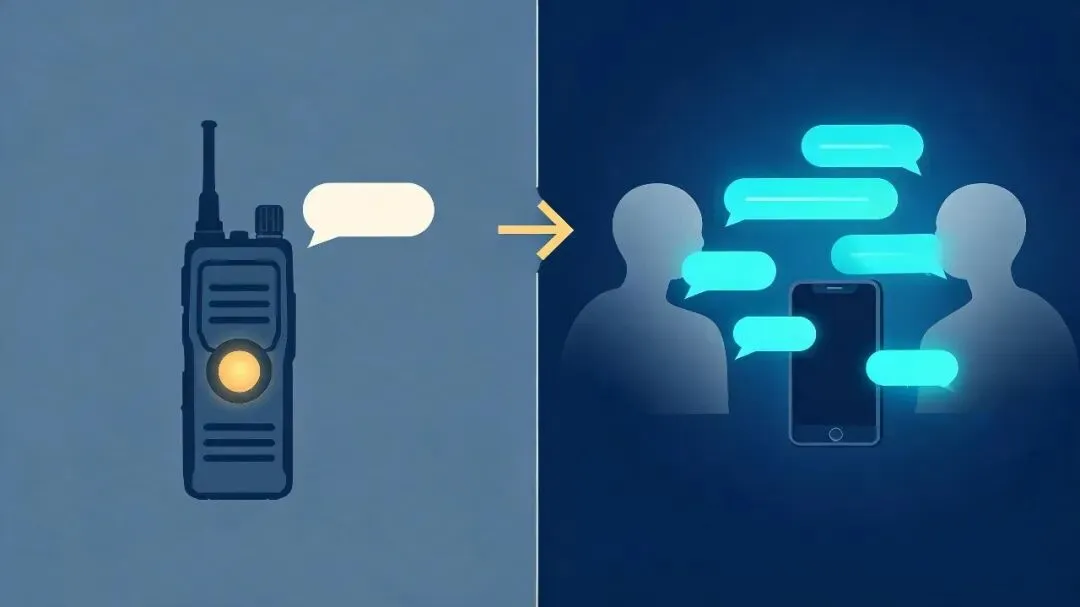
之前的AI 对话其实是"对讲机"
你按一下、说完、松开,AI 才开始回。AI 说一段、你打断、它停下、再听你说。这就是过去两年大多数主流商用 AI 语音对话的工作方式——技术上叫 turn-based,回合制。
回合制通用模型的局限:模型在每个时刻基本只做一件事——听或说,二选一。所以你看到的"实时对话 AI",背后大多是用一个外挂模块(voice activity detection,简称 VAD)做"轮次切换"——VAD 判断你说完了,模型才接管说话。VAD 判断错了,AI 就插嘴打断你,或者你说完两秒它还没反应过来。学术界其实早就有 Moshi、Seeduplex 这种全双工架构在小模型上跑,只是这次的新闻意义在"通用 frontier 模型也开始这么做"。
GPT Realtime 这一系列、Gemini live 这一系列,都是这种结构。
Thinking Machines 和字节 Seed 团队这次都做了同一件事:把"边听边说"内化到模型里,不再依赖外挂 VAD。模型从架构上就是双向的——输入流和输出流同时跑,一边接收你的音频,一边生成自己的音频。
Interaction Models 长什么样
Thinking Machines 给这套架构起了个名字:micro-turn。模型每 200 毫秒处理一段输入、生成一段输出,像两个传送带不停往两个方向走,而不是排队。
硬指标可以直接看博客里的 benchmark。同等量级的"instant"档对比:
跑分要保守看——benchmark 是发布方自己跑的,复现条件不同排序可能变化。但和同类拉开的距离不算小,等独立评测出来再看是否站得住。
模型架构上还有一个值得注意的设计:前台模型 + 后台模型分工。前台模型负责实时交互、保持节奏;遇到需要"想一会儿"的任务(写代码、查资料),交给后台模型异步跑,跑完结果再插回对话流。这样既不阻塞对话,又能用上深思考的能力。

豆包打电话已经悄悄上了一个月
字节 Seed 团队 4 月 9 日发布 Seeduplex 时给的对外口径是"原生全双工语音大模型",关键数据是:相比半双工模型,误回复率和误打断率减半,抢话比例下降 40%。
我的判断是,"误回复"和"误打断"这两个指标比延迟更接近普通用户的真实体感。延迟 0.5 秒和 0.4 秒,普通人感觉不出来;但 AI 把"嗯"听成"我说完了"提前抢话,一次就让人想关掉。
豆包升到最新版的话,在"打电话"功能里就能直接用。这是中文 AI 圈第一个在亿级日活产品里上线全双工语音的尝试,用户基数比 Thinking Machines 当前的研究预览大一个量级(功能层实际使用率没有公开数据,只能说"已具备使用条件")。
国内已经能在产品里用、国外刚发布技术展示公告——这种节奏在中文 AI 圈不算常见。
这意味着普通用户接下来能用 AI 做什么
把"边听边说"这件事翻译成普通人的体感,可以列出几个具体场景。其中纯语音类的一部分(实时翻译、不抢话的对话)豆包"打电话"已经在路上;涉及视觉、屏幕理解、复杂工具调用的,要等 Thinking Machines 这种多模态架构真正落地到产品才能用:
最自然的落地方向其实是耳机和车机——这两个场景里"先按按钮再说话"的成本最高。

豆包已经在打电话上跑了 Seeduplex 一个月,下一步合理的方向是搬到通用对话和 IDE 助手;其他大厂的语音助手在合适时机也会切到全双工架构,但具体时间还要看各家自己节奏。在豆包这类全双工语音产品上,国内用户的体验确实跑在了英文市场前面(Realtime API 类产品架构不同,不能直接横比)。
至于 GPT Realtime 怎么应对,可以等 OpenAI 自己的下一波更新。
